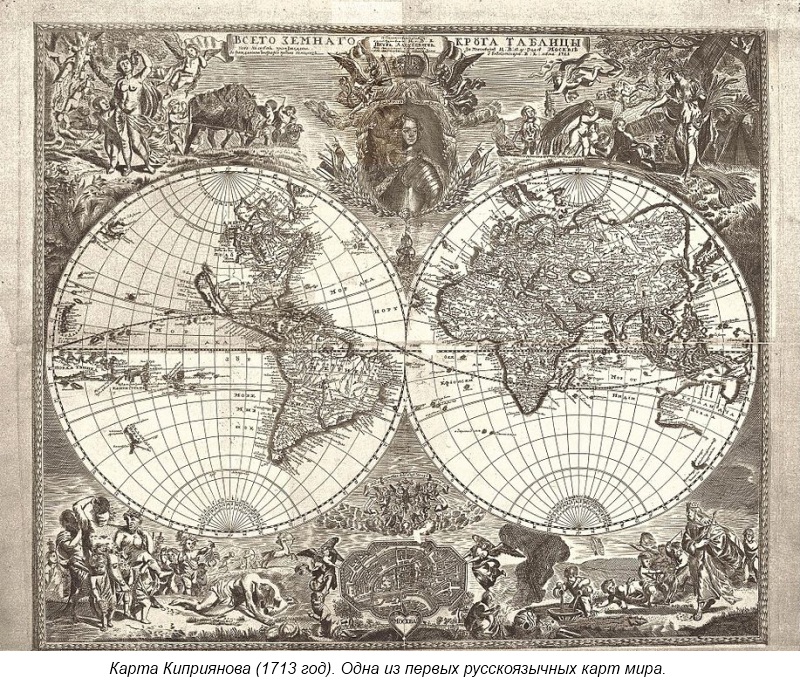
На сайте Internet Census 2012 internetcensus2012.bitbucket.org опубликованы результаты сканирования всех существующих IPv4 адресов. Сканирование такого масштаба удалось осуществить благодаря ботнету из 420 тысяч незащищенных устройств.

User





В Coursera мы представляем себе будущее в котором каждый имеет доступ к образованию мирового класса. Мы стараемся найти и поделиться способами преодоления барьеров, которые стоят на пути успешного обучения. Сегодня мы объявляем о новой инициативе Learning Hubs (места для обучения) — которые будут предоставлять людям во всем мире физическое пространство, где они могут получить доступ к Интернету, чтобы записаться на курс от Coursera и изучить его вместе со сверстниками. Все совершенно бесплатно.


 coviolations.io — сервис для визуализации результатов тестов и анализаторов кода сегодня перешёл в стадию beta.
coviolations.io — сервис для визуализации результатов тестов и анализаторов кода сегодня перешёл в стадию beta.nofail, nocomment и stderr в .covio.yml.