Привет вам, хабрачеловеки.
Думаю все тем или иным образом осведомлены о недавнем выходе Windows Server 2008 R2 с модернизированной реализацией Hyper-V. Основным нововведением, относительно обычного 2008-го Hyper-V, заявляется поддержка функции Live Migration для переноса виртуальных машин между нодами кластера в реальном времени. Разумеется, для демонстрации этой функции, нам понадобится внешнее хранилище данных и кластер… а лишний SAN в кладовке обычно не валяется.

В данной заметке я расскажу как реализовать полноценный кластер Hyper-V 2008 R2 на подручном железе — трех рабочих станциях, две из которых поддерживают аппаратную виртуализацию. Под катом инструкция по сборке отказоустойчивого кластера Hyper-V с учетом нюансов и особенностей, а так же видео-демонстрация технологии Live Migration.

Краткий экскурс по самой технологии Live Migration. Ее основное отличие от Quick Migration — перенос виртуальной машины «на лету», без выгрузки памяти на диск (это иллюстрирует предыдущая картинка). Помимо этого, по заверениям Microsoft, перенос машины происходит быстрее, чем успевает разорваться TCP-сессия, так что пользователи если и будут испытывать дискомфорт, то небольшой.
У меня, разумеется, нет лишнего SAN-а для тестирования.
Все что у меня есть — две рабочих станции Aquarius (C2D 6420, 4Gb DDR2, 80Gb HDD) и одна станция на Celeron-D.
Разумеется все процессоры должны иметь поддержку 64бит, так как 2008 R2 существует только в 64-битной редакции.

Для реализации кластера, я возьму бесплатный вариант Hyper-V Server 2008 R2, который представляет собой модифицированный Windows Server 2008 R2 в режиме ядра, со включенным по-умолчанию гипервизором и относительно удобной консольной менюшкой для централизованного управления. Выбор обусловлен тем, что я не хочу, тратить ресурсы хостовой машины на поддержание каких-либо других ролей кроме гипервизора.

В случае использования данного гипервизора, лицензироваться будут только виртуальные машины, которые мы будем на нем крутить. Я это говорю на случай, если кому-то взбредет в голову внедрять данную кустарную систему в продакшн.
В качестве хранилища я буду использовать самую слабую из своих рабочих станций, закинув в нее пару жестких дисков на 250гб каждый и объединив их в софтверный RAID0 силами операционной системы. Для превращения импровизированного сервера в хранилище, я буду использовать самый дешевый из возможных вариантов — iSCSI. Эта же машина будет выступать в качестве управляющей для кластера Hyper-V, ну и заодно будет контроллером нашего маленького домена.
Существует несколько реализаций iSCSI для Windows. Две самые распространенные:
Наше импровизированное хранилище будет работать под управлением полноценного Windows Server 2008 R2, версия в данном случае существенного значения не имеет, однако опытным путем выяснилось, что управление кластером с 32-битных систем может вызывать некоторые проблемы. Тем более, что в 2008 R2 стоит свежая консоль Failover Clustering, а в других версиях придется обновлять Remote Administration Tools. Ну и не стоит забывать, что машина будет выполнять также функции контроллера домена.
Итак, у нас есть два чистых и ненастроенных Hyper-V Server 2008 R2, и один чистый Windows Server 2008 R2.
Перед настройкой кластера, необходимо настроить сетевую инфраструктуру для корректной работы. Задаем всем серверам локальные IP-адреса, предварительно подцепив их в маленький свитч(типа того, что у меня на фотке). Разрешаем удаленный доступ к нодам, как через RDP, так и через консоль MMC.
Лучше сделать это до того, как ноды окажутся в домене. Были ситуации, когда сервер ругался на невозможность изменения политик фаервола. Поднимаем домен и вводим в него наши будущие кластерные ноды.
Разумеется, включаем Failover Clustering Feature.
Теперь можно перейти непосредственно к настройке хранилища. Начнем с того, что разобьем наш получившийся страйп (RAID0) на два логических диска — один для кворума (который ныне зовется File Share Witness), а второй для хранения наших виртуальных машин. Я выделил под кворум около 15Гб, а все остальное оставил под данные. По-хорошему — под кворум с лихвой хватит и гигабайта, однако мало ли что.
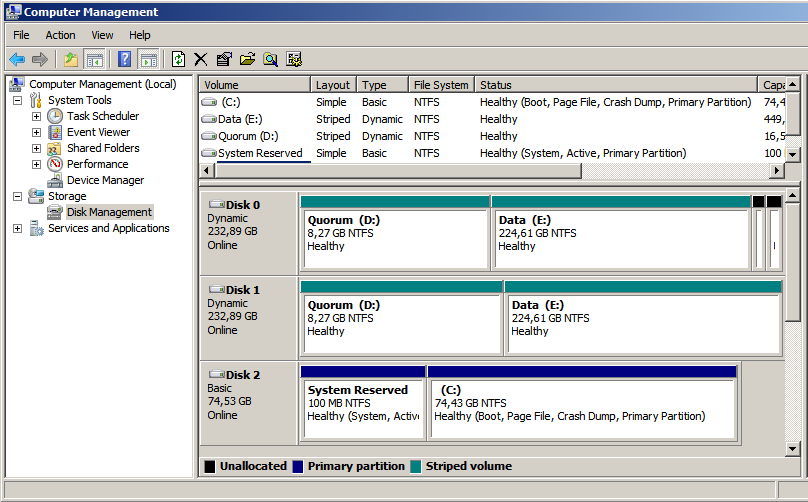
Переходим к установке StarWind iSCSI Target. Для загрузки с сайта производителя потребуется регистрация, которая ни к чему, в принципе, не обязывает. После регистрации, на электронную почту падает ссылка на прямую загрузку инсталлятора и файл-ключ с лицензией. Установка состоит из нескольких нажатий на кнопку Next, так что ничего существенно сложного там нет. После установки необходимо пропустить через Windows Firewall как минимум порты 3260 и 3261. Для ленивых — его можно просто отключить, так как в нашей импровизированной сети находятся только три наших сервера.
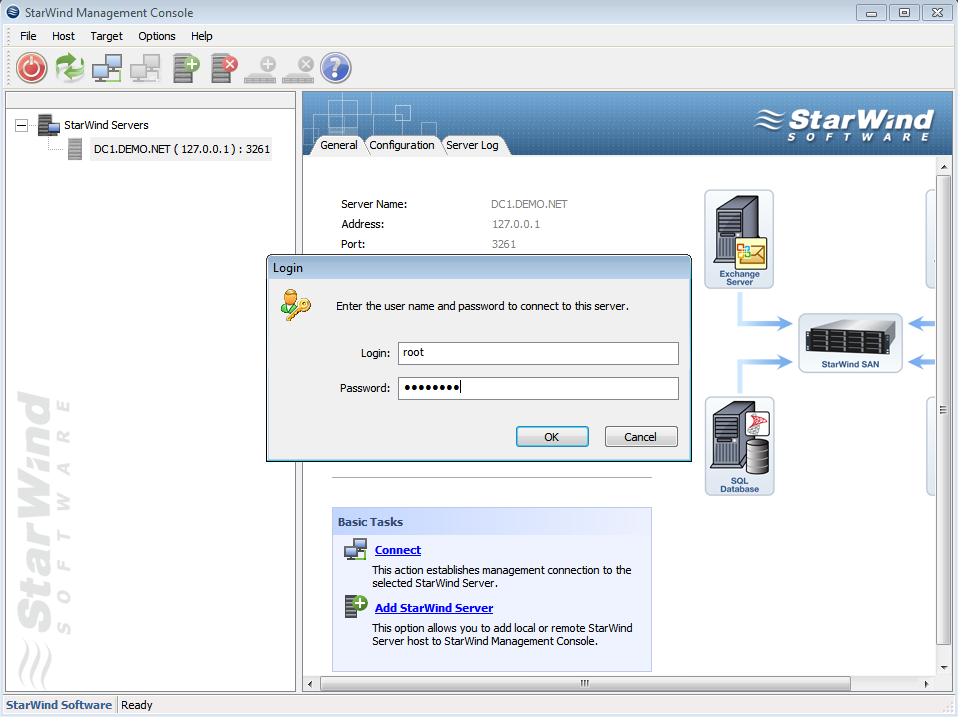
Запускаем консоль StarWind и пробуем подключиться к iSCSI-серверу, коим в нашем случае выступает компьютер с таинственным адресом 127.0.0.1. Для авторизации потребуется секретное сочетание дефолтного логина и пароля, которые в базовом варианте выглядят как root и starwind соответственно. Почему не просили задать пароль в процессе установки, или не повесили подсказку в интерфейсе — загадка.
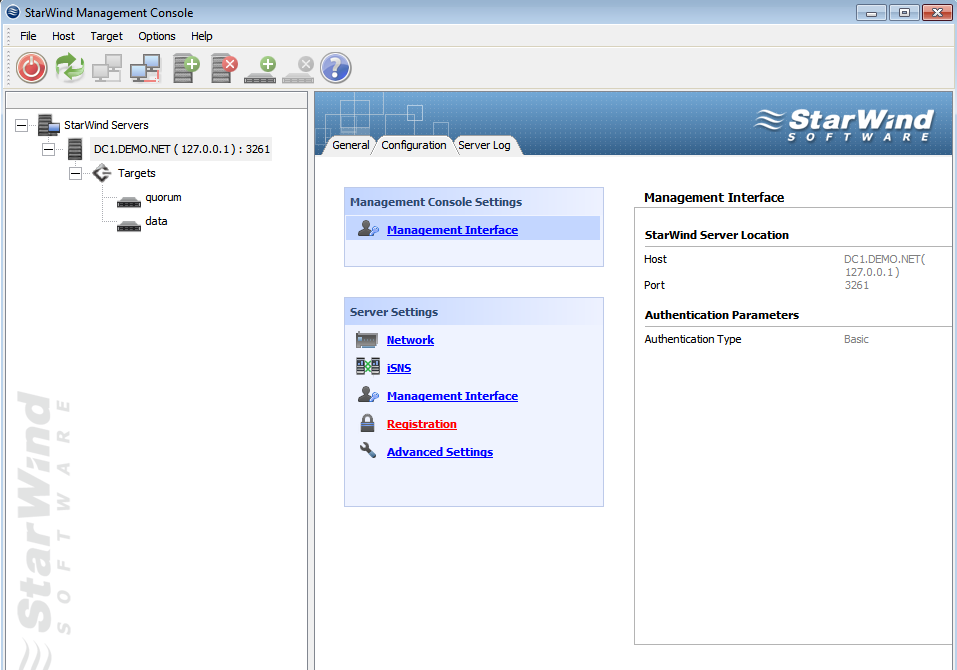
После подключения к серверу, необходимо подсунуть ему файл с лицензией, упавший на электронную почту. Делается это во вкладке Configuration, серверной консоли StarWind. Все интуитивно понятно и просто, за исключением ссылки на загрузку самого файла в верхнем правом углу. Только после регистрации, программа позволит нам создавать таргеты.
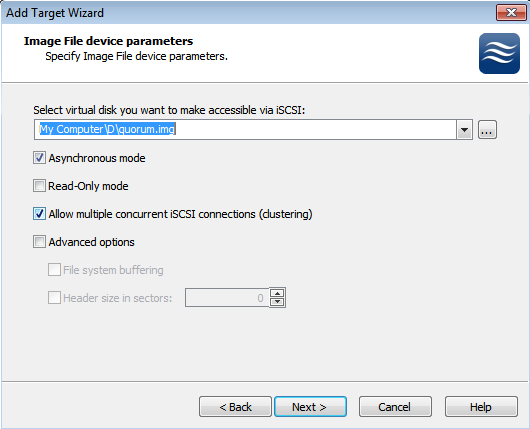
В процессе создания таргета, мы создаем предразмеченные img-файлы, которые будут играть роль наших LUN-ов. Размещаем их на наших разделах в соответствии с целями, и не забываем выставлять галочку, отвечающую за конкурентные соединения iSCSI(т.е. кластеризацию). Можно также задать кэширование данных, это будет полезно в случае использования нашего медленного железа.

В результате, должна получиться примерно следующая картина. Два таргета — один под кворум, второй под данные. Пора подцеплять их к серверам.
В серверах версии 2008 R2 уже есть предустановленный iSCSI Initiator, отвечающий за подключение LUN-ов с нашего импровизированного хранилища, в качестве локальных дисков. Правда в связи с отсутствием адекватного GUI на консольном Hyper-V Server, его придется вызывать через командную строку или Powershell командой iscsicpl.
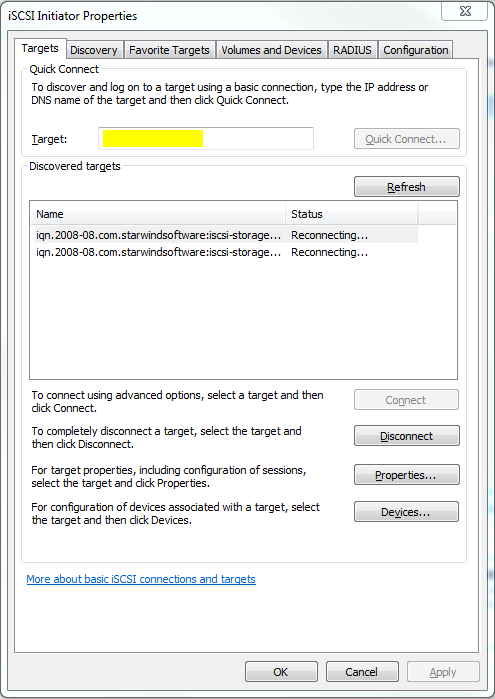
В поле, подсвеченное желтым нужно ввести IP-адрес нашего хранилища, после чего должно появиться всплывающее окошко с размещенными на сервере таргетами. Разумеется, если фаервол был правильно настроен или отключен. После того как таргеты будут подключены к нашему серверу, можно будет заняться монтированием их в качестве дисков.

После нажатия на Autoconfigure, в пустом окошке появятся два длинных пути к дискам, начинающимся на \?\. После этого, можно смело идти в Disk Management и задавать буквы дискам. К слову, после задания букв на первом гипервизоре, второй гипервизор подхватит имена дисков автоматически.
В результате мы получили два гипервизора, имеющих по два общих диска, подключенных через iSCSI к нашему хранилищу. Пора переходить непосредственно к кластеризации.
При настройке отказоустойчивого кластера на двух имеющихся гипервизорах, визард сам выбрал файловые разделы под кворум и под данные. Если я правильно понял алгоритм, в качестве общих ресурсов были выбраны диски, подключенные по iSCSI, и в качестве кворума был выбран наименьший. А может он выбрал их потому, что меньшему разделу я дал лейбл Quorum… =)

После объединения двух гипервизоров в кластер, с помощью визарда и такой-то матери, консоль отказоустойчивого кластера будет выглядеть примерно так, как на картинке сверху. Стоит заметить, что в данный момент мы имеем именно отказоустойчивый кластер, в котором всю работу выполняет только одна нода, а вторая в это время простаивает и ждет пока первая сдохнет. Но нам же нужно не это.

Тут нам поможет Cluster Shared Volumes — новая вкладка в консоли кластера, появившаяся только в 2008 R2. Именно на этом хранилище могут размещаться виртуальные машины, для обеспечения отказоустойчивости. Наша задача — превратить обычный кластерный ресурс в расшареный, используя волшебную кнопку «Add Storage». После предупреждения о том, что данный тип ресурсов работает только в версиях 2008 R2 и выше, во вкладке совместно используемых ресурсов появится наш диск. Диск, в свою очередь будет смонтирован на C:\ClusterStorage\Volume1, так что все совместно используемые данные будут находиться там. В том числе и виртуальные машины. Во избежание лишних глюков, в настройках гипервизоров на каждой ноде, советую выставить дефолтные пути для дисков и виртуальных машин, с размещением на нашем общем диске.
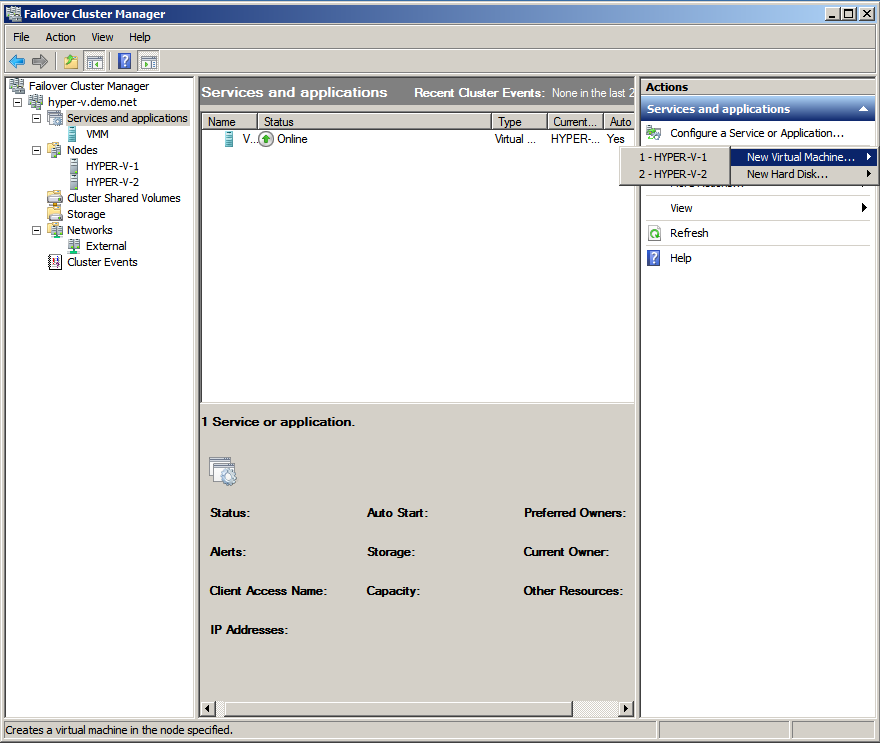
Теперь можно создавать виртуальные машины непосредственно из оснастки управления кластером. Во вкладке сервисов выбираем Virtual Machines, выбираем ноду и создаем машину. Монтируем откуда-нибудь дистрибутив с ОС, устанавливаем и отмонтируем. Для корректной работы Live Migration, необходимо отсутствие зависимостей от внешних ресурсов на каждой ноде.
На видео показан процесс перегонки памяти с одной ноды на другую. На переносимой виртуальной машине стоял тот же Windows Server 2008 R2, а памяти у машины было 1024мб. Сразу стоит отметить весьма посредственную скорость миграции, которая связана с кустарной реализацией нашего хранилища и сетью в 100мбит. Позднее пересоберу кластер с использованием гигабитной сети и посмотрю на прирост производительности.
Надеюсь, статья окажется для кого-нибудь полезной. Эксперементируйте!
Думаю все тем или иным образом осведомлены о недавнем выходе Windows Server 2008 R2 с модернизированной реализацией Hyper-V. Основным нововведением, относительно обычного 2008-го Hyper-V, заявляется поддержка функции Live Migration для переноса виртуальных машин между нодами кластера в реальном времени. Разумеется, для демонстрации этой функции, нам понадобится внешнее хранилище данных и кластер… а лишний SAN в кладовке обычно не валяется.
В данной заметке я расскажу как реализовать полноценный кластер Hyper-V 2008 R2 на подручном железе — трех рабочих станциях, две из которых поддерживают аппаратную виртуализацию. Под катом инструкция по сборке отказоустойчивого кластера Hyper-V с учетом нюансов и особенностей, а так же видео-демонстрация технологии Live Migration.
Введение
Краткий экскурс по самой технологии Live Migration. Ее основное отличие от Quick Migration — перенос виртуальной машины «на лету», без выгрузки памяти на диск (это иллюстрирует предыдущая картинка). Помимо этого, по заверениям Microsoft, перенос машины происходит быстрее, чем успевает разорваться TCP-сессия, так что пользователи если и будут испытывать дискомфорт, то небольшой.
Выбор железа и софта
У меня, разумеется, нет лишнего SAN-а для тестирования.
Все что у меня есть — две рабочих станции Aquarius (C2D 6420, 4Gb DDR2, 80Gb HDD) и одна станция на Celeron-D.
Разумеется все процессоры должны иметь поддержку 64бит, так как 2008 R2 существует только в 64-битной редакции.
Для реализации кластера, я возьму бесплатный вариант Hyper-V Server 2008 R2, который представляет собой модифицированный Windows Server 2008 R2 в режиме ядра, со включенным по-умолчанию гипервизором и относительно удобной консольной менюшкой для централизованного управления. Выбор обусловлен тем, что я не хочу, тратить ресурсы хостовой машины на поддержание каких-либо других ролей кроме гипервизора.
В случае использования данного гипервизора, лицензироваться будут только виртуальные машины, которые мы будем на нем крутить. Я это говорю на случай, если кому-то взбредет в голову внедрять данную кустарную систему в продакшн.
В качестве хранилища я буду использовать самую слабую из своих рабочих станций, закинув в нее пару жестких дисков на 250гб каждый и объединив их в софтверный RAID0 силами операционной системы. Для превращения импровизированного сервера в хранилище, я буду использовать самый дешевый из возможных вариантов — iSCSI. Эта же машина будет выступать в качестве управляющей для кластера Hyper-V, ну и заодно будет контроллером нашего маленького домена.
Существует несколько реализаций iSCSI для Windows. Две самые распространенные:
- Microsoft iSCSI Software Target — поставляется только в паре с Windows Storage Server 2008, при покупке серверов у OEM-партнеров Microsoft. Найти ее в открытом доступе не так легко, но если кто найдет — может попробовать. Правда ставится она опять же, исключительно на Storage Server, который не сильно подходит для наших нужд.
- StarWind iSCSI Software Target — продукт компании StarWind(имеющей совершенно непопулярный блог на Хабре) с поддержкой русского языка. У StarWind есть бесплатная версия, ограниченная в объеме хранилища до 2Тб, и двух конкурентных соединений к одному таргету. А нам для проверки больше и не надо.
Наше импровизированное хранилище будет работать под управлением полноценного Windows Server 2008 R2, версия в данном случае существенного значения не имеет, однако опытным путем выяснилось, что управление кластером с 32-битных систем может вызывать некоторые проблемы. Тем более, что в 2008 R2 стоит свежая консоль Failover Clustering, а в других версиях придется обновлять Remote Administration Tools. Ну и не стоит забывать, что машина будет выполнять также функции контроллера домена.
Настройка
Этап первый. Предварительный
Итак, у нас есть два чистых и ненастроенных Hyper-V Server 2008 R2, и один чистый Windows Server 2008 R2.
Перед настройкой кластера, необходимо настроить сетевую инфраструктуру для корректной работы. Задаем всем серверам локальные IP-адреса, предварительно подцепив их в маленький свитч(типа того, что у меня на фотке). Разрешаем удаленный доступ к нодам, как через RDP, так и через консоль MMC.
Лучше сделать это до того, как ноды окажутся в домене. Были ситуации, когда сервер ругался на невозможность изменения политик фаервола. Поднимаем домен и вводим в него наши будущие кластерные ноды.
Разумеется, включаем Failover Clustering Feature.
Этап второй. Хранилище.
Теперь можно перейти непосредственно к настройке хранилища. Начнем с того, что разобьем наш получившийся страйп (RAID0) на два логических диска — один для кворума (который ныне зовется File Share Witness), а второй для хранения наших виртуальных машин. Я выделил под кворум около 15Гб, а все остальное оставил под данные. По-хорошему — под кворум с лихвой хватит и гигабайта, однако мало ли что.
Переходим к установке StarWind iSCSI Target. Для загрузки с сайта производителя потребуется регистрация, которая ни к чему, в принципе, не обязывает. После регистрации, на электронную почту падает ссылка на прямую загрузку инсталлятора и файл-ключ с лицензией. Установка состоит из нескольких нажатий на кнопку Next, так что ничего существенно сложного там нет. После установки необходимо пропустить через Windows Firewall как минимум порты 3260 и 3261. Для ленивых — его можно просто отключить, так как в нашей импровизированной сети находятся только три наших сервера.
Запускаем консоль StarWind и пробуем подключиться к iSCSI-серверу, коим в нашем случае выступает компьютер с таинственным адресом 127.0.0.1. Для авторизации потребуется секретное сочетание дефолтного логина и пароля, которые в базовом варианте выглядят как root и starwind соответственно. Почему не просили задать пароль в процессе установки, или не повесили подсказку в интерфейсе — загадка.
После подключения к серверу, необходимо подсунуть ему файл с лицензией, упавший на электронную почту. Делается это во вкладке Configuration, серверной консоли StarWind. Все интуитивно понятно и просто, за исключением ссылки на загрузку самого файла в верхнем правом углу. Только после регистрации, программа позволит нам создавать таргеты.
В процессе создания таргета, мы создаем предразмеченные img-файлы, которые будут играть роль наших LUN-ов. Размещаем их на наших разделах в соответствии с целями, и не забываем выставлять галочку, отвечающую за конкурентные соединения iSCSI(т.е. кластеризацию). Можно также задать кэширование данных, это будет полезно в случае использования нашего медленного железа.
В результате, должна получиться примерно следующая картина. Два таргета — один под кворум, второй под данные. Пора подцеплять их к серверам.
Этап третий. Цепляемся к хранилищу.
В серверах версии 2008 R2 уже есть предустановленный iSCSI Initiator, отвечающий за подключение LUN-ов с нашего импровизированного хранилища, в качестве локальных дисков. Правда в связи с отсутствием адекватного GUI на консольном Hyper-V Server, его придется вызывать через командную строку или Powershell командой iscsicpl.
В поле, подсвеченное желтым нужно ввести IP-адрес нашего хранилища, после чего должно появиться всплывающее окошко с размещенными на сервере таргетами. Разумеется, если фаервол был правильно настроен или отключен. После того как таргеты будут подключены к нашему серверу, можно будет заняться монтированием их в качестве дисков.
После нажатия на Autoconfigure, в пустом окошке появятся два длинных пути к дискам, начинающимся на \?\. После этого, можно смело идти в Disk Management и задавать буквы дискам. К слову, после задания букв на первом гипервизоре, второй гипервизор подхватит имена дисков автоматически.
В результате мы получили два гипервизора, имеющих по два общих диска, подключенных через iSCSI к нашему хранилищу. Пора переходить непосредственно к кластеризации.
Этап четвертый. Кластеризация.
При настройке отказоустойчивого кластера на двух имеющихся гипервизорах, визард сам выбрал файловые разделы под кворум и под данные. Если я правильно понял алгоритм, в качестве общих ресурсов были выбраны диски, подключенные по iSCSI, и в качестве кворума был выбран наименьший. А может он выбрал их потому, что меньшему разделу я дал лейбл Quorum… =)
После объединения двух гипервизоров в кластер, с помощью визарда и такой-то матери, консоль отказоустойчивого кластера будет выглядеть примерно так, как на картинке сверху. Стоит заметить, что в данный момент мы имеем именно отказоустойчивый кластер, в котором всю работу выполняет только одна нода, а вторая в это время простаивает и ждет пока первая сдохнет. Но нам же нужно не это.
Тут нам поможет Cluster Shared Volumes — новая вкладка в консоли кластера, появившаяся только в 2008 R2. Именно на этом хранилище могут размещаться виртуальные машины, для обеспечения отказоустойчивости. Наша задача — превратить обычный кластерный ресурс в расшареный, используя волшебную кнопку «Add Storage». После предупреждения о том, что данный тип ресурсов работает только в версиях 2008 R2 и выше, во вкладке совместно используемых ресурсов появится наш диск. Диск, в свою очередь будет смонтирован на C:\ClusterStorage\Volume1, так что все совместно используемые данные будут находиться там. В том числе и виртуальные машины. Во избежание лишних глюков, в настройках гипервизоров на каждой ноде, советую выставить дефолтные пути для дисков и виртуальных машин, с размещением на нашем общем диске.
Этап пятый. Виртуальные машины.
Теперь можно создавать виртуальные машины непосредственно из оснастки управления кластером. Во вкладке сервисов выбираем Virtual Machines, выбираем ноду и создаем машину. Монтируем откуда-нибудь дистрибутив с ОС, устанавливаем и отмонтируем. Для корректной работы Live Migration, необходимо отсутствие зависимостей от внешних ресурсов на каждой ноде.
На видео показан процесс перегонки памяти с одной ноды на другую. На переносимой виртуальной машине стоял тот же Windows Server 2008 R2, а памяти у машины было 1024мб. Сразу стоит отметить весьма посредственную скорость миграции, которая связана с кустарной реализацией нашего хранилища и сетью в 100мбит. Позднее пересоберу кластер с использованием гигабитной сети и посмотрю на прирост производительности.
Надеюсь, статья окажется для кого-нибудь полезной. Эксперементируйте!
