

Как вы, возможно, слышали, в прошлом году ABBYY приобрела компанию TimelinePI – разработчика платформ Process Intelligence. Теперь, помимо интеллектуальной обработки информации, продукты ABBYY помогают компаниям решать новый класс задач – анализировать бизнес-процессы, понимать, как они устроены изнутри и как их изменить в лучшую сторону.
Для нас это логичный шаг. В недрах крупных компаний непрерывно генерируются и обрабатываются огромные объемы данных. Наши решения для корпоративных заказчиков помогают приводить в структурированный вид разнообразные сведения из бухгалтерских, кадровых, логистических и других документов и удобнее работать с ними. А почему бы не только упорядочивать информацию, но и делать на ее основе полезные выводы для бизнеса? Например, понимать, как устроены процессы, выявлять в них неочевидные закономерности, анализировать те метрики, которые раньше не учитывали, да еще и предсказывать, что будет, если автоматизировать процессы с помощью той или иной технологии?
Сегодня мы расскажем, что такое платформа для интеллектуального анализа бизнес-процессов ABBYY Timeline, для чего она нужна, и приведем примеры, как это решение работает и где оно полезно.
 Именно поэтому в 2019 году в нашей команде появился главный архитектор – человек с хорошим знанием подходов к созданию архитектуры программного обеспечения в компании сегмента B2B и с большим опытом в построении и развитии облачных сервисов. Им стал Владимир Юнев, в прошлом – облачный архитектор и эксперт по стратегическим технологиям Microsoft, известный в сообществе на Хабре как
Именно поэтому в 2019 году в нашей команде появился главный архитектор – человек с хорошим знанием подходов к созданию архитектуры программного обеспечения в компании сегмента B2B и с большим опытом в построении и развитии облачных сервисов. Им стал Владимир Юнев, в прошлом – облачный архитектор и эксперт по стратегическим технологиям Microsoft, известный в сообществе на Хабре как  Многие знают, что ABBYY занимается обработкой и извлечением данных из разных документов. Но у наших продуктов есть и другие интересные возможности. В частности, с помощью решения ABBYY Intelligent Search можно быстро и удобно искать информацию по смыслу в электронных документах из корпоративных систем. Этим уже пользуются крупные российские компании, например, производитель ракетных двигателей
Многие знают, что ABBYY занимается обработкой и извлечением данных из разных документов. Но у наших продуктов есть и другие интересные возможности. В частности, с помощью решения ABBYY Intelligent Search можно быстро и удобно искать информацию по смыслу в электронных документах из корпоративных систем. Этим уже пользуются крупные российские компании, например, производитель ракетных двигателей  Недавно завершился «
Недавно завершился « Мы регулярно обучаем
Мы регулярно обучаем 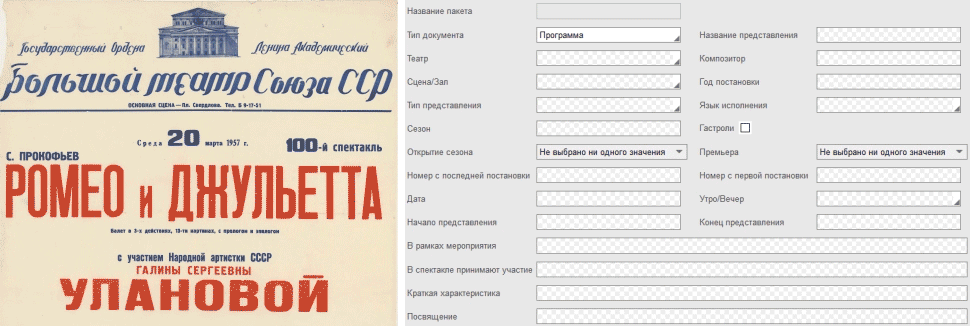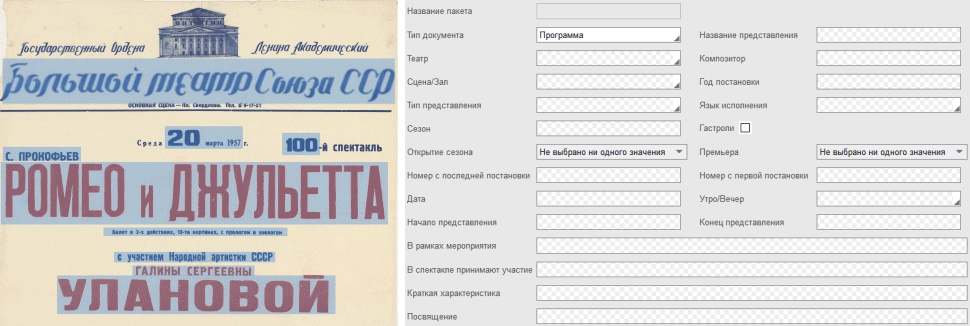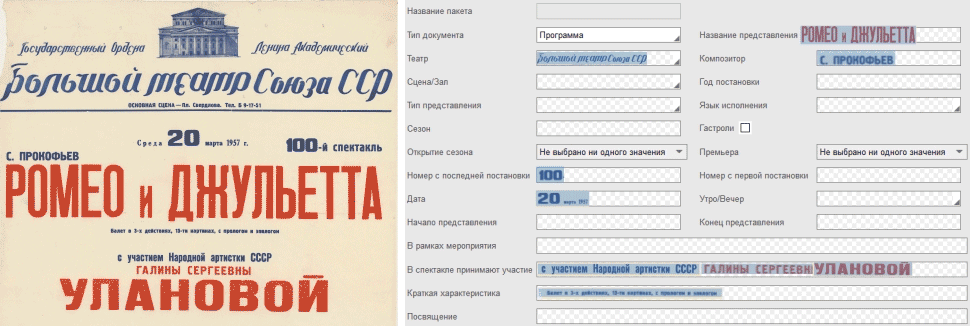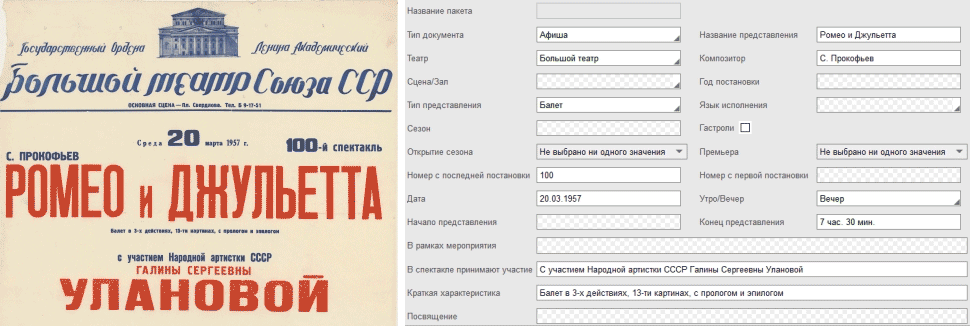
 Текущая ситуация в мире не повод останавливать диалог, особенно если его можно вести онлайн. С 17 по 20 июня состоится 26-ая Международная научная конференция по компьютерной лингвистике и интеллектуальным технологиям «
Текущая ситуация в мире не повод останавливать диалог, особенно если его можно вести онлайн. С 17 по 20 июня состоится 26-ая Международная научная конференция по компьютерной лингвистике и интеллектуальным технологиям «


 Круг задач, которые можно решить с помощью технологий ABBYY, пополнился еще одной интересной возможностью. Мы обучили свой движок работе банковского андеррайтера – человека, который из гигантского потока новостей вылавливает события о контрагентах и оценивает риски.
Круг задач, которые можно решить с помощью технологий ABBYY, пополнился еще одной интересной возможностью. Мы обучили свой движок работе банковского андеррайтера – человека, который из гигантского потока новостей вылавливает события о контрагентах и оценивает риски.  Только не удивляйтесь, но второй заголовок к этому посту сгенерировала нейросеть, а точнее алгоритм саммаризации. А что такое саммаризация?
Только не удивляйтесь, но второй заголовок к этому посту сгенерировала нейросеть, а точнее алгоритм саммаризации. А что такое саммаризация?


 Поиск объектов на изображениях? Имея обучающую выборку и минимальный набор знаний о нейросетях, любой студент сегодня может получить решение определенной точности. Однако большинство нейросетей, использующихся для решения этой задачи, достаточно глубокие, а соответственно, требуют много данных для обучения, сравнительно медленно работают на этапе inference (особенно если на устройстве отсутствует GPU), много весят и достаточно энергозатратны. Все вышеперечисленное может быть весьма критично в определенных случаях, в первую очередь, для мобильных приложений.
Поиск объектов на изображениях? Имея обучающую выборку и минимальный набор знаний о нейросетях, любой студент сегодня может получить решение определенной точности. Однако большинство нейросетей, использующихся для решения этой задачи, достаточно глубокие, а соответственно, требуют много данных для обучения, сравнительно медленно работают на этапе inference (особенно если на устройстве отсутствует GPU), много весят и достаточно энергозатратны. Все вышеперечисленное может быть весьма критично в определенных случаях, в первую очередь, для мобильных приложений.
 Как правило, наше «Лето» начинается еще в конце мая с двухдневного автопробега ABBYY Road. И если вы записались на него, то с большой вероятностью попадете в компанию людей, которые нечасто пересекаются по работе, из разных проектов и подразделений – от разработчиков, product owner’ов и дизайнеров до юристов и маркетологов. И во время путешествия ничего не мешает им познакомиться. А еще самому куда-то собраться бывает лениво. Гораздо удобнее, когда продумать маршрут и организовать поездку помогают более опытные путешественники.
Как правило, наше «Лето» начинается еще в конце мая с двухдневного автопробега ABBYY Road. И если вы записались на него, то с большой вероятностью попадете в компанию людей, которые нечасто пересекаются по работе, из разных проектов и подразделений – от разработчиков, product owner’ов и дизайнеров до юристов и маркетологов. И во время путешествия ничего не мешает им познакомиться. А еще самому куда-то собраться бывает лениво. Гораздо удобнее, когда продумать маршрут и организовать поездку помогают более опытные путешественники. 

 В этом году четыре группы организаторов подготовили такие дорожки:
В этом году четыре группы организаторов подготовили такие дорожки: С 29 мая по 1 июня в Российском государственном гуманитарном университете (РГГУ) пройдет 25-ая международная научная конференция по компьютерной лингвистике и интеллектуальным технологиям «
С 29 мая по 1 июня в Российском государственном гуманитарном университете (РГГУ) пройдет 25-ая международная научная конференция по компьютерной лингвистике и интеллектуальным технологиям «