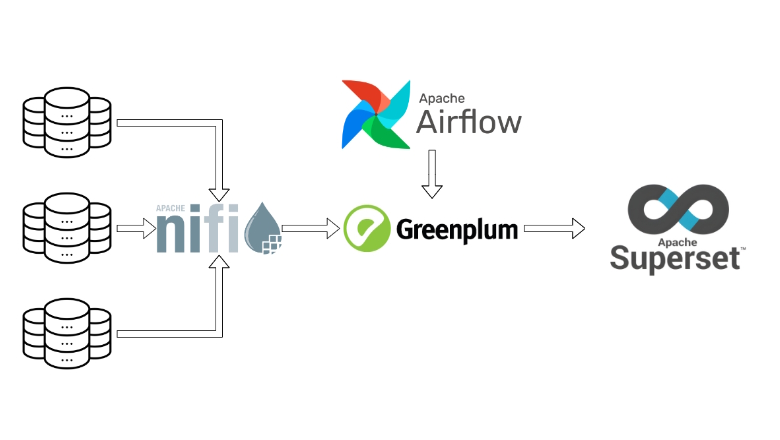
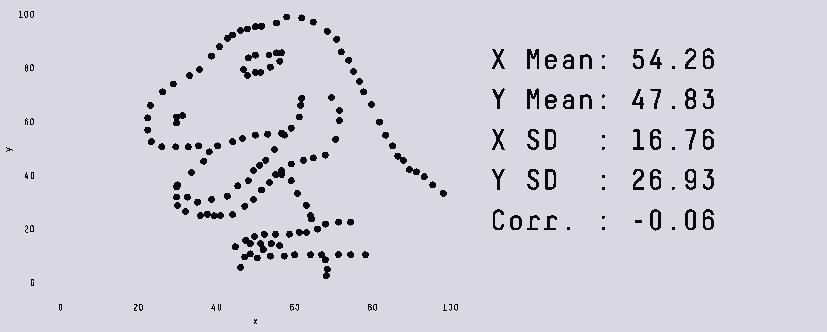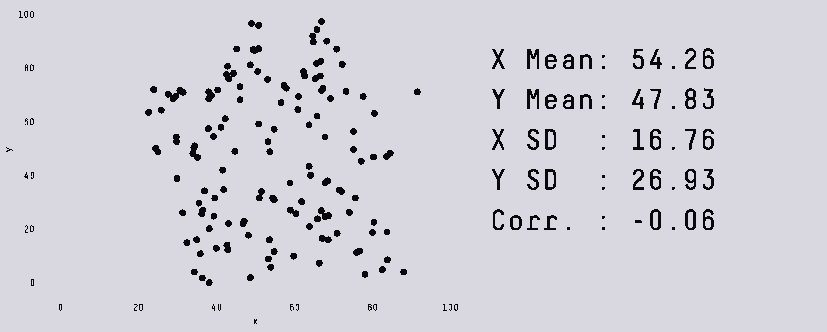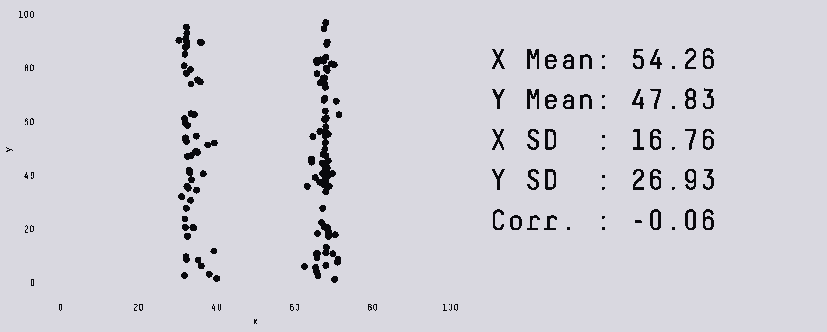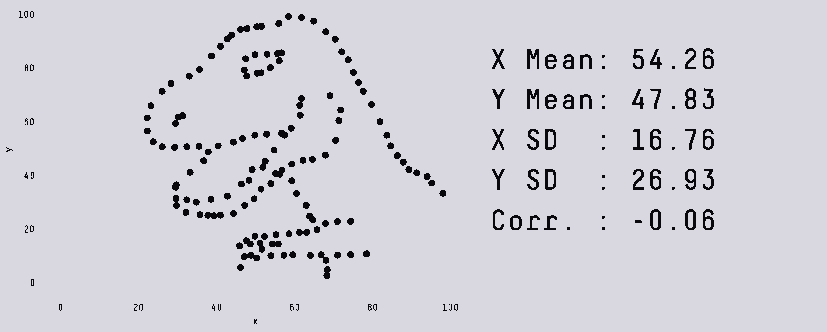Всем привет! Представьте себе ситуацию: ваша уютная маленькая команда Data Science занимается прогнозированием спроса для пары десятков дарксторов с помощью какого-нибудь коробочного Prophet. И в один прекрасный день к вам приходит бизнес. Бизнес садится, закидывает ногу на ногу, закуривает сигару и говорит:
«Мы хотим максимально автоматизировать закупки. Нам нужно, чтобы вы умели строить прогноз по всем товарам, старым и новым, для всех дарксторов, старых и новых. А их будет много, их будут сотни, тысячи, миллионы. А ещё у нас будет миллион видов скидок и разные типы ценообразования, и ещё куча промо-механик и конкурсов интересных. Мы хотим, чтобы прогноз обязательно адекватно на всё это реагировал». (с) Типичный Бизнес
Хорошо, думаем мы, кажется, что это звучит нетрудно…
С этой задачи начинается моя история о прогнозе спроса в Самокате. Меня зовут Мария Суртаева, я Data Scientist и расскажу о концепции прогноза спроса, его практических задачах и роли градиентного бустинга.