В этой статье я расскажу как построить простой пайплайн для деплоя Spring Boot проекта на сервере используя GitHub Actions и Docker.

Пользователь
В этой статье я расскажу как построить простой пайплайн для деплоя Spring Boot проекта на сервере используя GitHub Actions и Docker.

То и дело, прожигая время за чтением reddit, я натыкаюсь на очередной пост, в котором упоминается метод S3 FIFO и говорится, что он лучше LRU (вытеснение реже всего используемых значений) — потому, что даёт более низкий процент промахов кэша. Видные компании, в частности, RedPandas, Rising Wave и Cloudflare уже внедрили S3 FIFO у себя на различных мощностях, что только подогрело мой интерес к нему. Кэши — чертовски интересная тема, а по работе мне приходится сильно полагаться на работу с кэшами при обслуживании нескольких сервисов. Так что я был уверен, что рано или поздно мне потребуется протестировать S3 FIFO или, как минимум, удостовериться, что я понимаю ключевые идеи, заложенные в этой технологии.
Правда, казалось, что рановато с головой погружаться в изучение нового подхода к кэшированию, пока ещё досконально не разобрался в аналогичной системе, с которой приходится иметь дело на работе сейчас. У нас в команде для работы с кэшированием используется библиотека Caffeine, и, положа руку на сердце, я не ориентировался в её внутреннем устройстве, не пытался проверить, можно ли в ней что-нибудь подкрутить, и есть ли в ней параметры, поддающиеся тонкой настройке. В этой статье я попробую законспектировать мои изыскания и рассказать, как на собственном опыте разбирался во внутреннем устройстве библиотеки Caffeine.
Все желающие приглашаются в путешествие с разбором сложностей одной из наиболее востребованных систем кэширования, используемых в мире. Будь вы бывалый инженер или просто новичок, интересующийся продвинутыми механизмами кэширования, это исследование прольёт вам свет на многие вопросы и подведёт к важным практическим выводом. Поехали!

Технические доклады могут быстро устаревать и становиться невостребованными. Но со «Spring-потрошителем» Евгения Борисова получилось совсем иначе: мы провели мероприятие и опубликовали запись ещё 11 лет назад, а её просмотры по-прежнему растут, и уже перевалили за за 500 000. Перед собеседованиями этот доклад порой штудируют обе стороны: соискатели — чтобы подтянуть матчасть, работодатели — чтобы задать заковыристые вопросы.
В общем, получился главный доклад русскоязычного Java-сообщества. И теперь мы решили, что ему будет полезна ещё и текстовая версия на Хабре. Да, что-то в материале устарело (там речь заходит ещё про Java 7), так что делайте поправку на возраст. Но раз этот материал продолжают смотреть в видеоформате, то и возможность делать Ctrl+F кому-то наверняка пригодится.
А если кому-то хочется более свежих Java-докладов — мы тем временем вовсю готовим конференцию JPoint 2025 (пройдёт уже 3-4 апреля).
Далее повествование ведется от лица спикера.

«Ничего не делаю, поскольку мотивации не хватает. Где бы взять мотивацию?» — так рассуждают многие, не понимая, что сама идея гнаться за мотивацией — ошибочна, ведь целей вы не достигаете совсем по другим причинам. По каким же?

Привет, меня зовут Иван, и я зануда.
Сразу скажу, что в моем понимании зануда в тестировании — не тот человек, который всех достал и которого все хотят удушить, а тот, который умеет показать людям, что нужно делать хорошо и не делать плохо, и добиться от них этого. Я считаю, что QA должно расшифровываться как Quality Assistant. Это даже не про Assurance, когда вы обеспечиваете качество, это именно про то, что вы как тестировщик и участник команды помогаете на каждом этапе от требований до выкатки в прод и работы с сопровождением и вашими коллегами добиться того, чтобы каждый этап проходил все лучше и лучше.
В тестировании я уже семь лет, для кого-то это маленький срок, для кого-то — большой, я очень впечатлен коллегами, которые работают уже по 15-20 лет, но развиваюсь, стараюсь нести добро в массы. Одна из моих основных специализаций заключается в том, что я прихожу на проекты, которые начинаются с большой бизнес-идеи, движущейся через много команд. Мне нравятся все вопросы межкомандного тестирования, интеграционного взаимодействия, выстраивания стендов, как драйвить коллег, чтобы мы двигались в одном направлении и не словили на проде кучу ошибок — этим я и занимаюсь.
В связи с этим я часто замечаю, что многие команды и коллеги приходят на интеграционные стенды, мы выкатываемся на те стенды, где начинают работать настоящие сервисы на тестовых средах. Я у коллег вижу такие банальные ошибки, которые нельзя было бы пропустить, если бы мы тестировались изолированно на каком-то отдельном кусочке, проверяя свои интеграции еще до поездки на тестовый стенд. Естественно, чем позже мы находим ошибку, тем больше стоимость ее исправления, поэтому нам нужны моки, чтобы мы все это проверяли.

Оптимизация SQL-запросов является одной из ключевых задач при работе с реляционными базами данных. Эффективные SQL-запросы позволяют значительно улучшить производительность приложений и обеспечить более быстрый доступ к данным. В данной статье мы рассмотрим как переписать запрос, чтобы выполнялся быстрее. В статье пойдет речь о PostgreSQL, хотя применять данные советы к любой базе данных SQL Ниже будут представлены термины и операторы, о которых пойдет в данной статье.

Привет, Хабр!
Меня зовут Олег, я работаю разработчиком в одной крупной IT-компании и недавно в разговоре со знакомыми логистами, я узнал, что у них в штате работает блокчейн-специалист. Для меня мир логистики был максимально далек от цепочки блоков, как и цепочка блоков от меня, поэтому я решил погрузиться в эту технологию.
Прочитав множество статей и несколько книг, я выяснил, что теория с практикой идут рядышком, но понимание того, как же блокчейн работает на самом деле, не пришло, поэтому было решено создать что-то с нуля своими ручками.
Нужно понимать, что между наработками, которые я буду рассматривать, и «настоящим» блокчейном есть большая разница: на ранних этапах разработки блокчейн-сеть может иметь низкую производительность, уязвимости и неоптимизированные механизмы консенсуса, которые улучшатся в финальной версии. Но в любом случае этот проект будет основан на ключевых принципах децентрализованных систем. Мой пост будет полезен для таких же новичков, как я, которые имеют некоторый опыт разработки, но с технологией блокчейн не были знакомы или слышали про него краем уха. В этой статье мы рассмотрим, как создать простую приватную сеть блокчейн с использованием языка Go.

Сейчас OpenTelemetry — это самый быстрорастущий проект CNCF. Опытом внедрения этого набора инструментов для отладки и анализа производительности распределённых систем поделился тимлид платформенной команды Норвежского управления труда и социального обеспечения. В переводе под катом вас ждёт тернистый путь от первых коммитов до реального применения OpenTelemetry в production, а также планы команды на будущее.
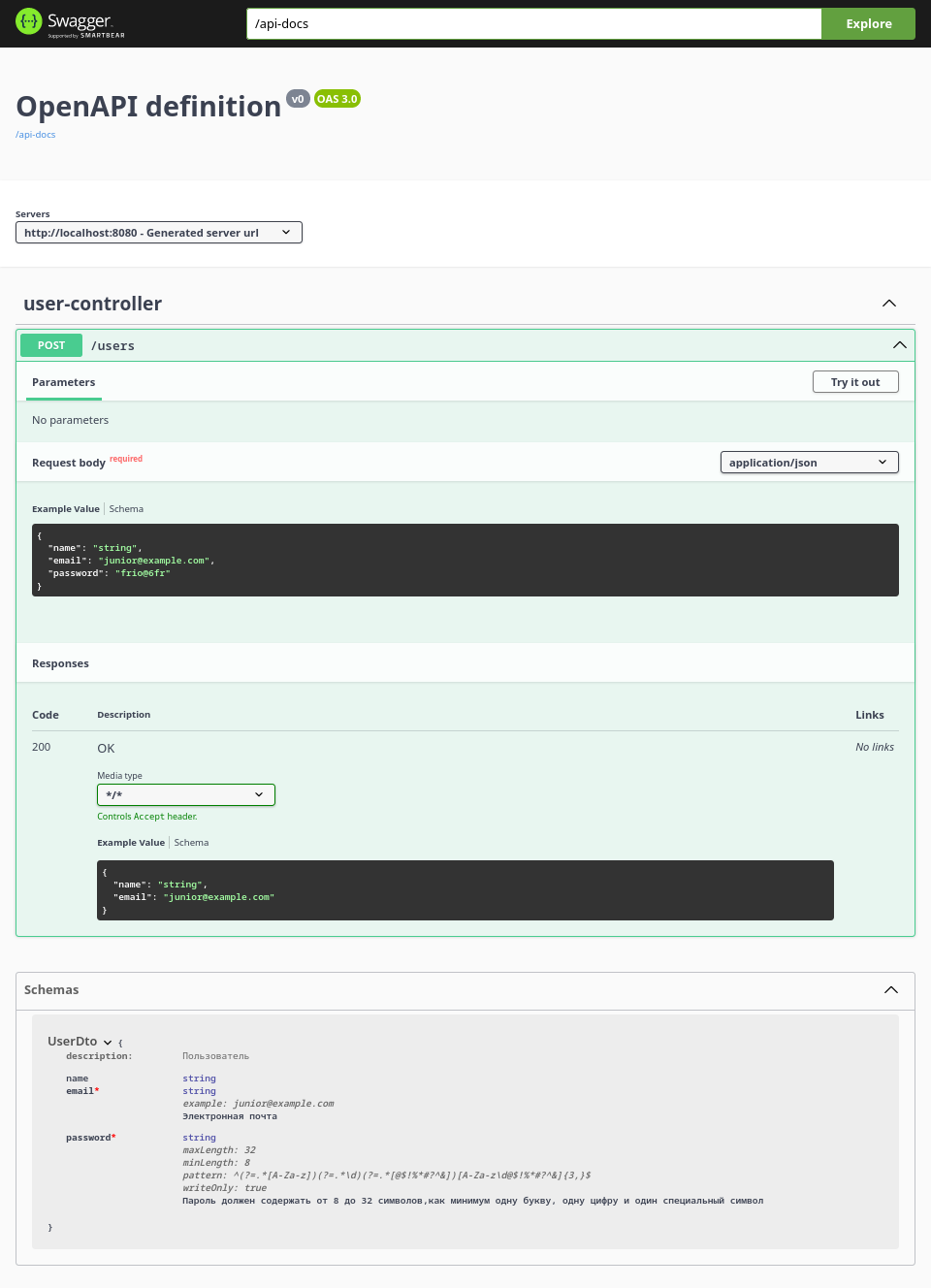
В этой статье посмотрим, насколько хороша генерация в OpenAPI из Spring MVC (спойлер — довольно хороша), какие есть подводные камни и костыли, чтобы с ними справится.
Наше API будет включать:
— валидацию тела и параметров с помощью JSR-303
— различные коды ответа с помощью ControllerAdvice и без него
— работа с Page и Pageable
— авторизация запросов
Погружение в мир контейнеризации с докером — это путь к оптимизации развёртыванию приложений, а также ключ к упрощению жизни разработчиков и системных администраторов. Меня зовут Андрей Аверков, в IT c 2008 начинал пусть с аналитика-проектировщика IT систем, 11 лет в роли разработчика и последние годы на руководящих должностях. Сейчас я тимлид команды разработки из 9 человек в группе компании Кокос. Мы занимаемся созданием и поддержкой CPA платформ (gdeslon.ru, fxpartners.ru, ads.mobisharks.com), а также проектом по генерации лендингов — lpgenerator.ru. У нас большой опыт в разделении продуктов на части, поэтому, сегодня мы собрали самое основное и необходимое для работы с Docker. В нашей шпаргалке вы найдете все необходимое для успешного старта с докером: от базовых концепций и установки до продвинутых техник работы с контейнерами.

Spring Framework позволяет сфокусироваться на бизнес-логике, а вся настройка инфраструктуры выполняется автоматически благодаря постобработке бинов. Зачастую для реализации дополнительной функциональности применяется Spring AOP - аспектно-ориентированное программирование.
Spring AOP бин, который накручивает дополнительную функциональность другим Spring бинам, помечается аннотацией @Aspect, но как потом этот бин используется для добавления дополнительной функциональности в поток исполнения?
В статье будет рассмотрен механизм проксирования объектов и его применение в Spring Framework.
Так ли на самом деле работает процесс загрузки классов, как его описывает Wikipedia и Baeldung? ClassNotFoundException — это откуда и чье? Какие виды загрузчиков классов актуальны в Java 20?
Объясняем подпроцесс загрузки, из системы Java ClassLoader, на приятных Excalidraw диаграммах, со ссылками на оригинальные источники.

Привет, Хабр! Меня зовут Гриша Скобелев, я бэкенд-разработчик, у меня есть гитара, кошка и скейтборд. Я так сильно люблю Spring Framework, что назвал кошку в честь него — Веснуша. Возглавляю программный комитет Podlodka Java Crew, где мы делаем классные конференции. Еще я организовал книжный клуб для бэкенд-разработчиков { между скобок }. Хочу поделиться своим опытом развития бэкендера — от собеседования до наработки разных навыков для роста. Тут будет много ссылок, практических советов и инструкций, которые я наработал за время своей карьеры, общения с другими бэкендерами и проведения конференций и консультаций.
Все здесь правы, каждый по-своему, и, следовательно, все здесь не правы.
"Сказка о Тройке" (А. и Б. Стругацкие)
Если вы используете Spring Data JPA, то после обновления на Spring Boot 2 при старте приложения можете заметить в логе новое предупреждение:
spring.jpa.open-in-view is enabled by default. Therefore, database queries may be performed during view rendering. Explicitly configure spring.jpa.open-in-view to disable this warning.
В этой статье попытаюсь объяснить, что это значит, кто виноват и что делать.
Для поднятия полноценного приложения на Spring Boot требуется всего лишь одна аннотация @SpringBootApplication. Для того, чтобы это было возможным, фреймворк использует большое количество автоконфигураций и настроек по умолчанию. Более того, для работы "из коробки" разработчикам Spring Boot пришлось выбрать некие концепции разработки приложений из нескольких альтернативных вариантов для каждой, чтобы пользователю не нужно было выбирать их явно. С одной стороны это хорошо для быстрого старта и легкой разработки, но с другой – через некоторое время может оказаться, что некая используемая по умолчанию концепция/парадигма/настройка не подходит для проекта, а для отказа от нее придется многое переделать. Одной из таких концепций является режим Open Session In View (OSIV), включенный в Spring Boot по умолчанию.
Привет! В этой статье я бы хотел рассказать, как Spring'овая аннотация @Transactional ведет себя при возникновении исключений. Про это немало написано, в том числе на Хабре. Например, тут или тут. Поэтому, чтобы не повторяться, я не буду подробно расписывать как и почему исключения влияют на откат транзакций, а вместо этого просто покажу несколько примеров.

Ни для кого не секрет, что Spring Framework один из самых популярных фреймворков для приложений на языке Java. Он интегрировал в себя самые полезные и актуальные технологии, такие как i18n, JPA, MVC, JMS, Cloud и т.п.
Но насколько хорошо вы знакомы с жизненным циклом фреймворка? Наверняка вы сталкивались с проблемами поднятия контекста и освобождением ресурсов при его остановке, когда проект разрастается. Сегодня я попытаюсь наглядно показать вам это.


Привет! Если ты так же как и я решил использовать keycloak для аутентификации и авторизации в своей микро‑сервисной архитектуре, то я расскажу вам как правильно настроить сам keycloak, его рабочую среду а в конце мы подключим Active Directory к нашему приложению.
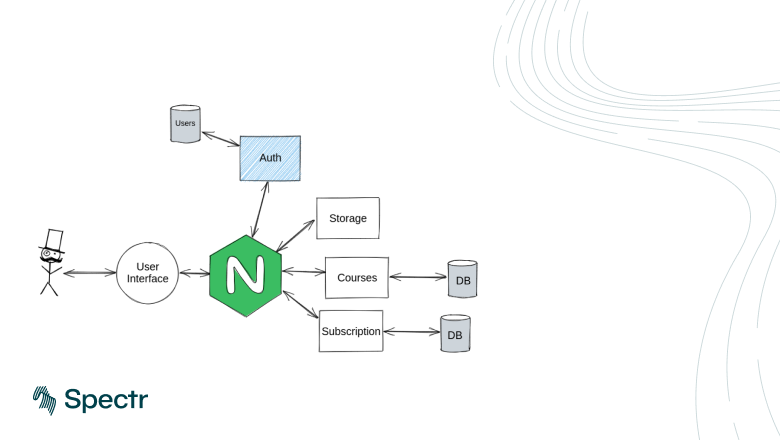
Привет! На связи Олег Казаков из Spectr. Мы занимаемся разработкой цифровых сервисов, в том числе высоконагруженных систем с микросервисной архитектурой и большим количеством различных интеграций.
В статье расскажу об одном из кейсов при работе над проектом с микросервисной архитектурой — реализации единой системы авторизации и аутентификации. Поговорим про теорию, рассмотрим различные стратегии реализации и особое внимание уделим паттерну API Gateway.
В процессе работы над одной из задач возникла необходимость промониторить время исполнения отдельных участков кода одного из микросервисов для того, чтобы отловить узкие места и попытаться эту ситуацию исправить.
Т.к. речь шла о сервисе, который был написан довольно давно, и в него многие месяцы не вносились изменения, повинуясь принципу “работает - не трогай”, я решил постараться сделать это, не прикасаясь к самому коду сервиса.