
К моему удивлению, в открытом доступе оказалось не так уж много подробных и понятных объяснений того как работает модель GPT от OpenAI. Поэтому я решил всё взять в свои руки и написать этот туториал.

ML — engineer
К моему удивлению, в открытом доступе оказалось не так уж много подробных и понятных объяснений того как работает модель GPT от OpenAI. Поэтому я решил всё взять в свои руки и написать этот туториал.

Пожалуй, одна из важнейших тем для подготовки крутых специалистов машинного обучения. Ведь закономерности всегда подлежат какой-то аналитике с точки зрения вероятностей. А как иначе?
🔜 Как вы будете рекомендовать девушек в анкетах знакомств, если не вычислите статистическую вероятность симпатии от огонечков на шести сторисах?
🔜 Как вы будете подсчитывать успех кражи внутренних данных компании в обход NDA?
🔜 Может ограбить банк не такая уж плохая идея с вашими вводными данными?
Байес — это палочка-выручалочка.
По статистике 90% мужчин и девушек, что знают метод МСМС, лучше пахнут и получают на 100% больше взаимных симпатий.
Хотите также? — читайте нашу статью по Байесовской статистике в ML для самых маленьких.

В этой статье мы подробно рассмотрим распознавание именованных сущностей (Named Entity Recognition, NER) и его применение на практике. Простым и доступным языком объясним, как работает NER, приведем примеры кода с использованием библиотеки SpaCy и покажем, как обучать модели для распознавания именованных сущностей. Эта статья поможет вам быстро освоить основы и начать применять NER в своих проектах!

С момента своего появления в 2017 году в публикации Attention is All You Need трансформеры стали доминирующим подходом в обработке естественного языка. В 2021 году в статье An Image is Worth 16x16 Words трансформеры были успешно адаптированы для задач компьютерного зрения. С тех пор для компьютерного зрения было предложено множество архитектур на основе трансформеров.
В этой статье мы рассмотрим трансформер зрения (Vision Transformer, ViT) в том виде, в котором он был представлен во второй статье. Она включает в себя открытый код ViT, а также концептуальные объяснения компонентов. Реализация ViT, рассмотренная в статье, выполнена с использованием пакета PyTorch.
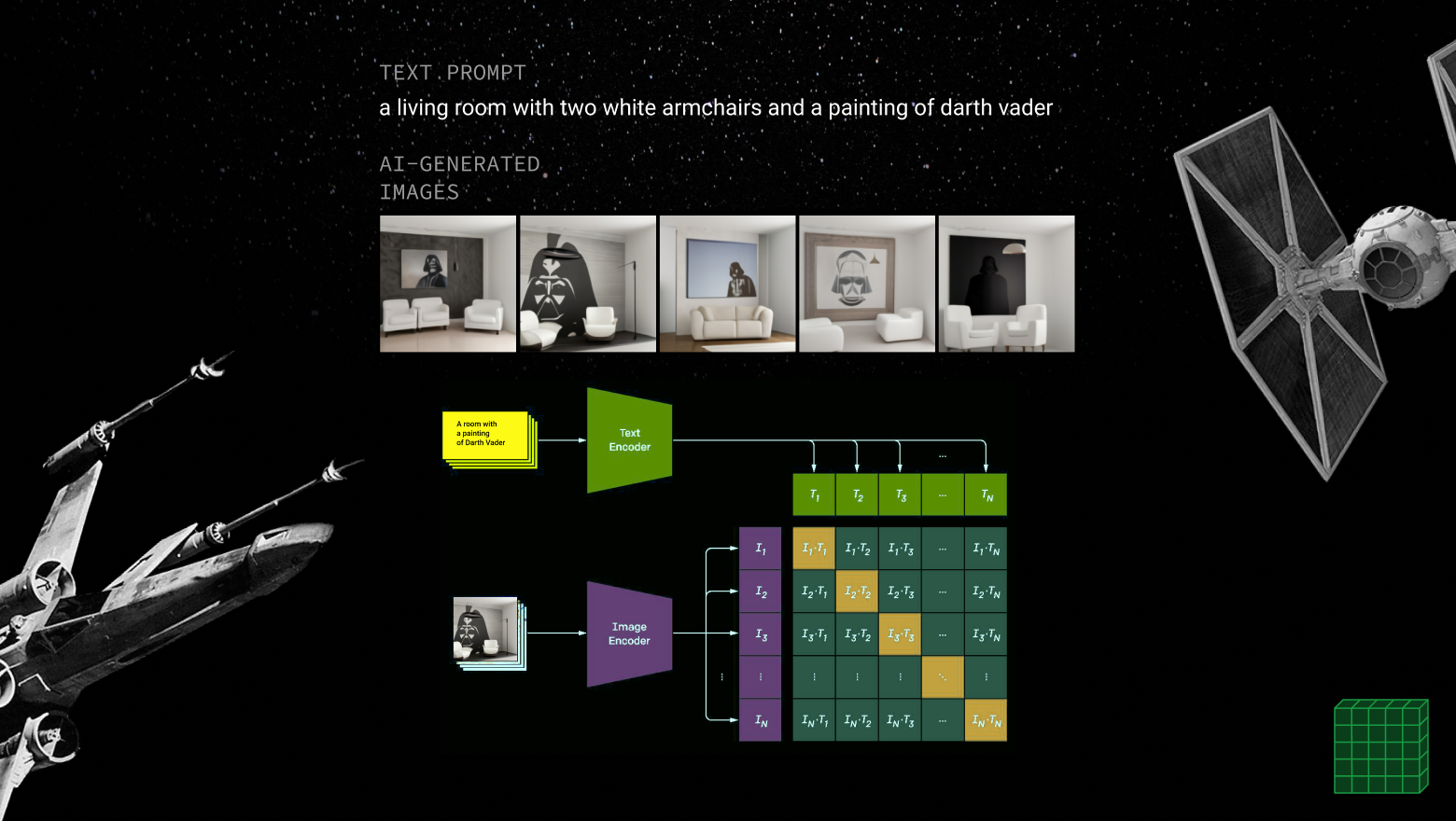
Можете представить себе классификатор изображений, решающий практически любую задачу, и который вообще не нужно обучать? Это новая нейросеть CLIP от OpenAI. Разбор CLIP из рубрики: Разбираем и Собираем Нейронные Сети на примере Звездных Войн!
Нет данных, нет разметки, но нужен классификатор изображений для конкретной задачи? Нет времени возиться с обучением нейронной сети, но нужно получить классификацию высокой точности? Все это стало возможным. Вам нужно обучение без обучения!
Готов и туториал: Собираем нейросети. Классификатор животных из мультфильмов. Без данных и за 5 минут. CLIP: Обучение без Обучения + код
Подробно и доступно разбираем что такое "обучение без обучения" и саму нейросеть CLIP от OpenAI. Стираем границы между Текстом и Изображением. Внимание: статья подходит под любой уровень: от нулевого до профи. Приятного прочтения!


Почему так сложно понять asyncio?
Асинхронное программирование традиционно относят к темам для "продвинутых". Действительно, у новичков часто возникают сложности с практическим освоением асинхронности.
Но будь я автором самого толстого в мире учебника по python, я бы рассказывал читателям про асинхронное программирование уже с первых страниц. Вот только написали "Hello, world!" и тут же приступили к созданию "Hello, asynchronous world!". А уже потом циклы, условия и все такое.
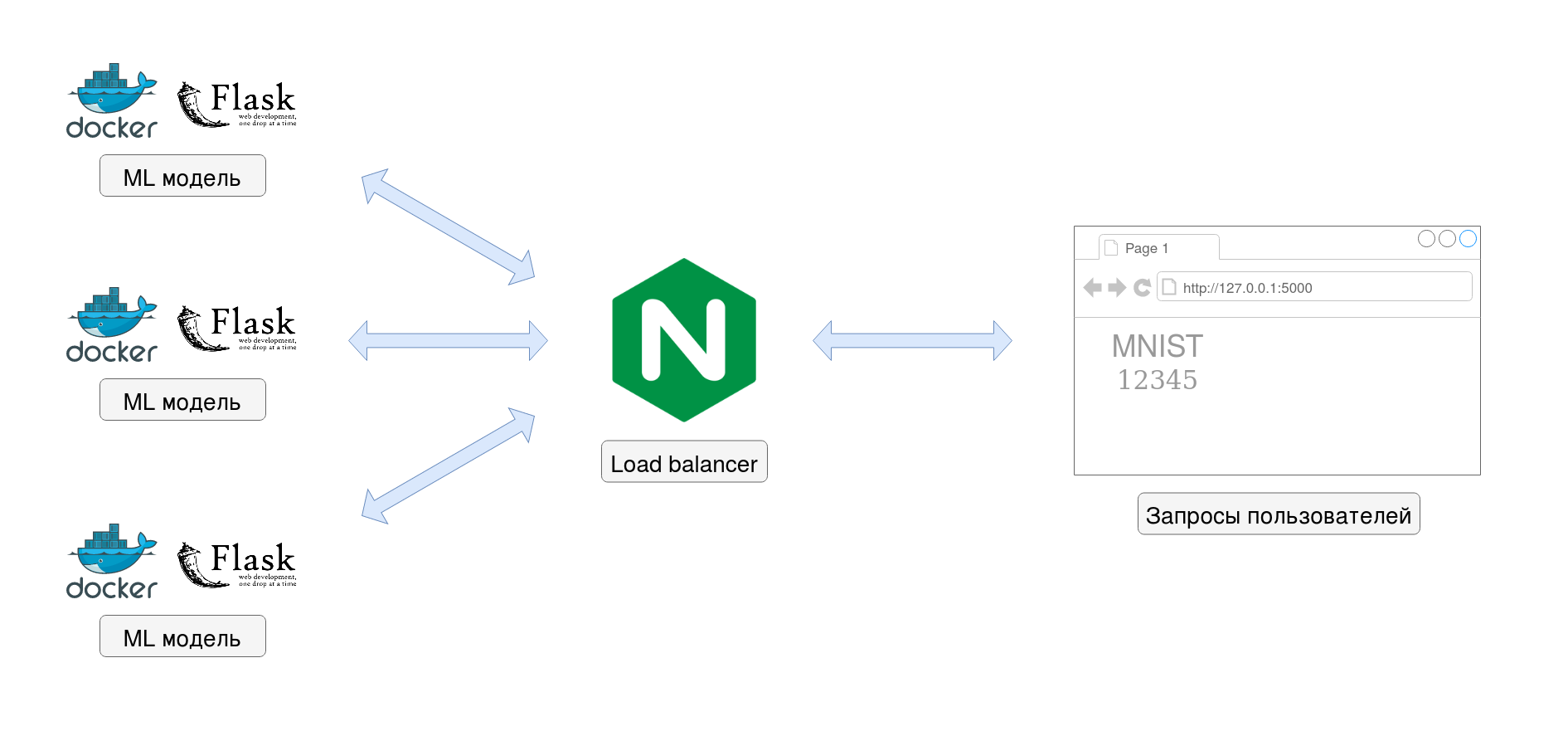
Как известно настройка и обучение моделей машинного обучения это только одна из частей цикла разработки, не менее важной частью является развертывание модели для её дальнейшего использования. В этой статье я расскажу о том, как модель машинного обучения может быть развернута в виде Docker микросервиса, а также о том, как можно распараллелить работу микросервиса с помощью распределения нагрузки в несколько потоков через Load balancer. В последнее время Docker набрал большую популярность, однако здесь будет описан только один из видов стратегий развертывания моделей, и в каждом конкретном случае выбор лучшего варианта остаётся за разработчиком.

Привет, Хабр! Меня зовут Дмитрий Адмакин, руководитель отдела архитектурных решений и перспективной разработки одного из бизнес-центров в компании «БАРС Груп». Сегодня я расскажу о том, как мы создавали современную систему мониторинга по исполнению государственных программ, и что из этого вышло.

Большинство программистов отлично разбираются в работе процессоров и последовательном программировании, поскольку с самого начала пишут код для CPU. Однако многие из них меньше знают о том, как устроены графические процессоры (GPU) и в чем заключается их уникальность. За последнее десятилетие GPU стали чрезвычайно важны благодаря широкому применению в глубоком обучении, и сегодня каждому разработчику необходимо обладать базовыми знаниями о том, как они работают. Цель этой статьи — дать вам это понимание.
Поговорим про настройку приложения для двух сред «разработки» local и условного прода. Локально приложение будет запускаться с установкой всего необходимого на компьютер, то, что дальше я буду именовать продом будет представлять из себя запуск через docker-compose.
Что это за приложение по сути значения не имеет, из особенностей — там будет celery поверх redis и Postgres, как персистентное хранилище. Код приложения можно посмотреть здесь.
Настроим переменные окружения для двух разных сред и подготовим код под это.
Настроим логирование через Loki и Grafan-у. Настроим мониторинг через Prometheus в ту же Grafan-у.
Микросервисная архитектура звучит неплохо само по себе, но еще лучше — быстрый микросервис, который эффективно использует ресурсы сервера.
Я покажу, как последовательно применять к простому без затей микросервису методы ускорения его работы, попутно рассматривая плюсы и минусы каждого из них.
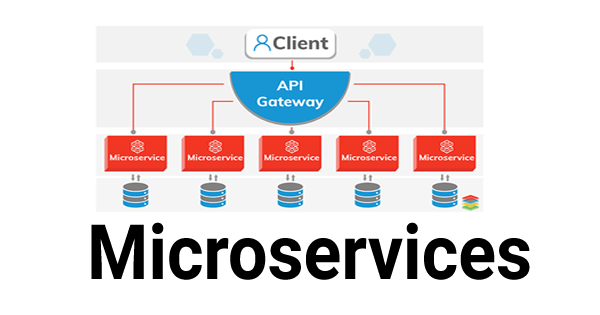
Микросервис — это подход к разбиению большого монолитного приложения на отдельные приложения, специализирующиеся на конкретной услуге/функции. Этот подход часто называют сервис-ориентированной архитектурой или SOA.
В монолитной архитектуре каждая бизнес-логика находится в одном приложении. Службы приложений, такие как управление пользователями, аутентификация и другие функции, используют одну и ту же базу данных.
В микросервисной архитектуре приложение разбивается на несколько отдельных служб, которые выполняются в отдельных процессах. Существует другая база данных для разных функций приложения, и службы взаимодействуют друг с другом с использованием HTTP, AMQP или двоичного протокола, такого как TCP, в зависимости от характера каждой службы. Межсервисное взаимодействие также может осуществляться с использованием очередей сообщений, таких как RabbitMQ , Kafka или Redis .

Если, открывая холодильник вы еще не слышали из него про RAG, то наверняка скоро услышите. Однако, в сети на удивление мало полных гайдов, учитывающих все тонкости (оценка релевантности, борьба с галлюцинациями и т.д.) а не обрывочных кусков. Базируясь на опыте нашей работы, я составил гайд который покрывает эту тему наиболее полно.
Итак зачем нужен RAG?

Краткое и понятное описание подхода RAG (Retrieval Augmented Generation) при работе с большими языковыми моделями.

Вместе с дата-сайентистом и биоинформатиком Марией Дьяковой подготовили подробный гайд о том, как устроены языковые модели и что нужно знать, чтобы начать с ними работать.
