
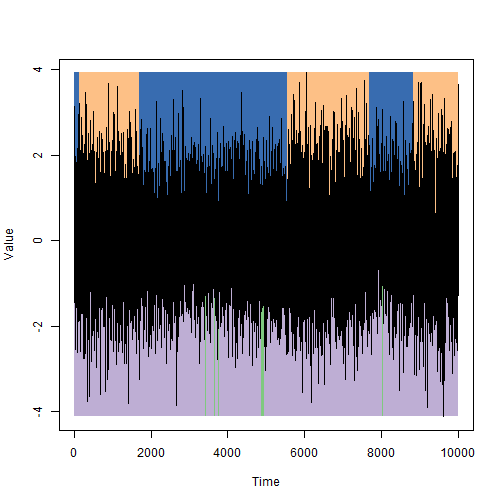
В посте подробно рассматривается техника генерации случайных подземелий. Основной алгоритм генерации, пример работы которого можно
посмотреть здесь, используется разработчиками игры
TinyKeep. Оригинальный пост от разработчика
был размещён на reddit.
Оригинальное описание алгоритма
1. Сначала я задаю нужное количество комнат – к примеру, 150. Естественно, цифра произвольная, и чем она больше, тем сложнее будет подземелье.
2. Для каждой комнаты я создаю прямоугольник со случайными шириной и высотой, находящимися в пределах заданного радиуса. Радиус не имеет большого значения, хотя разумно предположить, что он должен быть пропорционален количеству комнат.
Вместо равномерно распределённых случайных чисел (какие выдаёт генератор Math.random в большинстве языков), я использую
нормальное распределение Парка-Миллера. В результате вероятность появления маленьких комнат превышает вероятность появления больших. Зачем это надо, объясню позже.
Кроме того я проверяю, что соотношение длины и ширины комнаты не слишком велико. Нам не нужны как идеально квадратные комнаты, так и сильно вытянутые.
3. И вот у нас есть 150 случайных комнат, расположенных на небольшом пространстве. Большинство из них наезжают друг на друга. Теперь мы осуществляем их разделение по технологии separation steering, чтобы разделить прямоугольники так, чтоб они не пересекались. В результате они не пересекаются, но находятся достаточно близко друг от друга.
4. Заполняем промежутки клетками размером 1х1. В результате у нас получается квадратная решётка из комнат различного размера.
5. И тут начинается основное веселье. Определяем, какие из клеток решётки являются комнатами – это будут любые клетки с шириной и высотой, превышающими заданные. Из-за распределения Парка-Миллера мы получим сравнительно небольшое количество комнат, между которыми есть довольно много свободного пространства. Но оставшиеся клетки нам также пригодятся.
6. Следующий шаг – связывание комнат вместе. Для этого мы строим граф, содержащий центры всех комнат при помощи
триангуляции Делоне. Теперь все комнаты связаны меж собой непересекающимися линиями.
7. Поскольку нам не нужно, чтобы все комнаты были связаны со всеми, мы строим
минимальное остовное дерево. В результате получается граф, в котором гарантированно можно достичь любой комнаты.
8. Дерево получается аккуратным, но скучным – никаких вам замкнутых ходов. Поэтому мы случайным образом добавляем обратно примерно 15% ранее исключённых рёбер графа. В результате получится граф, где все комнаты гарантированно достижимы, с несколькими замкнутыми ходами.
9. Чтобы превратить его в коридоры, для каждого ребра строится серия прямых линий (в форме Г), идущих по рёбрам графа, соединяющим комнаты. Тут нам пригождаются те клетки, которые остались неиспользованными (те, что не превратились в комнаты). Все клетки, накладывающиеся на Г-образные линии, становятся коридорами. А из-за разнообразия размеров клеток стены коридоров будут неровными, что как раз хорошо для подземелья.
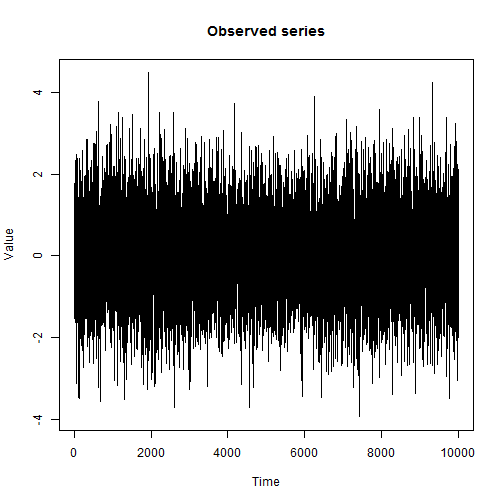
И вот
пример результата!
Осторожно — под катом много
монстров анимированных гифок!




 Для быстрой обработки пакетов требуется обнаруживать битовые шаблоны и быстро (со скоростью работы канала) принимать решения о нужных действиях на основе наличных битовых шаблонов. Эти битовые шаблоны могут принадлежать одному из нескольких заголовков, присутствующих в пакете, которые, в свою очередь, могут находиться на одном из нескольких уровней, например Ethernet, VLAN, IP, MPLS или TCP/UDP. Действия, определяемые по битовым шаблонам, могут различаться — от простого перенаправления пакетов в другой порт до сложных операций перезаписи, для которых требуется сопоставление заголовка пакета из одного набора протоколов с другими. К этому следует добавить функции управления трафика и политик трафика, брандмауэры, виртуальные частные сети и т. п., вследствие чего сложность операций, которые необходимо выполнять с каждым пакетом, многократно возрастает.
Для быстрой обработки пакетов требуется обнаруживать битовые шаблоны и быстро (со скоростью работы канала) принимать решения о нужных действиях на основе наличных битовых шаблонов. Эти битовые шаблоны могут принадлежать одному из нескольких заголовков, присутствующих в пакете, которые, в свою очередь, могут находиться на одном из нескольких уровней, например Ethernet, VLAN, IP, MPLS или TCP/UDP. Действия, определяемые по битовым шаблонам, могут различаться — от простого перенаправления пакетов в другой порт до сложных операций перезаписи, для которых требуется сопоставление заголовка пакета из одного набора протоколов с другими. К этому следует добавить функции управления трафика и политик трафика, брандмауэры, виртуальные частные сети и т. п., вследствие чего сложность операций, которые необходимо выполнять с каждым пакетом, многократно возрастает.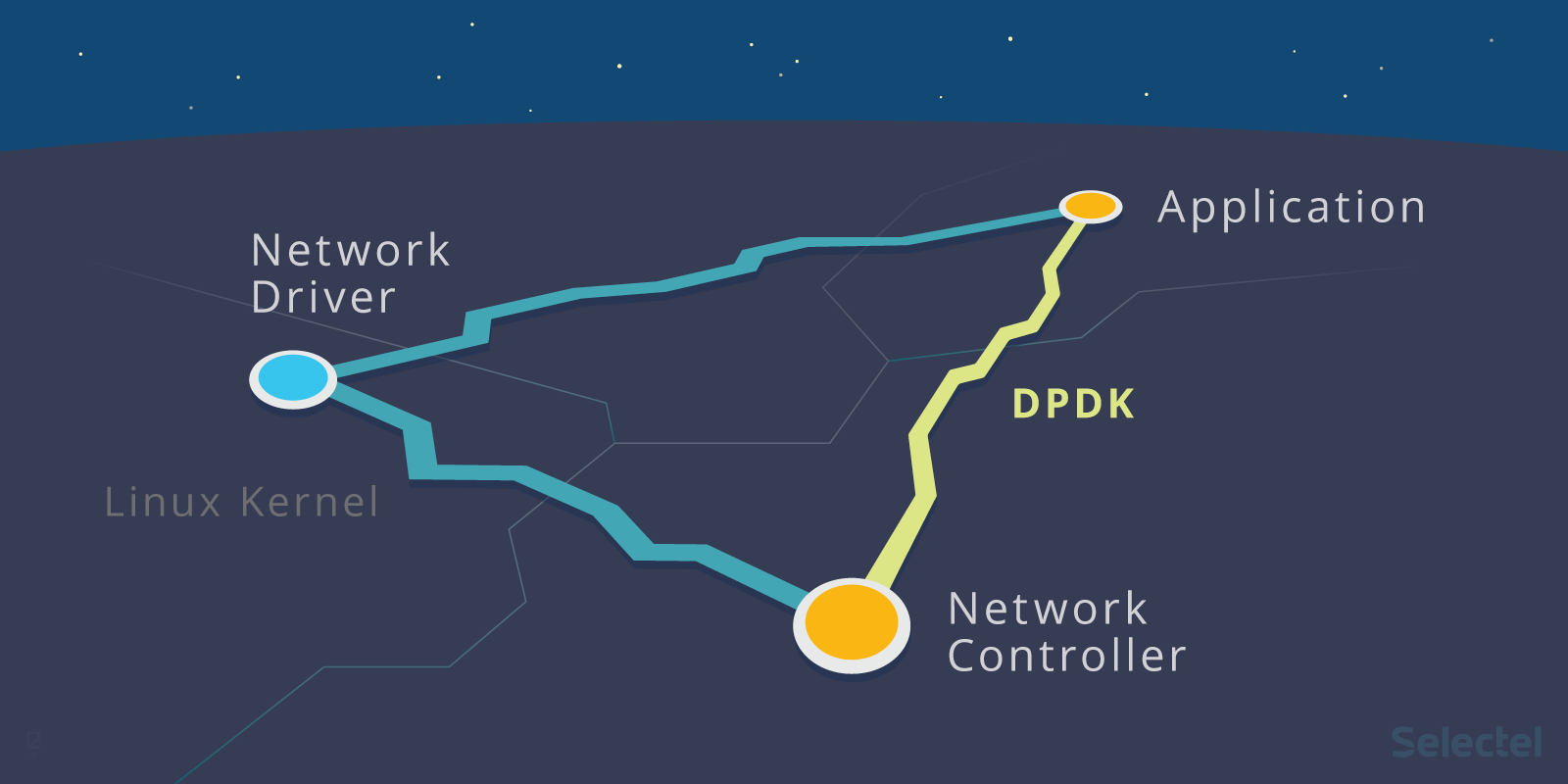


 Недавно я работал над новой C#-диагностикой V3119 для статического анализатора PVS-Studio. Назначение диагностики — выявление потенциально небезопасных конструкций в исходном коде C#, связанных с использованием виртуальных и переопределенных событий. Давайте попробуем разобраться: что же не так с виртуальными событиями в C#, как именно работает диагностика и почему Microsoft не рекомендует использовать виртуальные и переопределенные события?
Недавно я работал над новой C#-диагностикой V3119 для статического анализатора PVS-Studio. Назначение диагностики — выявление потенциально небезопасных конструкций в исходном коде C#, связанных с использованием виртуальных и переопределенных событий. Давайте попробуем разобраться: что же не так с виртуальными событиями в C#, как именно работает диагностика и почему Microsoft не рекомендует использовать виртуальные и переопределенные события?

{kind=link}