Использование классических нейронных сетей для распознавания изображений затруднено, как правило, большой размерностью вектора входных значений нейронной сети, большим количеством нейронов в промежуточных слоях и, как следствие, большими затратами вычислительных ресурсов на обучение и вычисление сети. Сверточным нейронным сетям в меньшей степени присущи описанные выше недостатки.
Свёрточная нейронная сеть (англ.
convolutional neural network,
CNN) — специальная архитектура искусственных нейронных сетей, предложенная Яном Лекуном и нацеленная на эффективное распознавание изображений, входит в состав технологий глубокого обучения (англ.
deep leaning). Эта технология построена по аналогии с принципами работы
зрительной коры головного мозга, в которой были открыты так называемые простые клетки, реагирующие на прямые линии под разными углами, и сложные клетки, реакция которых связана с активацией определённого набора простых клеток. Таким образом, идея сверточных нейронных сетей заключается в чередовании сверточных слоев (англ.
convolution layers) и субдискретизирующих слоев (англ.
subsampling layers, слоёв подвыборки).[6]
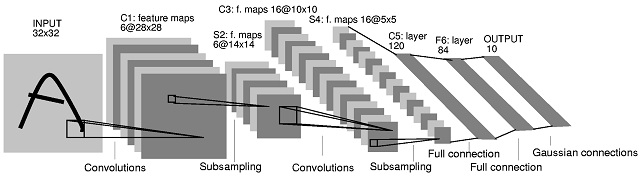
Рис 1. Архитектура сверточной нейронной сети
Ключевым моментом в понимании сверточных нейронных сетей является понятие так называемых «разделяемых» весов, т.е. часть нейронов некоторого рассматриваемого слоя нейронной сети может использовать одни и те же весовые коэффициенты. Нейроны, использующие одни и те же веса, объединяются в карты признаков (
feature maps), а каждый нейрон карты признаков связан с частью нейронов предыдущего слоя. При вычислении сети получается, что каждый нейрон выполняет свертку (
операцию конволюции) некоторой области предыдущего слоя (определяемой множеством нейронов, связанных с данным нейроном). Слои нейронной сети, построенные описанным образом, называются сверточными слоями. Помимо, сверточных слоев в сверточной нейронной сети могут быть слои субдискретизации (выполняющие функции уменьшения размерности пространства карт признаков) и полносвязные слои (выходной слой, как правило, всегда полносвязный). Все три вида слоев могут чередоваться в произвольном порядке, что позволяет составлять карты признаков из карт признаков, а это на практике означает способность распознавания сложных иерархий признаков [3].
Что же именно влияет на качество распознавания образов при обучении сверточных нейронных сетей? Озадачившись данным вопросом, наткнулись на статью Мэттью Зайлера (
Matthew Zeiler).






 Здравствуй, Хабр!
Здравствуй, Хабр!



 Для тех кто пропустил мои посты:
Для тех кто пропустил мои посты:
{kind=link}