Поговорим про способы жульничества в Data Science.

Data Scientist

Любая крупная компания представляет собой множество обособленных или взаимосвязанных процессов, которые решают задачи различной направленности. Как правило, любой процесс является сложным механизмом взаимодействия людей, сервисов или других компаний, от которых зависит конечный результат исполняемого процесса. Перерывы в поставках ресурсов, изъяны в сервисах и алгоритмах, длительные исполнение простых операций или их повторное выполнение и многие другие факторы приводят к дополнительным экономическим издержкам и накоплению негативного клиентского опыта. Таким образом, анализ процессов и устранение недостатков в них — одна из важных составляющих для успешного ведения бизнеса.
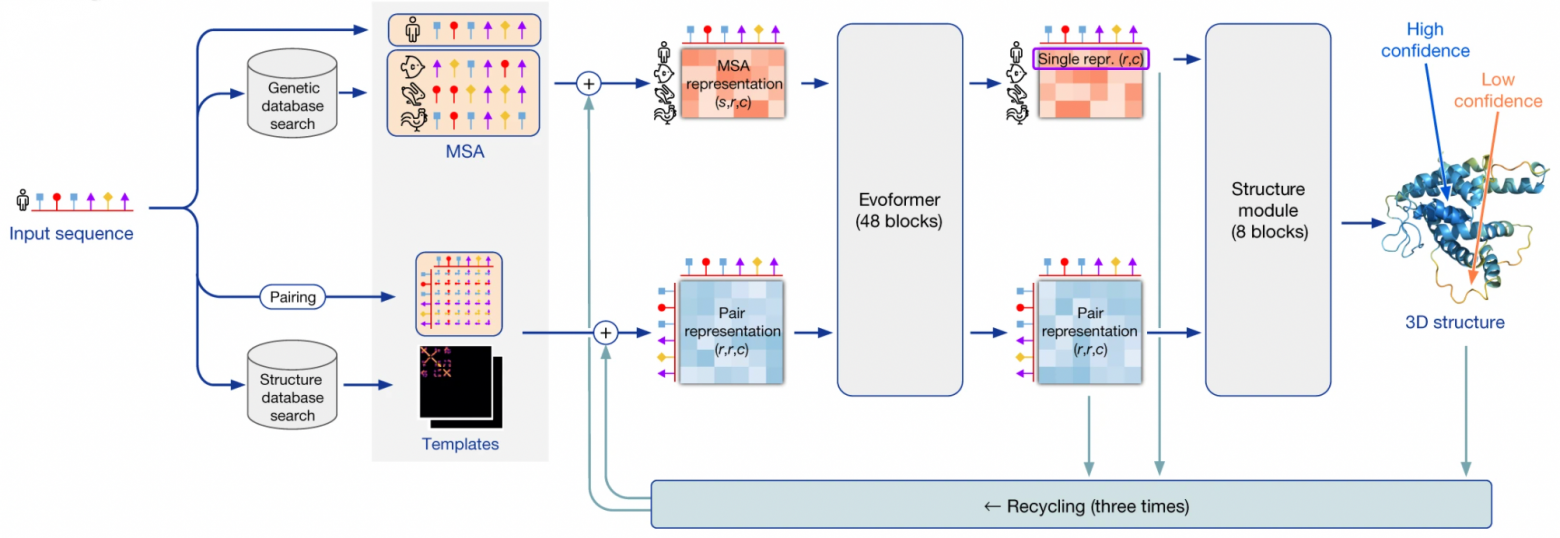
На мой взгляд DeepMind AlphaFold2 и Github Copilot являются одними из самых значимых достижений науки и техники в 2021 году. Спустя два года после их первоначального прорыва команда из DeepMind фактически смогла решить (с небольшими оговорками) задачу фолдинга белка, остававшуюся нерешенной более 50 лет. В этом посте я подробно разбираю устройство данной системы.

К моему удивлению, в открытом доступе оказалось не так уж много подробных и понятных объяснений того как работает модель GPT от OpenAI. Поэтому я решил всё взять в свои руки и написать этот туториал.
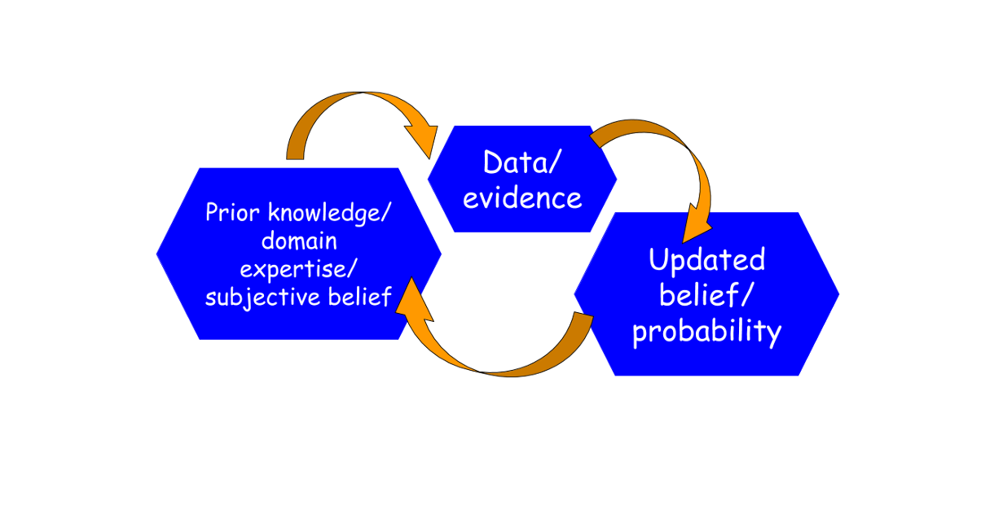
В этой статье мы рассказываем об основах и применении одного из самых мощных законов статистики - теоремы Байеса.
Мы продемонстрируем применение правила Байеса на очень простом, но практичном примере тестирования на наркотики и реализуем расчеты на языке програмирования Python. Мы также проиллюстрируем, как ограничения теста влияют на прогнозируемую вероятность и что в тесте необходимо улучшить, чтобы получить результат с высокой степенью достоверности.
Мы также покажем истинную силу байесовских рассуждений и как несколько байесовских вычислений можно объединить в цепочку, чтобы вычислить общую апостериорную вероятность.
Меня зовут Юля, я разработчик команды ETNA. Расскажу о том, как мы запустили открытый инструмент для аналитики и прогнозирования бизнес-процессов, как он устроен и как его использовать.
В Тинькофф мы часто решаем задачи по прогнозированию: хотим знать количество звонков на линии обслуживания или сколько наличных клиенты снимут в банкомате на следующей неделе. Специалисты по обработке данных и аналитики, которые сталкиваются с проблемами прогнозирования, могут использовать целый ряд различных инструментов для своей работы. Это неудобно и требует времени. Чтобы упростить задачу, мы разработали наш фреймворк.



Всех с наступающими праздниками! Надеюсь, каждый отдохнёт и восполнит силы за праздничные дни, а не будет зависать за очередными багами/фичами/обновлениями!
Помню, лет так 12 назад, когда я был ещё школьником, у всех моих знакомых стояла windows XP. И в моменты нового года у нас была традиция, скачать на каком-нибудь сайте новогоднюю ёлочку, которая запускается отдельной программой и просто на рабочем столе (либо на любом другом окне, если её открыть поверх окон) играет гифка с этой ёлочкой. Мелочь, но к новогоднему настроению она давала в те года +100 очков.
Если раньше такую штуку приходилось искать, где скачать, то теперь пришло время сделать всё самому.
Приступим к написанию своей версии "ёлочки"

Статья не про майнинг и не для майнеров.
Недавно на Хабре была статья про сравнение карточек для вычислений. На мой взгляд статья получилась очень даже неплохой, но в ней никак не отразили позиции RTX 3090 Turbo и как-то подозрительно мало времени уделили А10.
На мой взгляд среди карточек с "большим" объемом памяти (более 12 гигабайт) по рекомендованной рыночной цене (РРК) 3090 является лидером хит-парада, а по рыночной цене — скорее уже А10. Детальный разбор почему и как я подходил к выбору карточек и тестированию — прошу под кат.
Также так случилось, что у меня под рукой оказалось большое количество рейзеров разной степени говённости. И сначала я замахивался, чтобы поставить некую точку в вечных дебатах про райзеры (а мнения разнятся от такого до банального "не работает" или "для DL нельзя использовать"), но в итоге все получилось чуть более сумбурно. Но я постарался подойти к тестированию райзеров тоже структурированно и аналитически.
И последнее — в прошлой статье я сокрушался, что мол нет на рынке большого выбора однослотовых решений по вменяемой цене. Теперь на выбор решений много, но с доступностью и ценами ситуация лучше не стала (есть как минимум 2 поколения карточек Quadro и Tesla A10, но геймерских нет, насколько я знаю).

Совсем недавно команда исследователей из компании DeepMind, которая специализируется на разработке различных ИИ-алгоритмов, опубликовала интересную научную статью. Она называется "Advancing mathematics by guiding human intuition with AI" и опубликована в авторитетном научном журнале Nature. В ней затрагивается вопрос интуиции человека и машинного обучения.
Многие специалисты уже обратили внимание на статью, причем часть из них считают работу DeepMind прорывом, а часть - обычным исследованием, значение которого преувеличивается журналистами. Но как бы там ни было, а сама работа весьма интересна, поскольку ее результаты дают возможность расширить инструментарий математиков. Речь идет о демонстрации сложных корреляций в одной из гипотез теории узлов из абстрактной математики. Кроме того, алгоритм от DeepMind нашел применение в изучении комбинаций белковых последовательностей. Необычным во всем этом является то, что для решения указанных задач ИИ от DeepMind показал признаки "сильного ИИ".


Привет! Меня зовут Максим Бондарев, я работаю младшим разработчиком в компании Digital Design и заканчиваю обучение на математико-механическом факультете СПбГУ. В рамках своей исследовательской работы я занимался решением задачи по автоматической генерации протоколов совещаний в составе команды научной лаборатории (aka Конструкторское Бюро) под руководством Максима Панькова. Что из этого получилось, и над чем еще предстоит поработать, расскажу в этой статье.
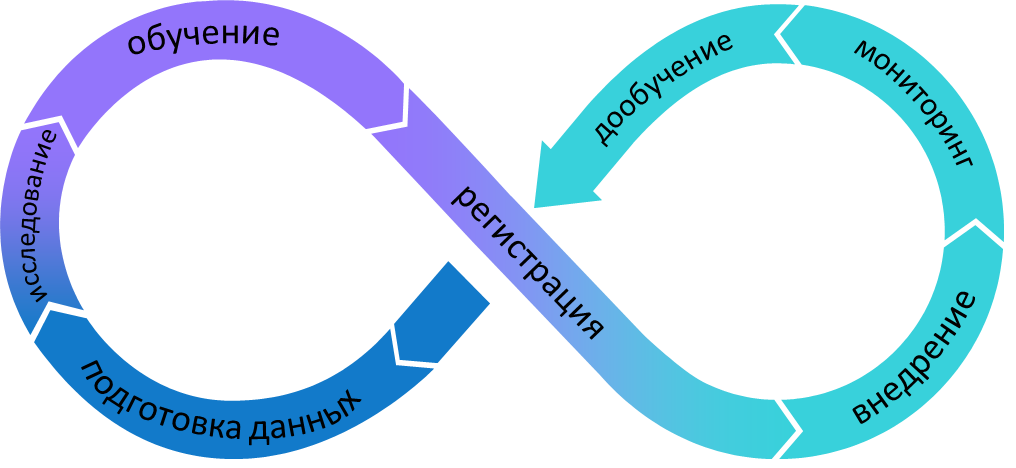

В июле этого года AliExpress сообщил о новом инструменте, который с помощью машинного обучения автоматизирует и ускоряет загрузку товаров на платформу. Этот же способ подходит интернет-магазинам, чтобы выгрузить информацию о товарах из внутренних баз на сайты. Мы поделимся с вами инструментом, который в сотни раз ускоряет категоризацию и загрузку товаров. Расскажем и о том, как и для чего создавали модель категоризации, используя машинное обучение.
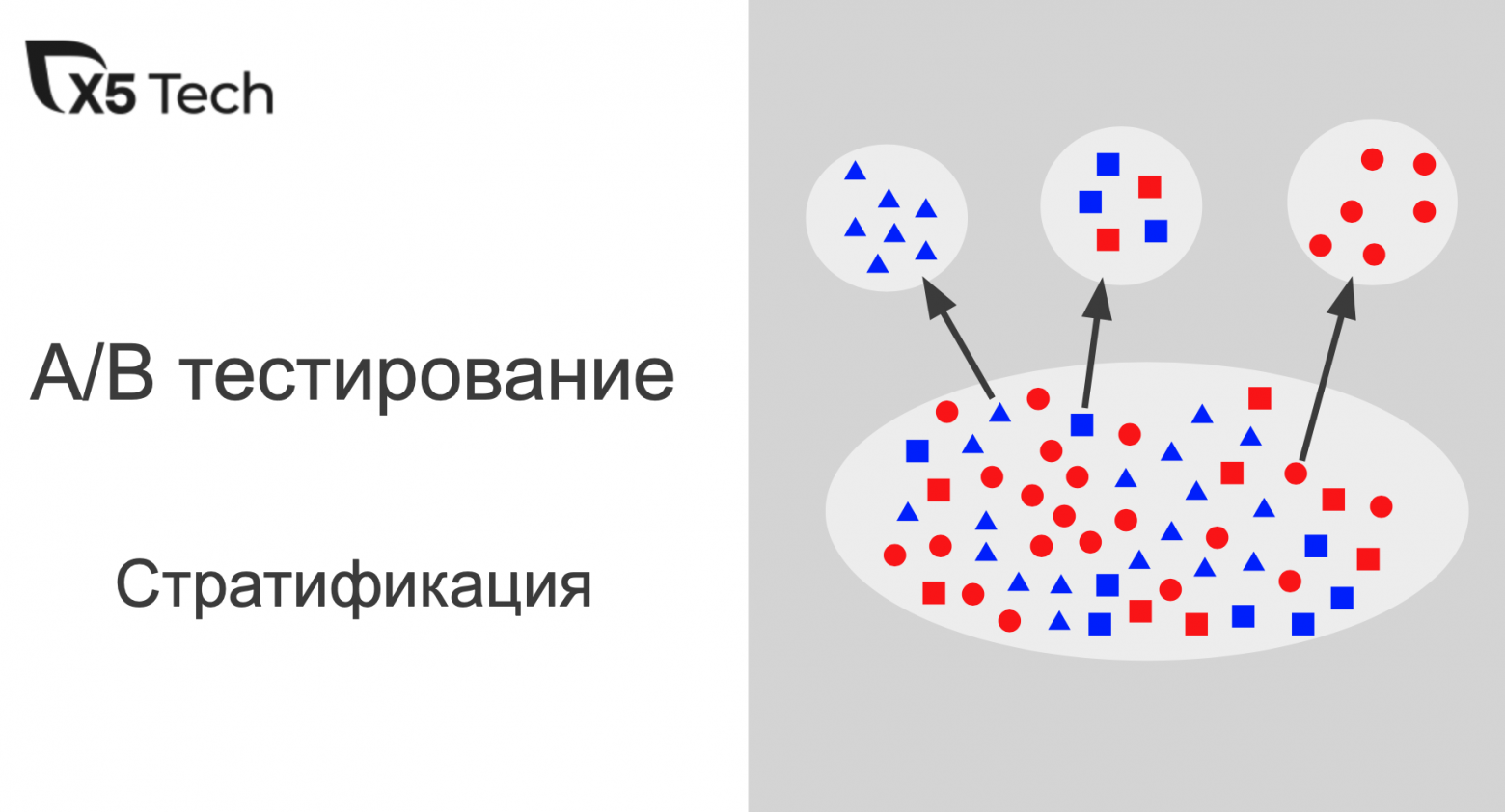
Всем привет! На связи команда ad-hoc аналитики X5 Tech.
Сегодня подробно обсудим применение стратификации для повышения чувствительности оценки AB экспериментов.

В этой статье рассмотрим особенности тестирования мобильных приложений с помощью эмуляторов/симуляторов и на реальных устройствах.
Содержание:
Что такое мобильные эмуляторы и симуляторы;
Типы мобильных тестов;
Инструменты/фреймворки автоматизации мобильного тестирования;
Когда можно использовать эмуляторы/симуляторы, а а когда — стоит тестировать на реальных устройствах.

Статья написана по мотивам работы "Forecasting SQL Query Cost at Twitter", 2021 («Прогнозирование стоимости SQL-запросов в Twitter»), представленной на IX Международной конференции IEEE по облачной инженерии (IC2E). Подробностями делимся, пока у нас начинается курс по Machine Learning и Deep Learning.
