Самостоятельно обновляемые текстуры
Когда существует возможность распараллеливания симуляций или задач рендеринга, то обычно лучше всего выполнять их в GPU. В этой статье я объясню технику, использующую этот факт для создания впечатляющих визуальных трюков с низкими затратами производительности. Все эффекты, которые я продемонстрирую, реализованы при помощи текстур, которые при обновлении "
рендерятся сами в себя"; текстура обновляется при рендеринге нового кадра, а следующее состояние текстуры полностью зависит от предыдущего состояния. На этих текстурах можно рисовать, вызывающая определённые изменения, а сама текстура прямо или косвенно может применяться для рендеринга интересных анимаций. Я называю их
свёрточными текстурами.
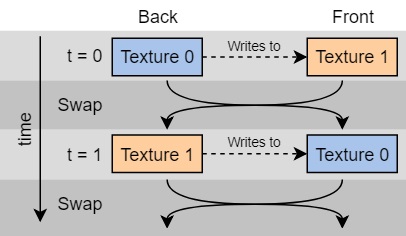
Рисунок 1: двойная буферизация свёрточной текстуры
Прежде чем двигаться дальше, нам нужно решить одну проблему: текстуру нельзя считывать и записывать одновременно, такие графические API, как OpenGL и DirectX, не позволяют этого делать. Так как следующее состояние текстуры зависит от предыдущего, нам нужно как-то обойти это ограничение. Мне нужно выполнять чтение из другой текстуры, а не из той, в которой выполняется запись.
Решением является
двойная буферизация. На рисунке 1 показано, как она работает: на самом деле вместо одной текстуры есть две, но в одну из них выполняется запись, а из другой производится чтение. Текстура, в которую выполняется запись, называется
back buffer (вторичный буфер), а рендерящаяся текстура —
front buffer (первичный буфер). Поскольку свёрточная тестура «записывается в саму себя», вторичный буфер в каждом кадре выполняет запись в первичный буфер, а затем первичный рендерится или используется для рендеринга. В следующем кадре роли меняются и предыдущий первичный буфер используется как источник для следующего первичного буфера.