
Двоичная куча (binary heap) – просто реализуемая структура данных, позволяющая быстро (за логарифмическое время) добавлять элементы и извлекать элемент с максимальным приоритетом (например, максимальный по значению).
Для дальнейшего чтения необходимо иметь представление о деревьях, а также желательно знать об оценке сложности алгоритмов. Алгоритмы в этой статье будут сопровождаться кодом на C#.
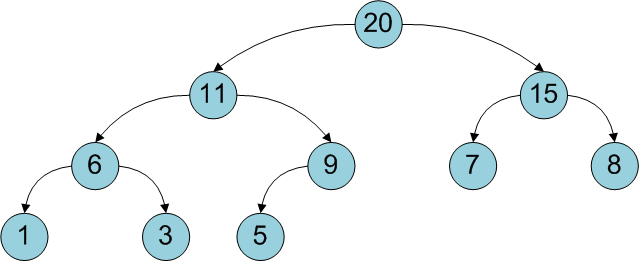
Двоичная куча представляет собой полное бинарное дерево, для которого выполняется основное свойство кучи: приоритет каждой вершины больше приоритетов её потомков. В простейшем случае приоритет каждой вершины можно считать равным её значению. В таком случае структура называется max-heap, поскольку корень поддерева является максимумом из значений элементов поддерева. В этой статье для простоты используется именно такое представление. Напомню также, что дерево называется полным бинарным, если у каждой вершины есть не более двух потомков, а заполнение уровней вершин идет сверху вниз (в пределах одного уровня – слева направо).
Для дальнейшего чтения необходимо иметь представление о деревьях, а также желательно знать об оценке сложности алгоритмов. Алгоритмы в этой статье будут сопровождаться кодом на C#.
Введение
Двоичная куча представляет собой полное бинарное дерево, для которого выполняется основное свойство кучи: приоритет каждой вершины больше приоритетов её потомков. В простейшем случае приоритет каждой вершины можно считать равным её значению. В таком случае структура называется max-heap, поскольку корень поддерева является максимумом из значений элементов поддерева. В этой статье для простоты используется именно такое представление. Напомню также, что дерево называется полным бинарным, если у каждой вершины есть не более двух потомков, а заполнение уровней вершин идет сверху вниз (в пределах одного уровня – слева направо).

{kind=link}