Здравствуйте, уважаемые хабражители. Сегодня я хотел бы поделиться с вами своими впечатлениями от использования NAS Synology DS214.


User

Обзор использования Synology DS220+ в качестве системы резервного копирования для дома, домашнего медиасервера и как элемент умного дома. В статье описанны особенности DS220+ и опыт его использования на протяжении 4 месяцев. Для сравнения кратко представлены альтернативные варианты способные заменить подобное устройство.Описание функционала и сценариев использования в статье довольно подробно и, как я надеюсь, поможет выбрать подходящий вариант резервного копирования.
Представленный ниже шаблон сервера на Golang был подготовлен для передачи знаний внутри нашей команды. Основная цель шаблона, кроме обучения — это снизить время на прототипирование небольших серверных задач на Go.
Первая часть шаблона посвящена HTTP серверу:
Вторая часть шаблона посвящена прототипированию REST API.
Ссылка на репозиторий проекта осталась прежней.
Третья часть посвящена развертыванию шаблона в Docker, Docker Compose, Kubernetes (kustomize).
Пятая часть посвящена оптимизации Worker pool и особенностям его работы в составе микросервиса, развернутого в Kubernetes.
В ходе тестирования шаблона на стенде были получены следующие результаты.
Перевод познавательной статьи "Golang: channels implementation" о том, как устроены каналы в Go.
Go становится всё популярнее и популярнее, и одна из причин этого — великолепная поддержка конкурентного программирования. Каналы и горутины сильно упрощают разработку конкурентных программ. Есть несколько хороших статей о том, как реализованы различные структуры данных в Go — к примеру, слайсы, карты, интерфейсы — но про внутреннюю реализацию каналов написано довольно мало. В этой статье мы изучим, как работают каналы и как они реализованы изнутри. (Если вы никогда не использовали каналы в Go, рекомендую сначала прочитать эту статью.)
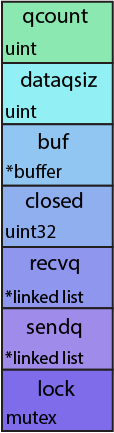
Давайте начнём с разбора структуры канала:
go normalFunc(args...)normalFunc(args...) начнет выполняться асинхронно с вызвавшим ее кодом.Перевод одной из статей Бена Джонсона из серии "Go Walkthrough" по более углублённому изучению стандартной библиотеки в контексте реальных задач.
Go является языком программирования, хорошо приспособленным для работы с байтами. Будь у вас списки байт, потоки байт или просто отдельные байты, в Go легко с ними работать. Это примитивы, на которых мы строим наши абстракции и сервисы.
Пакет io является одним из самых фундаментальных во всей стандартной библиотеке. Он предоставляет набор интерфейсов и вспомогательных функций для работы с потоками байтов.
Этот пост является одним из серии статей по более углублённому разбору стандартной библиотеки. Несмотря на то, что стандартная документация предоставляет массу полезной информации, в контексте реальных задач может быть непросто разобраться, что и когда использовать. Эта серия статей направлена на то, чтобы показать использование пакетов стандартной библиотеки в контексте реальных приложений.


The goal of this quick reference is to collect in one place and organize information about value categories in C++, assignment, parameter passing and returning from functions. I tried to make this quick reference convenient to quickly compare and select one of solutions possible, this is why I made several tables here.
For introduction to the topic, please use the following links:
C++ rvalue references and move semantics for beginners
Rvalues redefined
C++ moves for people who don’t know or care what rvalues are
Scott Meyers. Effective Modern C++. 2015
Understanding Move Semantics and Perfect Forwarding: Part 1
Understanding Move Semantics and Perfect Forwarding: Part 2
Understanding Move Semantics and Perfect Forwarding: Part 3
Do we need move and copy assignment


 Технология Windows Installer (MSI) является стандартом де-факто в мире системных администраторов, занимающихся распространением и поддержкой программного обеспечения для десктопных и серверных версий Windows. Формат MSI поддерживается всеми крупнейшими системами управления конфигурациями (Microsoft SCCM, CA Unicenter и многими другими), а для некоторых систем распространения ПО — является единственным поддерживаемым форматом.
Технология Windows Installer (MSI) является стандартом де-факто в мире системных администраторов, занимающихся распространением и поддержкой программного обеспечения для десктопных и серверных версий Windows. Формат MSI поддерживается всеми крупнейшими системами управления конфигурациями (Microsoft SCCM, CA Unicenter и многими другими), а для некоторых систем распространения ПО — является единственным поддерживаемым форматом. Глава из книги "Современное программирование на C++" называется "В сто первый раз об интеллектуальных указателях". Все бы ничего, но книга была издана в 2001 году, так стоит ли в очередной раз возвращаться к этой теме? Мне кажется что как раз сейчас и стоит. За эти пятнадцать лет поменялась сама точка зрения, тот угол под которым мы смотрим на проблему. В те далекие времена только-только вышла первая де-факто стандартная реализация — boost::shared_ptr<>, до этого каждый писал себе реализацию по потребности и как минимум представлял себе детали, сильные и слабые стороны своего кода. Все книги по C++ в то время обязательно описывали одну из вариаций умных указателей в мельчайших деталях.
Глава из книги "Современное программирование на C++" называется "В сто первый раз об интеллектуальных указателях". Все бы ничего, но книга была издана в 2001 году, так стоит ли в очередной раз возвращаться к этой теме? Мне кажется что как раз сейчас и стоит. За эти пятнадцать лет поменялась сама точка зрения, тот угол под которым мы смотрим на проблему. В те далекие времена только-только вышла первая де-факто стандартная реализация — boost::shared_ptr<>, до этого каждый писал себе реализацию по потребности и как минимум представлял себе детали, сильные и слабые стороны своего кода. Все книги по C++ в то время обязательно описывали одну из вариаций умных указателей в мельчайших деталях.
Сейчас нам дан стандарт, и это хорошо. Но с другой стороны, уже не требуется понимать что там внутри, вместо этого достаточно три раза повторить мантру "используйте умные указатели везде где вы бы использовали обычные указатели", и это уже не так хорошо. Я подозреваю что далеко не все отдают себе отчет что данный стандарт — лишь один из возможных вариантов интерфейса, не говоря уже о разнице между реализациями различных вендоров. При выборе стандарта был сделан выбор между различными возможностями учитывающий разные факторы, но, оптимальный или нет, этот выбор очевидно не единственен.
А еще на stackoverflow например снова и снова задается вопрос — "потокобезопасны ли умные указатели из стандартной библиотеки?". Ответы даются обычно категоричные, но какие-то мало информативные. Если бы я например не знал о чем идет речь, то наверное бы не понял. И кстати, все сравнительно новые книги описывающие новый стандарт C++ этому вопросу тоже уделяют мало внимания.
Так давайте же попробуем сорвать покровы и разберемся с деталями.

В статье я хотел бы поделиться своим опытом написания инсталлятора для Windows с использованием инструмента Windows Installer XML Toolset (далее - Wix). К сожалению, несмотря на всю мощь данного инструмента, его использование сильно осложняется куцей документацией, старенькими кукбуками, вялыми ветками форумов и вытеснением .msi и .exe пакетов контейнеризацией. Однако, сегодня продолжают активно развиваться и создаваться программные продукты требующие развертывания на виндовой машине с использованием традиционных установочных пакетов.


{kind=link}
{kind=link}