Условия
Мы используем MySQL для хранения любых данных FriendFeed. Наша база данных растёт вместе с числом пользователей. Сейчас у нас более 250 миллионов записей, это записи пользователей (post'ы), комментарии, оценки («likes»)
По мере того как росла база данных, мы время от времени имели дело с проблемами масштабируемости. Мы решали проблемы стандартными путями: slave-сервера, используемые только для чтения, memcache для увеличения пропускной способности чтения и секционирование для увеличения пропускной способности записи. Однако, по мере роста, использованные методы масштабируемости привели к затруднению добавлению новой функциональности.
В частности, изменение схемы базы данных или добавление индексов к существующим 10-20 миллионов записей приводили к полной блокировке сервера на несколько часов. Удаление старых индексов требовало времени, а не удаление ударяло по производительности, так как база данных продолжала использовать их на каждом INSERT. Существуют сложные процедуры с помощью которых можно обойти эти проблемы (например создание нового индекса на slave-сервере, и последующий обмен местами master'a и slave), однако эти процедуры настолько тяжелые и опасные, что они окончательно лишили нас желания добавлять что-то новое, требующее изменение схемы или индекса. А так как наши базы сильно распределены, реляционные вещи MySQL как например JOIN никогда не работали для нас. Тогда мы решили поискать решение проблем, лежащее вне реляционных баз данных.
Существует множество проектов, призванных решить проблему хранения данных с гибкой схемой и построением индексов на лету (например CouchDB). Однако, по-видимому ни один из них не используется крупными сайтами. В тестах о которых мы читали и прогоняли сами, ни один из проектов не показал себя стабильным, достаточно зрелым для наших целей (см. this somewhat outdated article on CouchDB, например). А все это время MySQL работал. Он не портил данные. Репликация работала. Мы уже в достаточной мере понимали все его узкие места. Нам нравился MySQL именно как хранилище, вне реляционных шаблонов.
Все взвесив, мы решили создать систему хранения данных без схемы поверх MySQL, вместо использования полностью нового решения. В этой статье я попытаюсь описать основные детали системы. Так же нам любопытно как другие сайты решили эти проблемы. Ну и мы думаем, что наша работа будет полезна другим разработчикам.
Введение
Наша база данных хранит данные без схемы в виде множества полей (например JSON объекты или словари (dictionary) в Python). Единственное обязательное поле — это id, 16-байтный UUID. Остальное должно быть не важно для нашего хранилища, именно за этим оно создаётся. Мы «изменяем» схему, просто добавив новые поля.
Будем индексировать данные записей и сохранять индекс в отдельной MySQL таблице. Если мы захотим проиндексировать 3 поля каждой записи, мы получим 3 MySQL таблицы — по одной на каждый индекс. Если больше не нуждаемся в индексе, мы перестаём писать в таблицу индекса, и можем удалить таблицу при желании. Если требуется новый индекс, мы создаём новую таблицу MySQL для него и запускаем асинхронный процесс для заполнения индекса, не прерывая остальные задачи.
Как результат, мы получаем большее число таблиц чем было до этого, но добавление и удаление индексов упростилось. Мы серьезно оптимизировали процесс для заполнения индексов (который мы назвали «The Cleaner»), так чтобы он создавал индексы быстро без нарушения работы сайта. Теперь мы можем добавлять новые свойства и индексировать за дни, а не недели. Так же теперь не требуется обмен master на slave или другие опасные операции.
Детали
В MySQL наши записи хранятся следующим образом:
Copy Source | Copy HTML
- CREATE TABLE entities (
- added_id INT NOT NULL AUTO_INCREMENT PRIMARY KEY,
- id BINARY(16) NOT NULL,
- updated TIMESTAMP NOT NULL,
- body MEDIUMBLOB,
- UNIQUE KEY (id),
- KEY (updated)
- ) ENGINE=InnoDB;
Столбец added_id нужен из-за того, что InnoDB физически сохраняет данные в порядке первичного ключа. AUTO_INCREMENT ключи гарантируют, что новые записи записаны на жесткий диск следом за старыми, что помогает и чтению, и записи (доступ к новым записи как правило происходит чаще, чем к старым записям, поэтому страницы FriendFeed отсортированы в обратном хронологическом порядке). Тело записи хранится как сжатый (zlib) Python-pickled словарь.
Индексы хранятся в отдельных таблицах. Для нового индекса мы создаём таблицу с атрибутами, по которым мы хотим осуществлять поиск. Для примера, запись в FriendFeed выглядит примерно так:
Copy Source | Copy HTML
- {
- "id": "71f0c4d2291844cca2df6f486e96e37c",
- "user_id": "f48b0440ca0c4f66991c4d5f6a078eaf",
- "feed_id": "f48b0440ca0c4f66991c4d5f6a078eaf",
- "title": "We just launched a new backend system for FriendFeed!",
- "link": "http://friendfeed.com/e/71f0c4d2-2918-44cc-a2df-6f486e96e37c",
- "published": 1235697046,
- "updated": 1235697046,
- }
Мы хотим проиндексировать по полю user_id для отображения всех записей, что сделал пользователь. Наша индекс-таблица выглядит следующим образом:
Copy Source | Copy HTML
- CREATE TABLE index_user_id (
- user_id BINARY(16) NOT NULL,
- entity_id BINARY(16) NOT NULL UNIQUE,
- PRIMARY KEY (user_id, entity_id)
- ) ENGINE=InnoDB;
Наша библиотека автоматически создаёт индексы. Для старта нашего хранилища, которое сохраняет подобные записи с индексом, описанным выше, мы пишем (на Python):
Copy Source | Copy HTML
- user_id_index = friendfeed.datastore.Index(
- table="index_user_id", properties=["user_id"], shard_on="user_id")
-
- datastore = friendfeed.datastore.DataStore(
- mysql_shards=["127.0.0.1:3306", "127.0.0.1:3307"],
- indexes=[user_id_index])
-
- new_entity = {
- "id": binascii.a2b_hex("71f0c4d2291844cca2df6f486e96e37c"),
- "user_id": binascii.a2b_hex("f48b0440ca0c4f66991c4d5f6a078eaf"),
- "feed_id": binascii.a2b_hex("f48b0440ca0c4f66991c4d5f6a078eaf"),
- "title": u"We just launched a new backend system for FriendFeed!",
- "link": u"http://friendfeed.com/e/71f0c4d2-2918-44cc-a2df-6f486e96e37c",
- "published": 1235697046,
- "updated": 1235697046,
- }
-
- datastore.put(new_entity)
-
- entity = datastore.get(binascii.a2b_hex("71f0c4d2291844cca2df6f486e96e37c"))
- entity = user_id_index.get_all(datastore, user_id=binascii.a2b_hex("f48b0440ca0c4f66991c4d5f6a078eaf"))
-
Index класс смотрит на поле user_id во всех записях и автоматически создаёт индекс в таблице index_user_id. Так как наша база данных секционирована (sharding), аргумент shard_on используется для определения в какой сегменте будет храниться индекс (в нашем случае entity[«user_id»] % num_shards)
Для выполнения запроса с использованием созданного индекса используется объект класса Index (см. user_id_index.get_all). Алгоритм «хранилища» делает «join» таблиц index_user_id и таблицы с записями, сначала пробегаясь по всем таблицам index_user_id на всех сегментах базы данных для получения списка ID записей и затем получает эти записи из таблицы entities.
Для создания нового индекса, например по атрибуту link, мы создадим таблицу:
Copy Source | Copy HTML
- CREATE TABLE index_link (
- link VARCHAR(735) NOT NULL,
- entity_id BINARY(16) NOT NULL UNIQUE,
- PRIMARY KEY (link, entity_id)
- ) ENGINE=InnoDB DEFAULT CHARSET=utf8;
Код включения нового индекса будет:
Copy Source | Copy HTML
- user_id_index = friendfeed.datastore.Index(
- table="index_user_id", properties=["user_id"], shard_on="user_id")
- link_index = friendfeed.datastore.Index(
- table="index_link", properties=["link"], shard_on="link")
- datastore = friendfeed.datastore.DataStore(
- mysql_shards=["127.0.0.1:3306", "127.0.0.1:3307"],
- indexes=[user_id_index, link_index])
Так же мы можем заполнить индекс асинхронно (даже во время реальной работы) с помощью процесса:
./rundatastorecleaner.py --index=index_link
Cогласованность и атомарность
Из-за того что база данных сегментирована, индекс для конкретной записи могут находиться на разных сегментах. Что произойдет, если процесс непредвиденно завершится до того, как запишет все индексы по таблицам?
Самые амбициозные FriendFeed инженеры считали, что транзакции необходимы в данной ситуации. Однако мы хотели сохранить нашу систему как можно более простой. Мы решили ослабить ограничения:
- Набор атрибутов хранящийся в главной таблице записей — канонический
- Индекс может возвращать неподходящие записи.
В результате, мы создаём новую запись в следующем порядке:
- Сохраняем запись в основную таблицу, пользуясь ACID гарантиями InnoDB (Atomicity, Consistency, Isolation, Durability).
- Сохраняем индексы во все индекс-таблицы на всех сегментах
Когда мы читаем из индекс таблиц, мы знаем что результат может быть неточен (то есть результат может содержать лишние объекты, если запись не была закончена на шаге 2). Чтобы убедиться, что мы возвращаем правильные записи, мы повторно фильтруем результат, полученный из индекс таблиц:
- Читаем entity_id из всех индекс-таблиц, участвующих в запросе
- Читаем все записи по полученным id
- Фильтруем (в Python) все записи, что не подходят по критериям запроса.
Для испраления индексов создан процесс «Cleaner» (чистильщик), который упоминался ранее. Он запускается по таблице записей, записывая пропущенные индексы, удаляя старые и исправляя не верные. Он начинает с новых записей, на практике все неточности исправляются очень быстро (в течение нескольких секунд).
Производительность
Мы немного оптимизировали наши первичные ключи в новой системе и довольны результатом. Ниже диаграмма задержек перед отдачей страницы FriendFeed за последний месяц (мы запустили новый backend несколько дней назад):
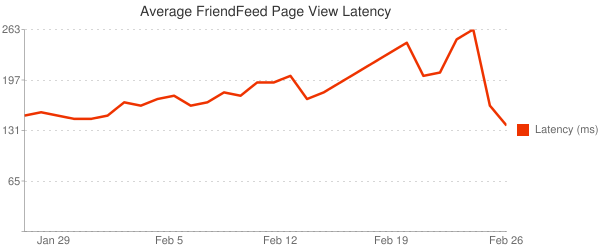
В частности, задержка нашей системы стабильна, даже во время пиков в середине дня. Ниже диаграмма за последние 24 hours:
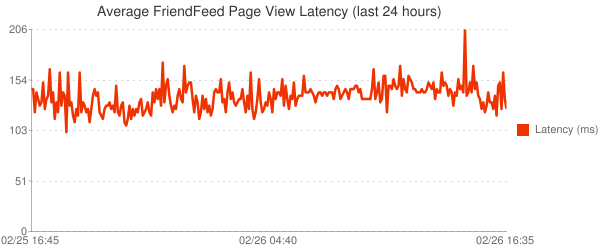
Сравните с задержками неделю назад:
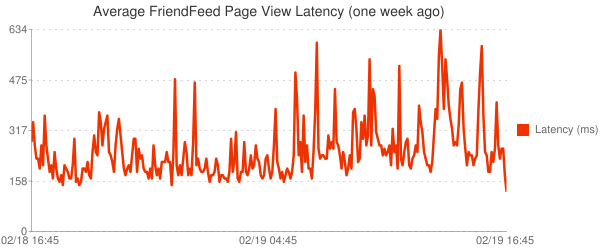
С новой системой стало на много легче работать. Мы уже изменили индексы несколько раз на рабочей системе, и сейчас начинаем миграцию наших главных таблиц, дабы двигаться дальше.
How FriendFeed uses MySQL to store schema-less data, by Bret Taylor • February 27, 2009
Так же рекомендую к прочтению обсуждение этой статьи на популярном mysqlperformanceblog.com
