Сотрудник надомной мануфактуры мисье Жибер доходчиво объясняет, в каком положении он оказался, когда увидел сколько ткани выпускает недавно построенная неподалеку фабрика

Product data analyst | Ex-Yandex
Сотрудник надомной мануфактуры мисье Жибер доходчиво объясняет, в каком положении он оказался, когда увидел сколько ткани выпускает недавно построенная неподалеку фабрика

Всем привет! Я Александр Фадеев, руководитель проектов по безопасности мобильного оператора «Тинькофф Мобайл». Наверняка вы периодически получаете звонки от мошенников, которые прикидываются специалистами банка. Или надоедливые звонки и СМС с предложениями сменить интернет-провайдера, стать клиентом стоматологии или купить квартиру. Телефонные операторы постоянно ищут способы защитить абонентов от злоумышленников, которые пытаются украсть деньги, и спамеров, и сегодня я расскажу, как это делаем мы.
Это вторая статья из цикла об инструментах для защиты клиентов Тинькофф от злоумышленников. О том, какие это инструменты, вы можете узнать из вводной статьи.

Многие из вас, я уверен, слышали о теории игр в какой-то момент своей жизни. Если вы хотите выглядеть умным и произвести впечатление на свою девушку — просто упомяните «игру с нулевой суммой» или «эволюционную стратегию», и ваши шансы отвести её домой сегодня вечером только что подскочили на 50%. Или вы можете использовать теорию игр, чтобы принимать решения в инвестировании своих денег (чтобы их полностью потерять и разориться) или, например решая, на какой девушке жениться (что также очень вероятно вас разорит). Как видите, это очень полезная теория.
Чтобы казаться умным - достаточно выучить эти пару выражений, но чтобы на самом деле что-то понимать - придется разобраться. Оказывается, это не так уж сложно и довольно интересно. Давайте посмотрим.
Начнем с того, что библиотек для разработки телегам-ботов на Python несколько, я упомяну основные три. В первой части статьи будет небольшой обзор этих библиотек (примеры кода тут будут для красоты, не пугайтесь, ниже будет пошаговый Гайд по одной конкретной библиотеке), потом комментарий о том, какую стоит выбрать для разработки конкретно своего бота и подробное руководство для новичков по разработке бота с разбором каждой строчки кода.

«Магнит» — это не только продукты съедобные, но и продукты цифровые: мобильные приложения, веб-сервисы. Команда пользовательского опыта старается делать их лучше: для этого есть исследователи, которые проводят исследования внутренних (для сотрудников) и внешних (для клиентов) продуктов, и CJE — эксперты по клиентскому опыту, которые строят карты клиентских путей на основе данных исследований и обратной связи.
Наша работа — находить и помогать решать проблемы пользователей. Но мы сами, в свою очередь, сталкиваемся с проблемами при выполнении этой задачи. Об этих проблемах и о том, как мы их решаем, расскажем в статье.

Всем привет! Это продолжение рассказа о том, как наша команда Ling Bizkit победила в двух хакатонах. В первый раз это было соревнование Северо-Западного региона в рамках Цифрового Прорыва, а во второй — уже всероссийский этап.

В прошлой статье мы рассматривали неочевидные проблемы АБ тестирования и как можно с ними справляться [ссылка]. Но часто бывает так, что при внедрении новой функциональности АБ тестирование провести нельзя. Например, это типично для маркетинговых кампаний нацеленных на массовую аудиторию. В данной ситуации существует вероятность того, что пользователи контрольной группы, которым недоступна рекламируемая функциональность, начнут массово перерегистрироваться. Также возможен сценарий, при котором возникнет значительное количество негативных отзывов из-за воспринимаемой дискриминации. Но задача оценки таких нововведений одна из наиболее частых, которые приходится решать аналитикам. Если метрики только улучшаются, то это обычно легко объяснить хорошей работой, а если метрика ухудшилась, то сразу появляется задача на аналитика. В этой заметке мы рассмотрим первую часть задачи - а действительно ли метрика упала и если да, то имеет ли смысл разбираться дальше?
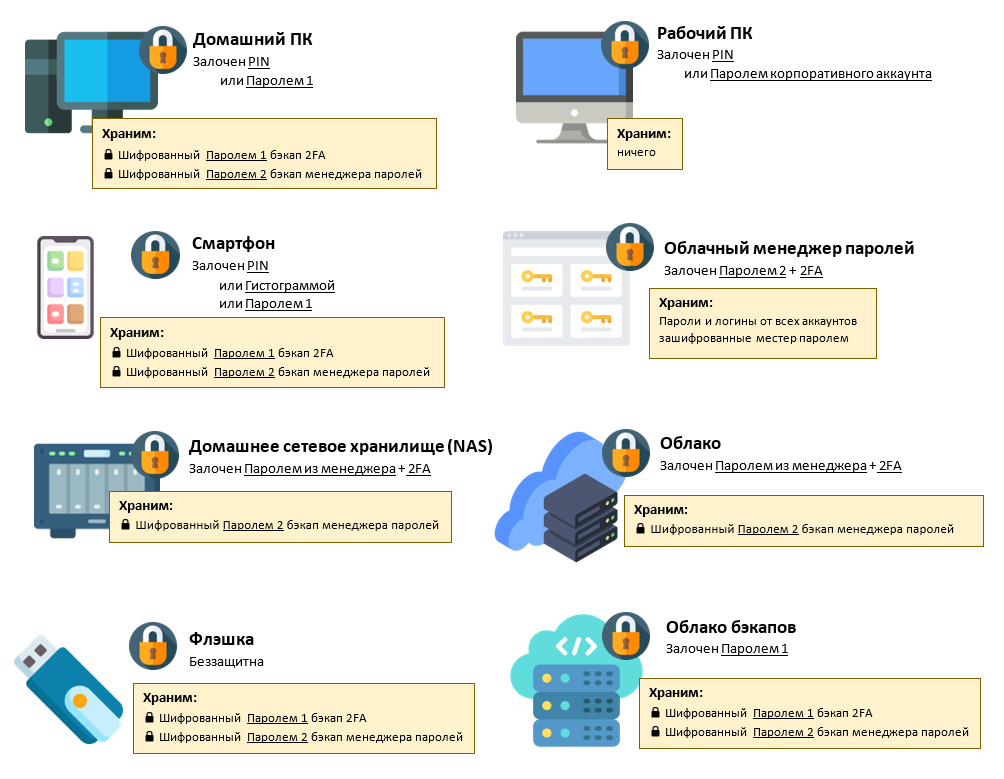
Я долго собирал информацию о том, как организовать свои аккаунты. Как сделать доступ к ним достаточно надёжным и стойким к утере девайсов.
Меня интересовало, как я могу залогиниться туда, где многофакторная авторизация через телефон, в случае потери телефона.
Или, как обезопасить себя от забывания мастер пароля от менеджера паролей? На моей практике я несколько раз забывал пин-код от банковской карты, состоящий из 4-ёх цифр, после ежедневного использования на протяжении многих месяцев. Мозг - странная штука.
В итоге, спустя месяцы изучения темы, я пришёл к следующему сетапу, который решил описать в виде мануала.
Привет, Хабр!
Сегодня с вами участница профессионального сообщества NTA Яруллина Ляйсян.
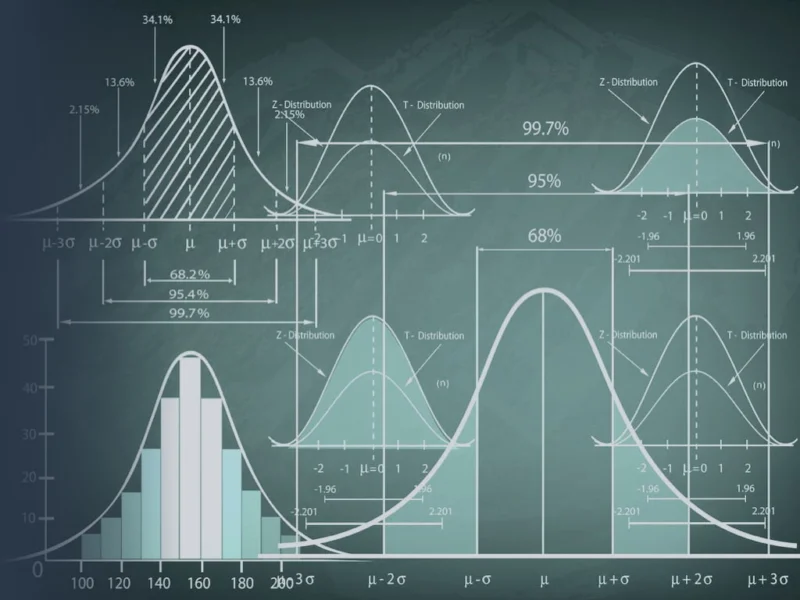
В современном мире визуализация данных используется повсеместно. Она позволяет в сжатые сроки предоставить изображение или видео, описывающее колоссальное количество информации, что делает визуализацию незаменимой в анализе данных.
Но не менее важной в указанном вопросе является статистика. Она позволяет провести качественную обработку данных и сделать выводы на ее основе — без статистической базы графическое представление данных не несет особой ценности. И в наше время океана неподтвержденной информации это куда более серьезная проблема, чем могло бы показаться изначально. Поэтому важно уметь быстро внедрять аннотации статистической значимости в полученную визуализацию и уметь ее расшифровывать.
В последние годы создаются специальные статистические пакеты, которые позволяют реализовать вышеизложенное в жизнь быстро и просто. Например, специально для библиотеки Seaborn, используемой для построения статистических графиков, был создан пакет Statannotations. Он позволяет проводить дополнительные вычисления статистических тестов и добавлять их результаты в виде аннотаций к графикам. Рассмотрю его подробнее и для примера загляну в глубины мозга.

Введение: Привет, Хабр! Сегодня мы исследуем мир менее известных, но чрезвычайно полезных библиотек Python, которые могут значительно обогатить ваш аналитический инструментарий.
? Подписывайтесь на мой телеграмм-канал DataTechCommunity для получения ежедневных обновлений о Python и аналитике данных!
Содержание:
Рассматриваем 5 малоизвестных, но полезных библиотек для аналитиков данных. Они помогут вам в машинном обучении, обработке больших данных и визуализации.

Привет, Хабр! Меня зовут Ричард, я работаю в команде kPHP в VK, занимаюсь разработкой kPHP, плагинов для IDE, а также другого инструментария, делая жизнь разработчиков проще. В своей работе мне приходится иметь дело с PSI деревьями, AST, самописными структурами данных и их модификациями, и даже QuickSelect (и более сложные алгоритмы) мне доводилось реализовывать. Хочу немного поговорить про один из краеугольных, пожалуй, камней в IT, а именно про «алгоритмы и структуры данных» — тема не теряет актуальности со времен появления Хабра. Заранее оговорюсь, мой пост на 90% состоит из личного опыта во время обучения, работы и преподавания.

Если проект использует реляционную СУБД обязательно возникнет вопрос - как организовать скрипты для сохранения гибкости и уменьшения трудозатрат.
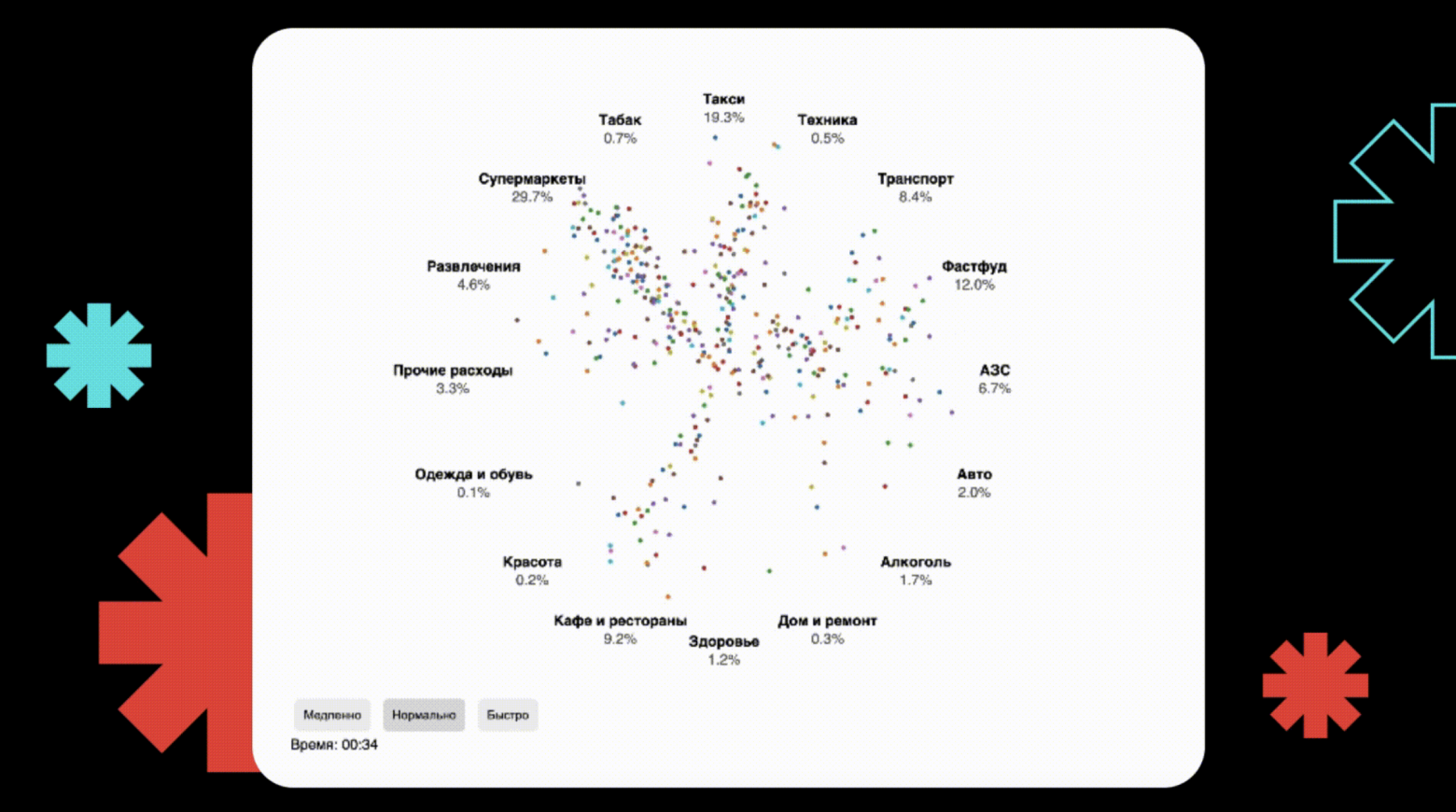
Привет, Хабр! Меня зовут Тагир, я занимаюсь аналитикой игровых механик. Недавно я наткнулся на статью, в которой визуализировали жизни тысяч людей с точностью до минуты — люди отмечали, на что они тратят свое время в течение дня, а автор агрегрировал эти данные и сделал визуализацию, разбив активности по категориям.
Я переложил эту логику на банковские транзакции, чтобы посмотреть, на что люди тратят свои деньги в определенный момент времени, и получил статистику, о которой все и так вроде бы знают. На обед люди ходят в ближайшее кафе и заправляют машину, после работы — в супермаркет, а на выходных — отдыхают в увеселительных заведениях. Но визуализировав эти данные, увидел, что выглядит это весьма залипательно.

Во время пандемии в 2020 году весь мир столкнулся с необходимостью обеспечить своих сотрудников возможностью работать из дома, да и вообще из любой точки мира. Банковская сфера, как и другие секторы, работающие с чувствительными данными, столкнулись с трудностями адаптации своих ИТ-систем и рабочих данных к удаленному формату. Нужно учесть и уровень защиты данных, и внедрять новые технические решения, и оптимизировать рабочие процессы.
В этой статье хочу разобрать кейс об организации системы удаленной работы сотрудников в банковском секторе, который мы с коллегами из «ЛАНИТ-Интеграции» внедрили в крупном российском банке.

Один из членов команды сказал мне, что стендапы — это пустая трата времени. И я с этим согласен. А вы разве не согласны?

Когда слушаешь доклады на больших ML-конференциях, то часть докладов вызывает восторг, но другая часть на послевкусии вызывает странное чувство. Да, доклад может быть очень крутым, математика блестящей, сложность крышесносной, но что-то как будто бы не так.
Эта статья — развлекательно-философская, все совпадения с реальностью — случайны, персонажи вымышлены, с точкой зрения — можно не соглашаться, но поразмышлять — стоит.
Да при чем здесь вообще деривативы? А просто у деривативов, дженги и машинного обучения — много общего, давайте разбираться.

Хабровчане, приветствую! Меня зовут Андрей Иванов, я системный аналитик в сфере медицины и здравоохранения. До 2005 года работал практикующим врачом, потом руководил медицинским информационно-аналитическим центром. Спустя время возникла настоятельная потребность получить базовое IT-образование и научиться тому, чем прежде приходилось руководить, — так я начал обучение на курсе «Системный аналитик».
Позже я принял участие в Мастерской Практикума, где смог реализовать давнюю идею — сделать удобочитаемыми материалы медицинской статистики. Выбор пал на отчёт главного онколога Министерства здравоохранения России. Он выходит ежегодно и выглядит как огромный сборник таблиц формата А4. Ни один даже самый крутой мегамозг, просматривая эти гектары цифр, не в состоянии понять, «что такое хорошо и что такое плохо в онкологической службе».
Решить эту проблему и взялась команда аналитиков данных. Сразу же оговорюсь, мы не пытаемся анализировать данные онкологической статистики. Мы разрабатываем целевой инструмент, который хотим передать в руки медицинского (онкологического) сообщества — там уже смогут с полным правом делать профессиональные выводы «о добре и зле» и конечно же, ответить на извечный вопрос «что делать?».
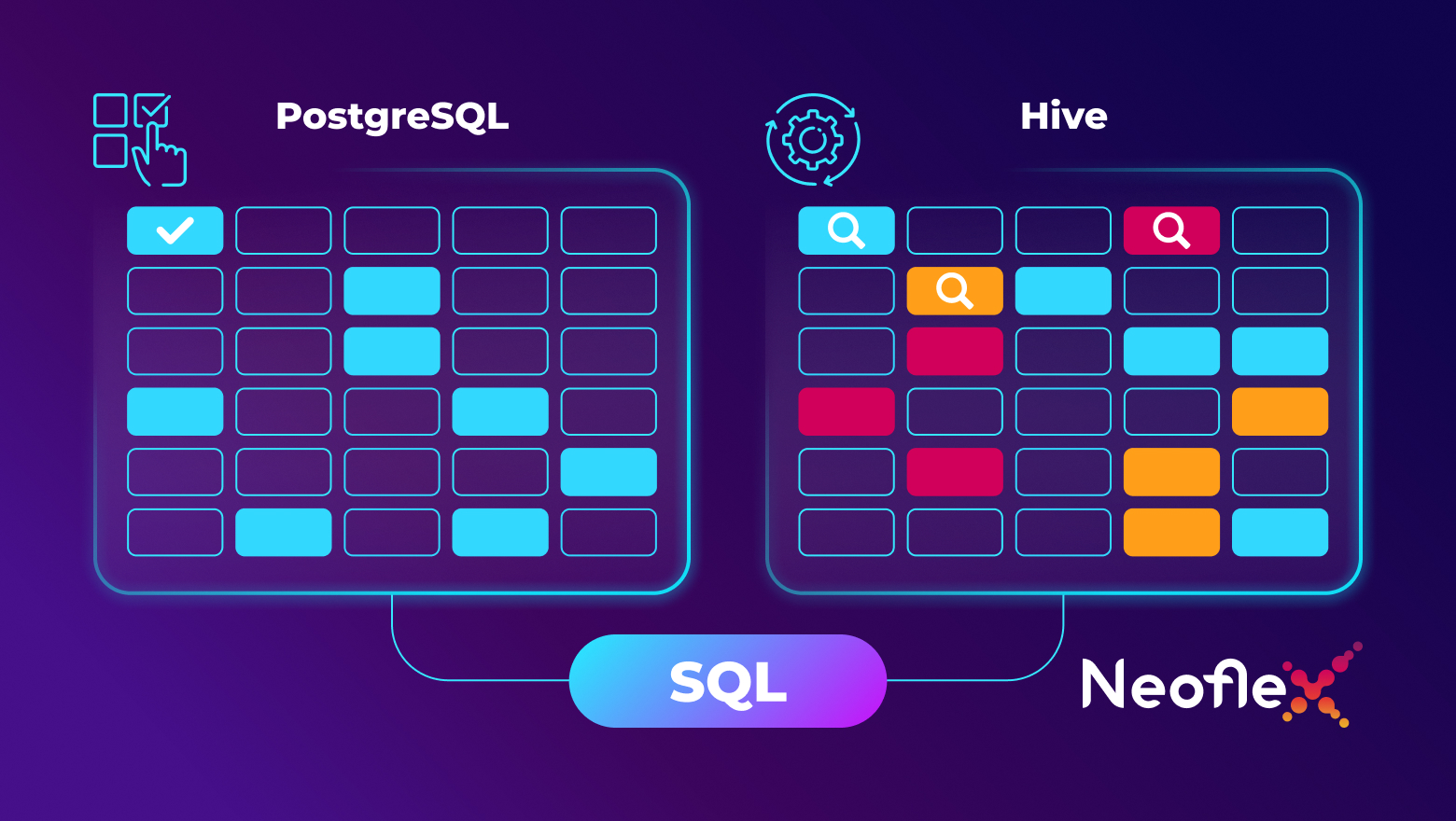
Часто специалисты, работающие с классическими реляционными базами данных, например, с PostgreSQL, испытывают затруднения в работе при переходе на систему хранения больших данных типа Apache Hive. Это связано с непониманием того, как можно использовать в новой среде уже наработанные подходы и методы работы с данными.
В данной статье рассмотрены некоторые особенности использования языка SQL в реляционных СУБД и Apache Hive. Кроме того, проведен сравнительный обзор возможностей и подходов, а также применение партиционирования на практике.
Материал будет полезен специалистам младших и средних грейдов, которые используют в своей практике SQL, но имеют мало опыта в Hive или Postgres.

Когда я пытаюсь обойтись без *args и **kwargs в сигнатурах функций, это не всегда можно сделать, не вредя удобству использования API. Особенно — когда надо писать функции, которые обращаются к вспомогательным функциям с одинаковыми сигнатурами.
Типизация *args и **kwargs всегда меня расстраивала, так как их нельзя было заблаговременно снабдить точными аннотациями. Например, если и позиционные, и именованные аргументы функции могут содержать лишь значения одинаковых типов, можно было поступить так:
def foo(*args: int, **kwargs: bool) -> None:
...
Применение такой конструкции указывает на то, что args — это кортеж, все элементы которого являются целыми числами, а kwargs — это словарь, ключи которого являются строками, а значения имеют логический тип.
Но нельзя было адекватно аннотировать *args и **kwargs в ситуации, когда значения, которые можно передавать в качестве позиционных и именованных аргументов, могут, в разных обстоятельствах, относиться к различным типам. В таких случаях приходилось прибегать к Any, что противоречило цели типизации аргументов функции.