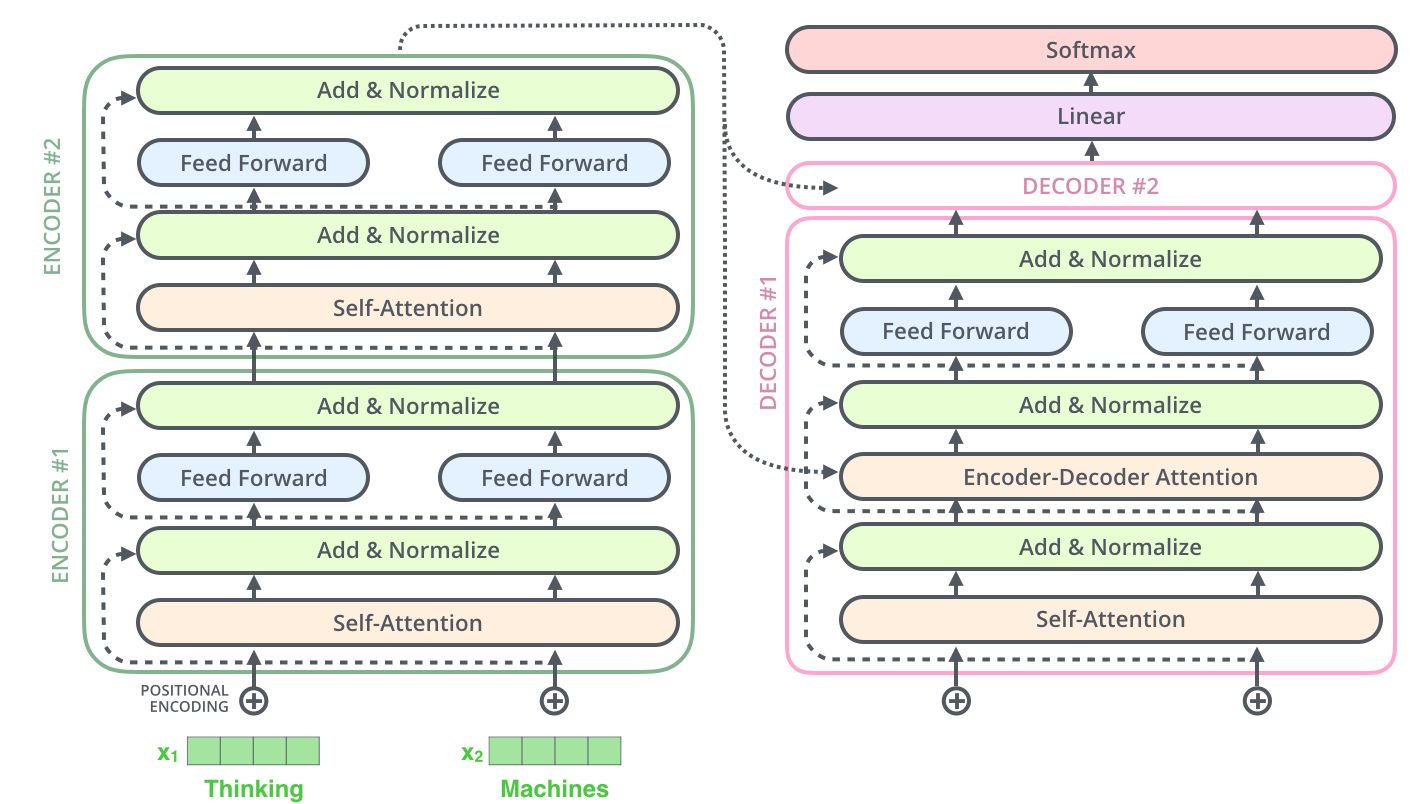
Привет, меня зовут Андрей Казначеев, я NLP engineer в компании MTS AI. В этой статье я расскажу, как создал лонгформер для русского языка. Все началось с того, что мне подкинули задачу по классификации длинных диалогов. Тексты длинные, а большинство популярных моделей имеют строгое ограничение по длине входной последовательности. Хотелось сделать решение умнее, чем просто побить текст на куски, однако ничего готового для русского языка не нашел. Тогда я задумался, а так ли сложно сделать свою собственную версию лонгформера под русский язык? Оказалось, совсем не сложно.