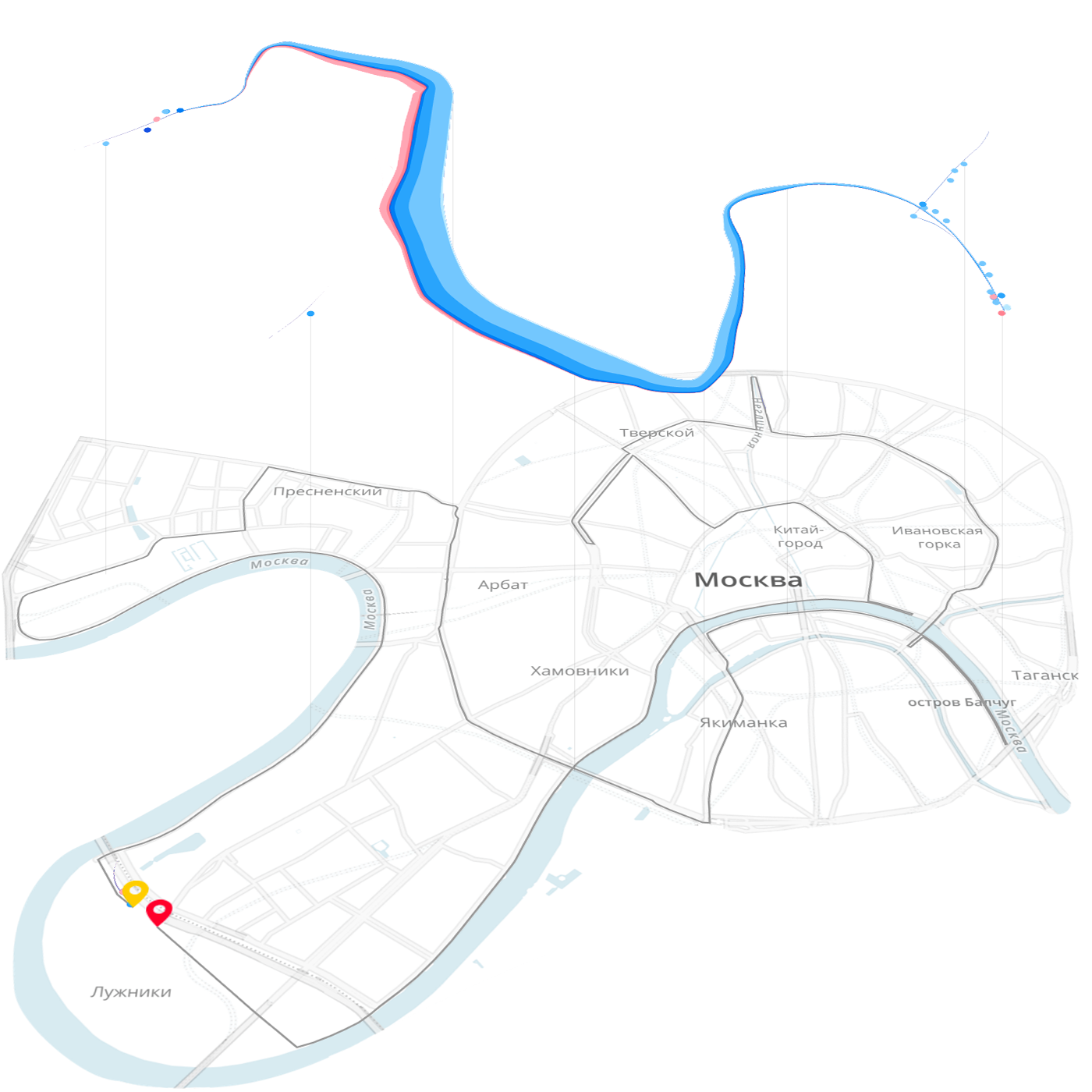
За три года существования Лаборатория данных выпустила около тридцати интерактивных визуализаций, в формате заказных, собственных проектов и бесплатных советов. Мы в лаборатории визуализируем финансовые и научные данные, данные городской транспортной сети, результаты забегов, эффективность маркетинговых кампаний и многое другое. Весной мы получили бронзовую медаль на престижной премии Malofiej 24 за визуализацию результатов Московского марафона.
Последние полгода я работаю над алгоритмом визуализации данных, который систематизирует этот опыт. Моя цель — дать рецепт, который позволит разложить любые данные по полочкам и решать задачи по визуализации данных также чётко и последовательно, как математические задачи. В математике не важно, складывать яблоки или рубли, распределять кроликов по ящикам или бюджеты на рекламные кампании — есть стандартные операции сложения, вычитания, деления и т.д. Я хочу создать универсальный алгоритм, который поможет визуализировать любые данные, при этом учитывает их смысл и уникальность.
Я хочу поделиться с читателями Хабра результатами своих исследований.
Последние полгода я работаю над алгоритмом визуализации данных, который систематизирует этот опыт. Моя цель — дать рецепт, который позволит разложить любые данные по полочкам и решать задачи по визуализации данных также чётко и последовательно, как математические задачи. В математике не важно, складывать яблоки или рубли, распределять кроликов по ящикам или бюджеты на рекламные кампании — есть стандартные операции сложения, вычитания, деления и т.д. Я хочу создать универсальный алгоритм, который поможет визуализировать любые данные, при этом учитывает их смысл и уникальность.
Я хочу поделиться с читателями Хабра результатами своих исследований.