Замечательная книга «Программируем коллективный разум» вдохновила меня на написание этого поста по ее мотивам на тему кластерного анализа.
Возникло желание в одном посте рассмотреть кластерный анализ, его красивую реализацию на языке Python, и, особенно, визуальное представление кластеров – дендрограммы.
Код примера основан на коде примеров из книги.
Основная идея кластерного анализа – выделение среди множества данных групп, внутри которых элементы в определенной мере схожи. В рамках такого анализа, по сути, происходит определенная классификация исследуемых данных за счет распределения их по группам. Группы эти упорядочены иерархически и структуру получившихся после анализа кластеров можно представить в виде дерева – дендрограммы («дендро», как известно, по-гречески «дерево»).
Мера схожести для каждой задачи может задаваться своя, но наиболее простыми являются евклидово расстояние и коэффициент корреляции Пирсона. В примере рассматривается коэффициент корреляции Пирсона, но его можно легко заменить.
Вообще наиболее популярным исторически кластерный анализ стал в гуманитарных науках, а одной из первых задач, для которых он применялся, был анализ данных о древних захоронениях.
Алгоритм построения кластеров, в принципе, прост и логичен.
Исходными данными для алгоритма является список некоторых элементов и функция схожести между ними («близости» элементов). Каждый элемент имеет «координаты» в определенном пространстве (например, в пространстве количеств слов), по которым и вычисляется схожесть между элементами.
Пример: элементы — блоги, 2 «координаты» — количество слов «php» и «xml» в содержимом блогов.
У блога №1 – 7 раз встречается слово «php» и 5 раз «xml». Тогда «координаты» блога №1 в пространстве количества этих слов — (7;5).
У блога №2 — 6 раз встречается слово «php» и 4 раза «xml». Тогда «координаты» блога №2 в пространстве количества этих слов — (6;4).
Схожесть определим с помощью функции — евклидова расстояния.
На выходе мы получаем дерево из кластеров (иерархию кластеров).
Работает алгоритм так:
1) Шаг 1: Считать каждый элемент исходного списка кластером и добавить их в список объединения
2) Шаг 2 – N: Найти самые близкие кластеры и объединить их в новый («координаты» нового – полусумма «координат» объединяемых). Новый добавить в список объединения, а исходные кластеры – удалить из списка. Таким образом, на каждом шаге в списке объединения все меньше элементов.
Критерий останова: наличие в списке объединения лишь одного кластера, который уже не с чем объединять (получение одного, «корневого» кластера)
Реализует этот алгоритм функция hcluster:
В примере будет рассматриваться пример кластерного анализа содержимого блогов по программированию. В книге рассматриваются англоязычные блоги, я же решил проанализировать 35 русскоязычных по встречаемости англоязычных терминов. Для отображения результатов анализа названия блогов пришлось транслитить с помощью небольшой библиотеки.
Полный архив со всеми необходимыми файлами и скриптами на Python можно скачать – clusters.zip
Состав архива:
feedlist.txt со списком RSS блогов, можно взять, например, такого содержания (взято из поиска http://lenta.yandex.ru/feed_search.xml?text=программирование ):
Сама программа построения дендрограмм состоит из 2-х скриптов (сбор данных + обработка), которые запускаются последовательно:
Для работы примера понадобится Python Imaging Library (PIL), которую можно загрузить с сайта www.pythonware.com/products/pil
После разархивирования, она устанавливается как обычно:
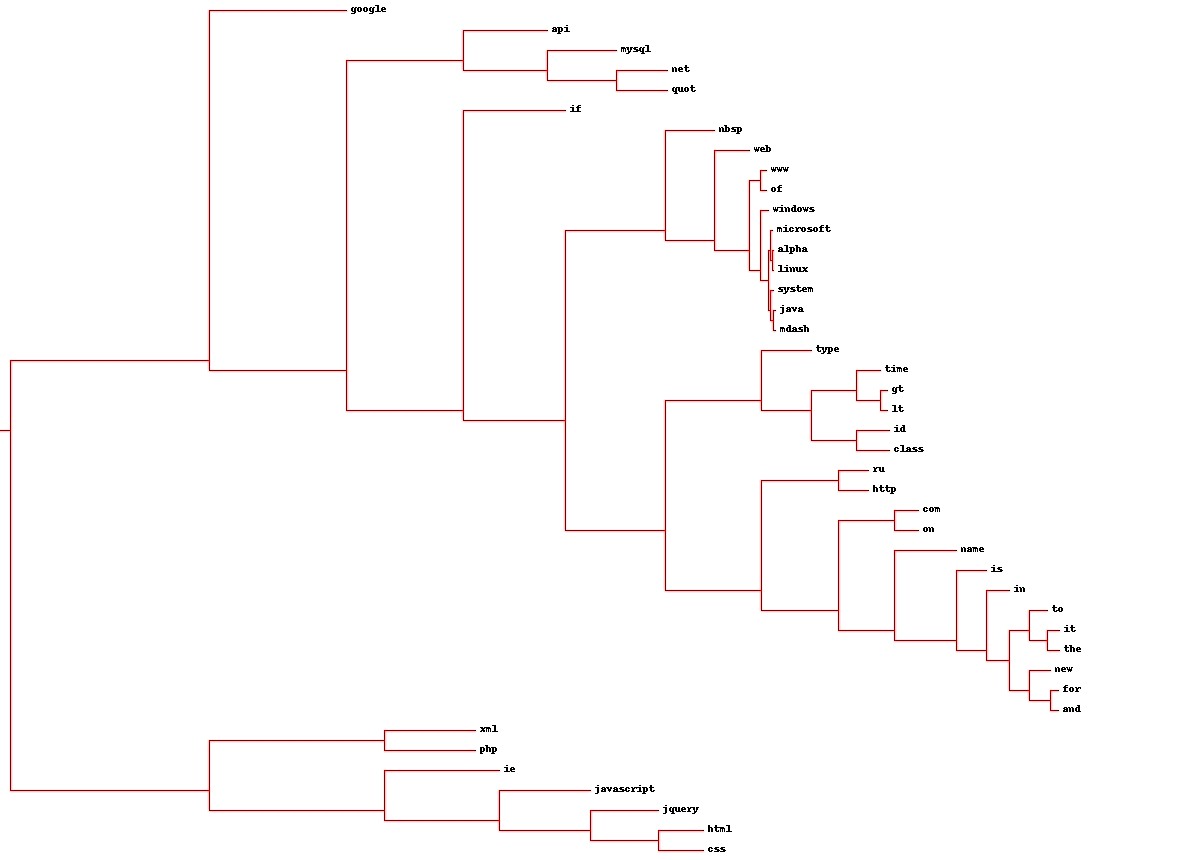
И вот самый интересный момент. В результате работы скриптов получились следующие дендрограммы:
1) для блогов (в полном качестве — img-fotki.yandex.ru/get/4100/serg-panarin.0/0_21f52_b8057f0d_-1-orig.jpg )

2) для слов (в полном качестве – img-fotki.yandex.ru/get/4102/serg-panarin.0/0_21f53_dcdea04f_-1-orig.jpg )

Изменяя feedlist.txt вы можете анализировать произвольные блоги и получать свои дендрограммы.
Возникло желание в одном посте рассмотреть кластерный анализ, его красивую реализацию на языке Python, и, особенно, визуальное представление кластеров – дендрограммы.
Код примера основан на коде примеров из книги.
Основная идея кластерного анализа – выделение среди множества данных групп, внутри которых элементы в определенной мере схожи. В рамках такого анализа, по сути, происходит определенная классификация исследуемых данных за счет распределения их по группам. Группы эти упорядочены иерархически и структуру получившихся после анализа кластеров можно представить в виде дерева – дендрограммы («дендро», как известно, по-гречески «дерево»).
Мера схожести для каждой задачи может задаваться своя, но наиболее простыми являются евклидово расстояние и коэффициент корреляции Пирсона. В примере рассматривается коэффициент корреляции Пирсона, но его можно легко заменить.
Вообще наиболее популярным исторически кластерный анализ стал в гуманитарных науках, а одной из первых задач, для которых он применялся, был анализ данных о древних захоронениях.
Алгоритм построения кластеров, в принципе, прост и логичен.
Исходными данными для алгоритма является список некоторых элементов и функция схожести между ними («близости» элементов). Каждый элемент имеет «координаты» в определенном пространстве (например, в пространстве количеств слов), по которым и вычисляется схожесть между элементами.
Пример: элементы — блоги, 2 «координаты» — количество слов «php» и «xml» в содержимом блогов.
У блога №1 – 7 раз встречается слово «php» и 5 раз «xml». Тогда «координаты» блога №1 в пространстве количества этих слов — (7;5).
У блога №2 — 6 раз встречается слово «php» и 4 раза «xml». Тогда «координаты» блога №2 в пространстве количества этих слов — (6;4).
Схожесть определим с помощью функции — евклидова расстояния.
d(blog1, blog2) = sqrt( (7-6)^2 + (5-4)^2) = 1.414
На выходе мы получаем дерево из кластеров (иерархию кластеров).
Работает алгоритм так:
1) Шаг 1: Считать каждый элемент исходного списка кластером и добавить их в список объединения
2) Шаг 2 – N: Найти самые близкие кластеры и объединить их в новый («координаты» нового – полусумма «координат» объединяемых). Новый добавить в список объединения, а исходные кластеры – удалить из списка. Таким образом, на каждом шаге в списке объединения все меньше элементов.
Критерий останова: наличие в списке объединения лишь одного кластера, который уже не с чем объединять (получение одного, «корневого» кластера)
Реализует этот алгоритм функция hcluster:
- def hcluster(rows,distance=pearson):
- distances={}
- currentclustid=-1
-
- # Clusters are initially just the rows
- clust=[bicluster(rows[i],id=i) for i in range(len(rows))]
-
- while len(clust)>1:
- lowestpair=(0,1)
- closest=distance(clust[0].vec,clust[1].vec)
-
- # loop through every pair looking for the smallest distance
- for i in range(len(clust)):
- for j in range(i+1,len(clust)):
- # distances is the cache of distance calculations
- if (clust[i].id,clust[j].id) not in distances:
- distances[(clust[i].id,clust[j].id)]=distance(clust[i].vec,clust[j].vec)
-
- d=distances[(clust[i].id,clust[j].id)]
-
- if d<closest:
- closest=d
- lowestpair=(i,j)
-
- # calculate the average of the two clusters
- mergevec=[
- (clust[lowestpair[0]].vec[i]+clust[lowestpair[1]].vec[i])/2.0
- for i in range(len(clust[0].vec))]
-
- # create the new cluster
- newcluster=bicluster(mergevec,left=clust[lowestpair[0]],
- right=clust[lowestpair[1]],
- distance=closest,id=currentclustid)
-
- # cluster ids that weren't in the original set are negative
- currentclustid-=1
- del clust[lowestpair[1]]
- del clust[lowestpair[0]]
- clust.append(newcluster)
-
- return clust[0]
* This source code was highlighted with Source Code Highlighter.В примере будет рассматриваться пример кластерного анализа содержимого блогов по программированию. В книге рассматриваются англоязычные блоги, я же решил проанализировать 35 русскоязычных по встречаемости англоязычных терминов. Для отображения результатов анализа названия блогов пришлось транслитить с помощью небольшой библиотеки.
Полный архив со всеми необходимыми файлами и скриптами на Python можно скачать – clusters.zip
Состав архива:
blogdata.txt – собранная информация по блогам для кластеризации
clusters.py - скрипт построения кластеров
draw_dendrograms.py - скрипт запуска построения кластеров и рисования дендрограмм (вызывает функции скрипта clusters.py)
feedlist.txt - список RSS блогов для анализа
generatefeedvector.py - скрипт сбора информации по блогам и формирования blogdata.txt
translit.py, utils.py - скрипты для транслитерации названий блогов
feedlist.txt со списком RSS блогов, можно взять, например, такого содержания (взято из поиска http://lenta.yandex.ru/feed_search.xml?text=программирование ):
feeds.feedburner.com/nayjest
www.codenet.ru/export/read.xml
feeds2.feedburner.com/simplecoding
feeds2.feedburner.com/nickspring
feeds2.feedburner.com/Sribna
community.livejournal.com/ru_cpp/data/rss
community.livejournal.com/ru_lambda/data/rss
feeds2.feedburner.com/rusarticles
feeds2.feedburner.com/Jstoolbox
feeds2.feedburner.com/rsdn/cpp
4matic.wordpress.com/feed
www.nowa.cc/external.php?type=RSS2
www.gotdotnet.ru/blogs/gaidar/rss
community.livejournal.com/ru_programmers/data/rss
www.compdoc.ru/rssdok.php
feeds2.feedburner.com/rsdn/philosophy
softwaremaniacs.org/blog/feed
community.livejournal.com/new_ru_php/data/rss
www.newsrss.ru/mein_rss/rss_cdata.xml
feeds2.feedburner.com/5an
subscribe.ru/archive/comp.soft.prog.linuxp/index.rss
feeds.feedburner.com/mrkto
rbogatyrev.livejournal.com/data/rss
feeds2.feedburner.com/poisonsblog
community.livejournal.com/ruby_ru/data/rss
feeds2.feedburner.com/devoid
rgt.rpod.ru/rss.xml
feeds2.feedburner.com/rsdn/decl
feeds2.feedburner.com/Toeveryonethe
www.osp.ru/rss/Software.rss
feeds2.feedburner.com/Freshcoder
blogs.technet.com/craftsmans_notes/rss.xml
feeds2.feedburner.com/RuRubyRails
feeds2.feedburner.com/bitby
opita.net/rss.xml
Сама программа построения дендрограмм состоит из 2-х скриптов (сбор данных + обработка), которые запускаются последовательно:
python generatefeedvector.py
python draw_dengrograms.py
Для работы примера понадобится Python Imaging Library (PIL), которую можно загрузить с сайта www.pythonware.com/products/pil
После разархивирования, она устанавливается как обычно:
python setup.py installИ вот самый интересный момент. В результате работы скриптов получились следующие дендрограммы:
1) для блогов (в полном качестве — img-fotki.yandex.ru/get/4100/serg-panarin.0/0_21f52_b8057f0d_-1-orig.jpg )
2) для слов (в полном качестве – img-fotki.yandex.ru/get/4102/serg-panarin.0/0_21f53_dcdea04f_-1-orig.jpg )
Изменяя feedlist.txt вы можете анализировать произвольные блоги и получать свои дендрограммы.

{kind=link}
{kind=link}