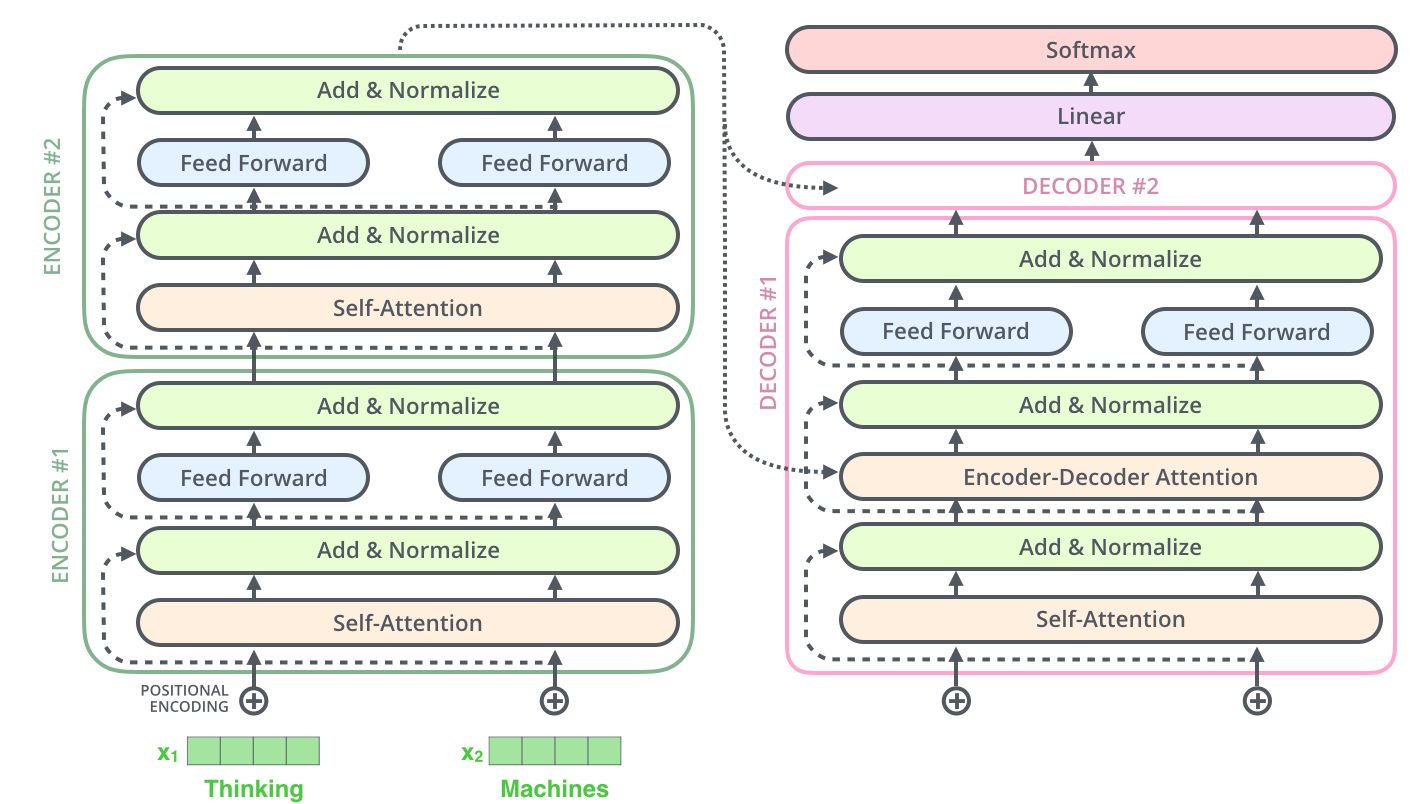
В первой части статьи я рассказал про понятие градиентного бустинга, библиотеки, с помощью которых можно реализовать данный алгоритм и углубились в одну из этих библиотек. Сегодня продолжим разговор о CatBoost и рассмотрим Cross Validation, Overfitting Detector, ROC-AUC, SnapShot и Predict. Поехали!
До этого момента мы мерили качество на каком-то конкретном fold’e (конкретной выборке), то есть взяли разделили нашу выборку на обучающую и тестовую, это не совсем корректно, вдруг мы взяли какой-то непрезентативный кусок нашего датасета, на этом самом куске мы получим хорошее качество, а когда модель будет работать с реальными данными, то с качеством все будет крайне грустно. Дабы избежать этого, необходимо использовать Cross Validation.
Разобьём наш датасет на кусочки и дальше будем обучать модель столько раз, сколько у нас будет кусочков. Сначала обучаем модель на все кусках кроме первого, нам нем будет происходить валидация, потом на втором будет происходить такая же ситуация и все это дело будет повторяться до последнего кусочка нашей выборки: