In this article, I will introduce NoSQL concepts and show how they are related to Elasticsearch, and we will consider this search engine as a NoSQL document store.

What is Elasticsearch?
Elasticsearch is a search engine that is written in Java and works well out of the box.
This search engine was created by Shay Banon, who wrote some of his developments for integrating search into applications written in Java. At some point, he realized that to create a scalable search solution he needed to rewrite a significant part of his developments. So he created “a solution built from the ground up to be distributed” and used a common interface, JSON over HTTP, suitable for programming languages other than Java as well. As a result, the first version of Elasticsearch was released in February 2010. Elasticsearch based on Apache Lucene. Often used with components such as Logstash — a tool for sending data to Elasticsearch and Kibana (a user interface for searching, viewing data, and, visualizations).
Use cases:
Log processing and analytics
Processing events and metrics
Full-text search
Business Intelligence
Security Audit (SIEM)
Application performance monitoring (AWP)
Average relational DBMS

For a deeper understanding of how a DBMS works from the inside, I recommend reading a very good book written by Joseph M. Hellerstein, Michael Stonebraker, and James Hamilton — Architecture of a Database System (Foundations and Trends(r) in Databases). So, what does a DBMS consist of? First of all, inside, the main component is the Transactional Storage Manager. This is the library or the service that is directly involved in saving data to disk. The data can be different, such as table data, logs, and different intermediate data. And this storage manager implements transactionality in relational DBMSs that implement the ACID principles.
The next important component is the Query Processor or Relational Query Processor. It implements a query plan for a query that came to it, based on knowledge of table abstraction, the physical data model. If it’s a simple insert, then the query plan will be pretty simple. But if it is, for example, a select with plenty of joins, a mass update, or a mass delete, then this query can be very complex. The strategies of joins are different: joins have different execution orders, the DBMS can rewrite the query by changing the execution order of joins. And this component is one of the most complex, in terms of lines of code that lie in its implementation.
The next component is communication with the client (Client Communication Manager), which includes authorization and authentication from the client side.
The next component is Process Management. Because other blocks create either threads or UNIX processes running on this system. They need to be managed and planned.
Then comes Shared Components and Utilities, various additional components, such as catalog manager, memory manager, a million utilities, services for replication and loading, and so on.
Let’s see what complex technical challenges we can face when working with a such DBMS. For example, we have a task, - we need to make this system scalable, we need to make it so that we can add more servers, and everything we are used to would continue to work. And we immediately run into some complex technical problems.
Scalability
Firstly, how to ensure database integrity. This is the most important issue in any data management system — maintaining database integrity.
Secondly, how to ensure parallelism. For example, we have a very big select query. We can figure out how to do it on one server. But how can we make sure that different parts of the tables are placed on different servers, and at the same time we can make queries to them in parallel?
It’s quite complex. And so the database developers of NoSQL DBMSes made compromises.
The first thing they did was to bring the Referential integrity mechanism to the application side, so we say that we do not have referential integrity between tables. We don’t have various cascading deletes. It’s all on the application side. The application itself must take care of this, either denormalizing the data, using a denormalized schema, or dealing with database integrity checking.
The next part is the data model. It is quite complex, we have many different database data types, and we can have various additional secondary indexes, various types of indexes, materialized views, and so on. And it was decided to bring all this to the side of the application. Literally, before the fact that the first DBMS, was non-relational, they did not require data models at all, that is, they simply stored an array of bytes, they did not know what type of data, and what attributes were stored in them.
- Can Elasticsearch be considered a NoSQL database?
- Of course yes!
But it depending on how to understand NoSQL. If you go and open the Wikipedia page “NoSQL”, or look at the talks on this subject, then of course NoSQL stands for not only a sequel. But this isn’t about SQL.
What is NoSQL
This definition is taken from the nosql-database.org website:
Next-Generation Database Management Systems mostly address some of the points: being non-relational, distributed, open-source, and horizontally scalable.
Originally it was a need for systems that have a specific feature, such as managing data at a web scale, but since the beginning of 2009, everything began to change, and other significant characteristics appeared:
Schema-free
Easy replication support
Simple API
Eventually consistent / BASE (not ACID)
Huge amount of data
That’s why the community translates the term NoSQL as “not only SQL”.
NoSQL database classification
NoSQL Databases are mainly categorized into four types:
Key-value pair (In-memory firsts: Redis, Aerospike, Persistent first: Riak, Dynamo, Oracle NoSQL Database)
Column-oriented (Google BigTable, Apache HBase, Amazon DynamoDB, Apache Cassandra)
Graph-based (Neo4j, Titan)
Document-oriented (MongoDB, Couchbase, Full-text search: Elasticsearch, Apache Solr)
Every category has unique attributes and limitations. None of the above-specified databases is better to solve all the problems.
Elasticsearch concepts

Cluster
Node
Document
Index
Mapping
Shards
Replicas
Segments
Cluster. An Elasticsearch cluster is comprised of one or more Elasticsearch nodes, which is an analog of a table in a relational database.
Node. An instance of Elasticsearch.
Document. A unit of information that can be indexed.
Index. Each document in Elasticsearch is stored in an index. The index groups documents logically and also provides configuration options that are related to scalability and availability.
Mapping. Like a schema in the world of relational databases, the mapping defines the different types that reside within an index. We have an index where all the data is stored. And there is a mapping where all the meta-information on the index is stored. What structure, what validators, what data types, how it will store and index them.
Shards. All indices are subdivided into small pieces called shards. Each shard in itself is a full-fledged, independent Lucene index, which can be located on any node of the cluster. Put simply, shards are a single Lucene index.
Replicas. Replicas, as the name suggests, are Elasticsearch fail-safe mechanisms and are copies of your index’s shards.
Segments. Each shard contains multiple “segments”, where a segment is an inverted index. A search in a shard will search each segment in turn, then combine their results into the final results for that shard. Queries are parallelized across index shards, which improves search performance and throughput.
Now that you know the basic concepts, let’s look at the main features.
Horizontal Scaling
At the beginning of the article it was mentioned that “Elasticsearch is a search engine which is written in Java and works well out of the box”.
See how easy it is to run one Elasticsearch instance:
elasticsearch -Enode.name=node-1 -Epath.data=./node-1/data -Epath.logs=./node-1/logsAnd add index books:
PUT /books
{
"settings": {
"number_of_shards": 3,
"number_of_replicas": 1
}
}After a command execution, the cluster will look like this:

GET /_cat/nodes?v
Let’s add the second node to the cluster:
elasticsearch -Enode.name=node-2 -Epath.data=./node-2/data -Epath.logs=./node-2/logsCheck information about index shards:
GET /_cat/nodes?v
A new node has been added to the cluster and all replicas have been transferred to the added node.
Let’s add the third node to the cluster:
elasticsearch -Enode.name=node-3 -Epath.data=./node-3/data -Epath.logs=./node-3/logs
Check information about index shards:
GET /_cat/shards?pretty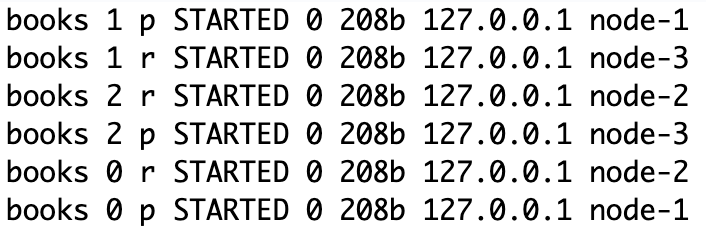
GET /_cat/nodes?vElasticsearch spread shards in the nodes throughout the cluster in automatic mode.
Transactions
We know that under the hood Elasticsearch uses Apache Lucene and it has the concept of transactions. Elasticsearch does not have the concept of transactions in the usual sense of the word. If you have submitted a document, rollback is no longer possible.
Elasticsearch has a write-ahead log to ensure the reliability of saving documents without having to commit on the Apache Lucene side because this is an expensive operation.
Elasticsearch can specify the consistency level of index operations in terms of the number of replicas that must confirm the operation before returning a response to the client. The default is a quorum, which is [n/2] + 1.
The visibility of changes is controlled by updating the index, which by default is done once per second and is done on a per-shard basis.
Optimistic concurrency control is done by specifying the version of submitted documents.
Here it must be said that Elasticsearch is made for fast search, and performing distributed transactions is a quite complex job, if they are missing, then everything becomes much easier.
Translog
Translog is short for “transaction log”. All Elasticsearch operations are saved here as they occur.
The three green items are a collection of Apache Lucene segments. Segments are inverted indexes, but an index in Lucene is called a set of segments and a commit point is a file that lists all known segments.
When a document is indexed, it is added to the in-memory buffer and appended to the translog, as shown in
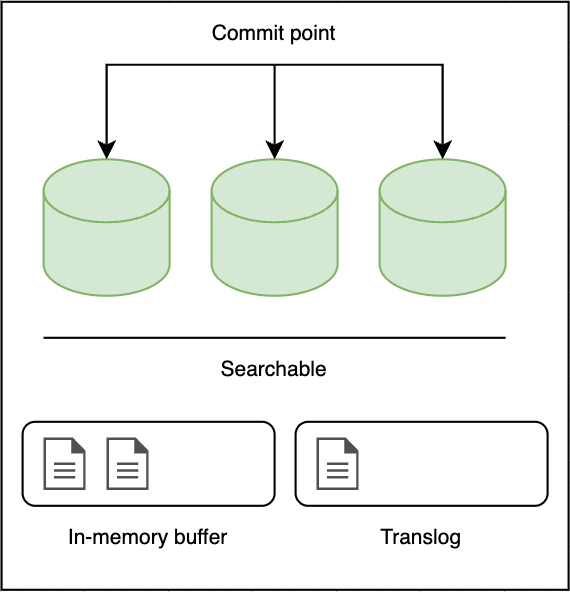
Every second, the shard is refreshed:
The docs in the in-memory buffer are written to a new segment, without a fsync.
The segment is opened to make it visible to search.
The in-memory buffer is cleared.
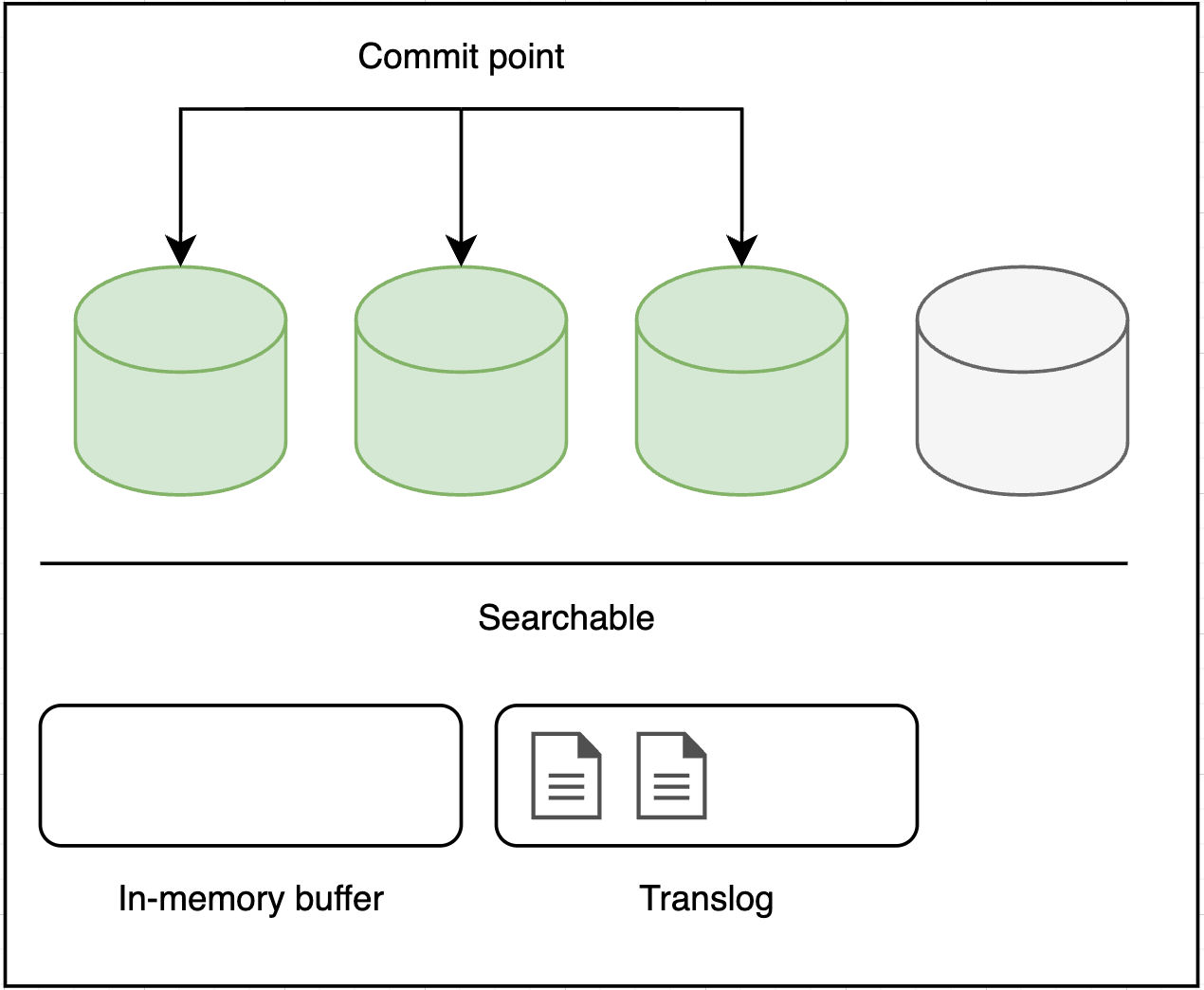
This process continues with more documents being added to the in-memory buffer and appended to the transaction log.

When the translog is getting too big — the index is flushed; a new translog is created, and a full commit is performed:
Any docs in the in-memory buffer are written to a new segment.
The buffer is cleared.
A commit point is written to disk.
The filesystem cache is flushed with a fsync.
The old translog is deleted.

Elasticsearch relies on the OS file system cache to cache I/O operations, so we can load documents into the operating system cache when we open an index, and use Elasticsearch as a cache.
Commit points are used to restore data from the disk when Elasticsearch is started.
Translog is used to provide real-time CRUD operations. When you try to query a document or delete a document by ID, Elasticsearch first checks the translog for the latest changes instead of getting the document from the relevant segment.
Optimistic concurrency control
Consider an example of optimistic concurrency control:
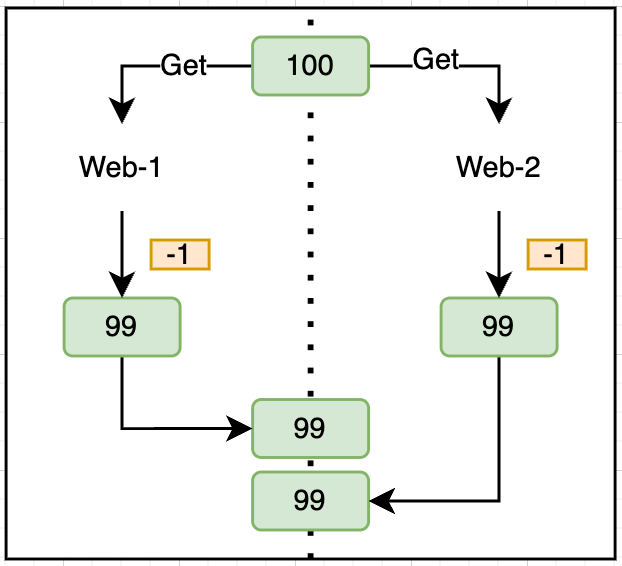
How to prevent an older version of a document from being overwritten by an older one if the write operations arrive out of order?
The current versioning approach is using primary_term and sequence_number:
{
"_index" : "books",
"_type" : "_doc",
"_id" : "100",
"_version" : 3,
"_seq_no" : 7,
"_primary_term" : 1,
"found" : true,
"_source" : {
...
}
}When we retrieve a document, the current primary_term and sequence_number are included in the result. The if_seq_no and if_primary_term parameters are added to the POST request:
POST /books/_update/100/?if_primary_term=1&if_seq_no=5
{
"doc": {
"price": 3
}
}After a request is sent, Elasticsearch will use these two values to ensure that the document is not modified if there is a more recent version of it or will throw an exception to the client side.
Dynamic Schema
NoSQL databases do not require a schema and are not required to have relationships between tables. In Elasticsearch, documents are JSON documents in an easily readable and understandable format.
A predefined schema isn’t required to be defined
Type inference while saving a document
The default analyzer is using
Mapping
Mapping is the process of defining how a document, and the fields it contains, are stored and indexed.
Explicit mapping (before 7.0.0) defines the type of fields yourself
Dynamic mapping Elasticsearch generates field mapping for us
There are restrictions on field mapping:
After mapping is processed, the text values are already analyzed.
Changes between data types require the entire data structure to be changed.
For an empty index, the mapping cannot be updated.
Mappings for fields cannot be deleted once added.
Usually, Reindex API is used to index documents into a new index.
HBase Schema

We see what rowkey is in HBase. In this case, it is a short link. Rows in HBase are sorted lexicographically according to the row key. This design is optimized for scans, it allows you to store “connected” rows, or rows that can be read together, near to each other. Bad row key design is a problem called the hot region. The hot region happens when huge client traffic goes to one node or several among the entire cluster. This traffic can be read, write, or other operations. Such traffic overloads the server, which can lead not only to a decrease in the performance of a part of the server but possibly to the unavailability of the server. It can also affect other servers that are hosted on the same machine, so it is important to design data access in such a way that the cluster is used fully and evenly.
Instead of the concept of rowkey, Elasticsearch operates with the concept of a shard.
Routing
When you index a document, it is stored on the primary shard. How does Elasticsearch understand which shard a document belongs to?
A shard is determined by the following formula:
shard = hash(routing) % number_of_primary_shards
The routing parameter here is an arbitrary value of type “string”. By default, this is _id, but it can also be a custom value. This formula answers the question of why the number of primary shards cannot be changed. Because we won’t be able to find the documents later.
Distributed Computing
Here, to understand how distributed computing works, I propose to understand how indexing and retrieval of documents take place.
Creating, Indexing, and Deleting a Document
Create, index, and delete requests are write operations, which must be completed on the primary shard before they can be copied to any associated replica shards.

The client sends a create, index, or delete request to Node1.
The node uses the document’s _id to determine that the document belongs to shard0. It forwards the request to Node3, where the primary copy of shard0 is currently allocated.
Node3 executes the request on the primary shard. If it is successful, it forwards the request in parallel to the replica shards on Node1 and Node2. Once all of the replica shards report success, Node3 reports success to the requesting node, which reports success to the client.
Distributed search
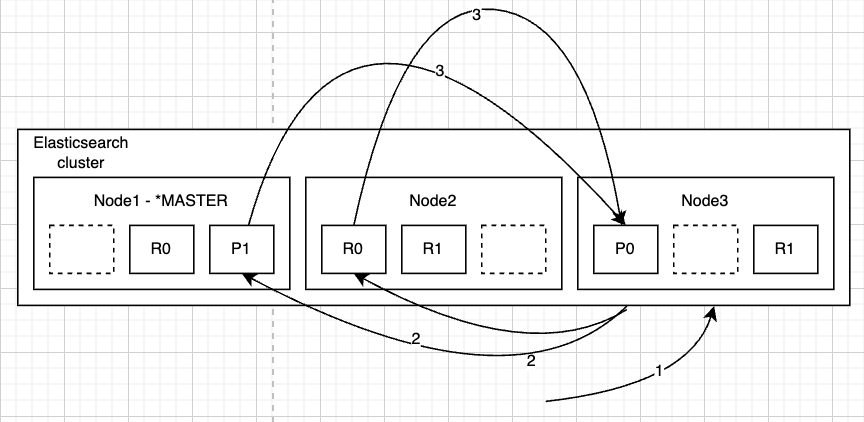
The query phase consists of the following three steps:
The client sends a search request to Node 3, which creates an empty priority queue of size from + size.
Node3 forwards the search request to a primary or replica copy of every shard in the index. Each shard executes the query locally and adds the results into a locally sorted priority queue of size from + size.
Each shard returns the doc IDs and sort values of all the docs in its priority queue to the coordinating node, Node3, which merges these values into its priority queue to produce a globally sorted list of results.
A priority queue here is just a sorted list that holds the top-n matching documents.
When a search request is sent to a node, that node becomes the coordinating node. The task of this node is to broadcast a search request to all involved shards to get answers from them, create a search result and send it to the client.
This happens when a GET document is requested when the node understands by the document id that the document belongs to shard0, a copy of shard0 located on three nodes, and the request can be redirected to one of them by round-robin. That is, the search request can be processed by the primary shard or their replicas. This is why adding more replicas can increase search throughput. The coordination node will use the round-robin algorithm to iterate over all replica shards on subsequent requests to distribute the load.
Why it is done that way? This is done to distribute the load because the process of assembling the result can be quite resource-intensive. Other nodes read from the disk, and the third takes on the role of data scoring load.
Joins and Restrictions
Elasticsearch is a document-oriented NoSQL database. The entire object documents graph you need to search needs to be indexed, so the documents need to be denormalized before indexing. Denormalization improves search performance. But this has the drawback that more space is required (we have to store document relationships) and therefore maintaining a consistent state becomes more complex (because any changes must be applied to all documents), but for write-once-read-many-workloads it’s good!
Joining Queries
If in a relational DBMS, you need to change some field to which the data is bound, you simply update it, in a document-oriented database you will need to rebuild each document that contains this field, in Elasticsearch you change the mapping, and reindex documents.
Nested queries
Because nested objects are indexed as separate hidden documents, we can’t query them directly.
PUT /books/_mapping
{
"properties": {
"reviews": {
"type": "nested"
}
}
}
POST /books/_doc/1
{
"reviews": [
{
"rating": 5.0,
"comment": "Hilarious and touching. fun for the whole family.",
"author": {
"first_name": "John",
"last_name": "Doe",
"email": "john@doe.com"
}
},
{
"rating": 4.0,
"comment": "Pride and Prejudice has always been one of my favorite books.",
"author": {
"first_name": "John",
"last_name": "Smith",
"email": "smith@john.com"
}
}
]
}Instead, we have to use the nested query:
GET /books/_search
{
"query": {
"nested" : {
"path" : "reviews",
"query" : {
"bool" : {
"must" : [ { "match" : {"reviews.rating" : 5.0} } ]
}
}
}
}
}Joins - has-parent, has-child
Let’s add documents:
PUT /books
{
"mappings": {
"properties" : {
"join_field" : {
"type" : "join",
"relations": {
"books": "author"
}
}
}
}
}
PUT /books/_doc/1
{
"author": "Harper Lee",
"join_field": "books"
}
PUT /books/_doc/2
{
"author": "Jane Austen",
"join_field": "books"
}
PUT /books/_doc/3?routing=1
{
"title": "To Kill a Mockingbird",
"price": 20,
"in_stock": 5,
"join_field": {
"name": "author",
"parent": 1
}
}
PUT /books/_doc/4?routing=2
{
"title": "Pride and Prejudice",
"price": 20,
"in_stock": 5,
"join_field": {
"name": "author",
"parent": 2
}
}All that is needed to establish the parent-child relationship is to specify which document type should be the parent of a child type.
With the queries list, we can query documents by parent or child:
# has parent
GET /books/_search
{
"query": {
"has_parent": {
"parent_type": "books",
"query": {
"term": {
"author.keyword": "Jane Austen"
}
}
}
}
}
# has child
GET /books/_search
{
"query": {
"has_child": {
"type": "author",
"query": {
"bool": {
"should": [ { "term": { "title.keyword": "To Kill a Mockingbird" } } ]
}
}
}
}
}There are no joins in HBase either, but if you have dashboards that have a fixed query that probably uses some predefined aggregation, filtering, and joins, then you are most likely using Apache Kylin. Or Apache Phoenix, which can do a good subset of SQL, but since it works as a driver, it can’t do distributed joins.
Reliability
Any database needs to be reliable, ideally if you can cancel an expensive query, and at the same time, we need the database to be able to work. Here Elasticsearch, unfortunately, can’t handle OutOfMemory errors quite well, as it claims to be designed for fast searching and it is assumed that there is enough memory.
CAP-theorem
Elasticsearch is a CP system where maintaining consistency under certain conditions can be a weak point.
If we have a read-only load and this is the main load, then we can achieve AP behavior if we don’t wait for acknowledgment from a larger number of master nodes, then we will need most of the nodes to be available.
Writing to an incorrectly configured cluster without confirmation from most nodes, when writing to the same key on different processes can lead to different parts of the cluster, can lead to a situation called “split-brain” and we can lose data, by default it is a quorum. But there are other possible values.
In terms of scaling, the index is divided into one or more shards. This is specified when the index is created and cannot be changed. As additional nodes are added to the cluster, Elasticsearch does a good job of moving shards, therefore Elasticsearch is easy to scale.
Conclusion
We have considered Elasticsearch as a document store in terms of the following concepts:
Horizontal Scaling
Transactions (the lack of them)
Dynamic Schema
Joins and Restrictions
Reliability
Distributed Computing
