
Глубокое погружение в возможности gRPC на Python: перехватчики, трассировка, рефлексия и потоки данных.

User
Глубокое погружение в возможности gRPC на Python: перехватчики, трассировка, рефлексия и потоки данных.

Изучив основы gRPC в первой части нашей серии, мы теперь погрузимся в практическую реализацию gRPC сервиса на Python с использованием FastAPI и Piccolo ORM, чтобы показать, как это работает на примере тестового приложения.

Эта статья содержит краткую теорию о gRPC, обсудит преимущества и особенности использования данной технологии для создания высокопроизводительных и масштабируемых микросервисов.

Привет, Хабр!
Сегодня мы поговорим о том, какие LLM лучше всего работают на бизнес-задачах. AI-хайп находится на локальном пике, похоже, что весь мир только и делает, что внедряет AI-фичи в свои продукты, собирает миллионы на разработку еще одной оболочки для ChatGPT, заполняет свои ряды AI-тулами и, кажется, предоставляет работу роботам, пока сами попивают кофе в старбаксе.


Век живи - век учись, а презентации составлять так и не научишься. Сколько времени и сил тратится на подготовку этих стандартных презентаций, особенно во время сессии. Но что если значительную часть этой рутинной работы можно было бы делегировать искусственному интеллекту? Именно такую возможность обещают многочисленные сервисы, использующие нейросети для генерации презентационного контента.
В этом обзоре мы попробуем разобраться, что из себя представляют новомодные ИИ-генераторы презентаций. Честно оценим их возможности и ограничения, пройдемся по функционалу, проверим на практических примерах.
Главный вопрос к этим сервисам - смогут ли они в текущей форме полностью заменить человека в создании качественного презентационного контента? Или они пока что больше напоминают ассистента, которому нужен присмотр и доработка результатов ручным трудом?
Исследуем, анализируем, делаем выводы! Ведь только опираясь на реальный опыт использования, можно понять, стоит ли овчинка выделки и имеет ли смысл переходить на ИИ-генерацию презентаций. Начнем!

Приветствую! Меня зовут Григорий, и я главный по спецпроектам в команде AllSee. В современном мире искусственный интеллект стал незаменимым помощником в различных сферах нашей жизни. Однако, я верю, что всегда нужно стремиться к большему, автоматизируя все процессы, которые возможно. В этой статье я поделюсь опытом использования Whisper и ChatGPT для создания ИИ‑секретаря, способного оптимизировать хранение и обработку корпоративных созвонов.

Используя технику Retrieval-Augmented Generation ("Поисковая расширенная генерация"), мы настроим русскоязычного бота, который будет отвечать на вопросы потенциальных работников для выдуманного свечного завода в городе Градск.

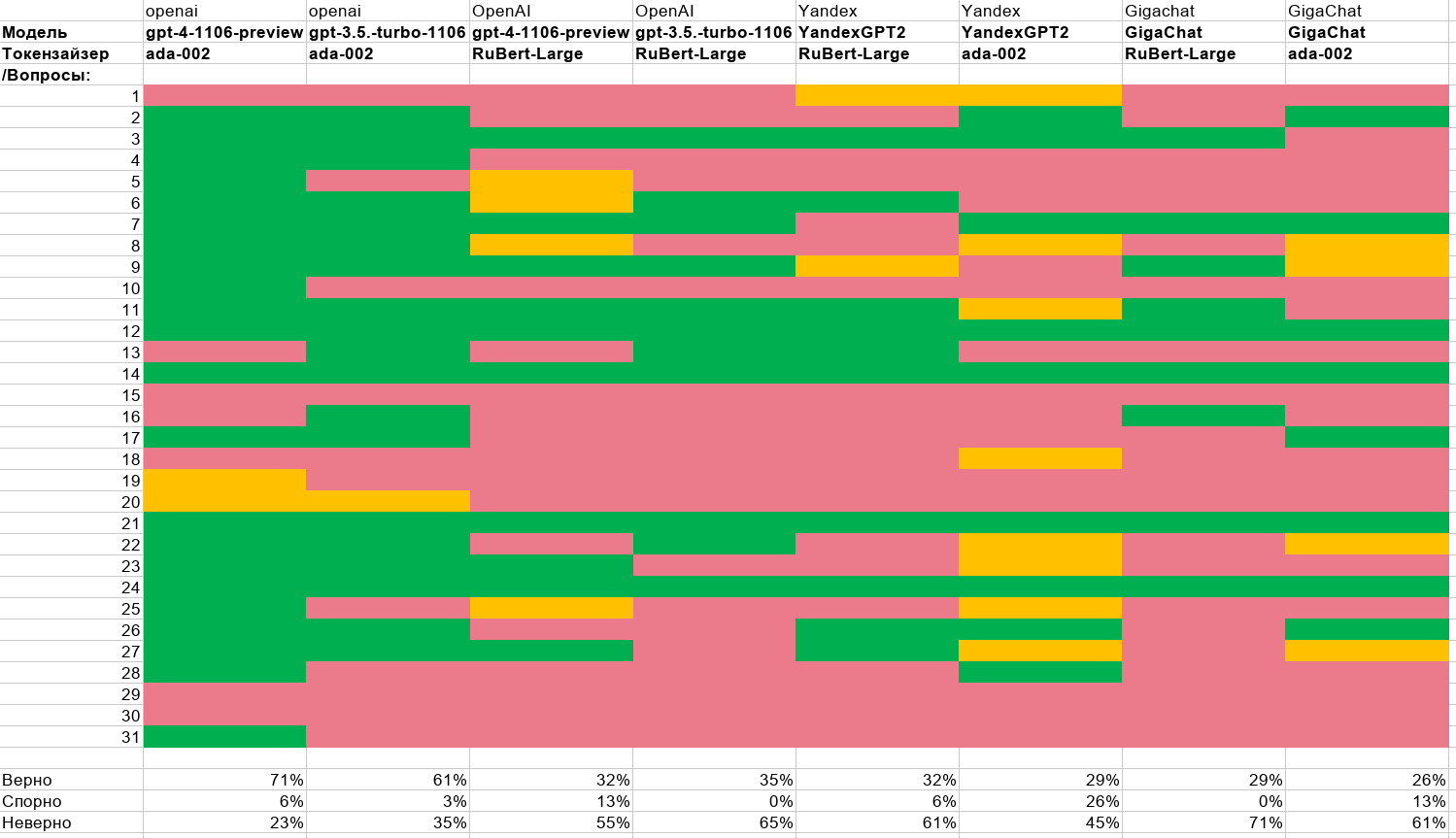
WaveSync — новый алгоритм для детального, нелинейного и быстрого анализа сходства эмбеддингов и векторов.
Алгоритм является в большинстве задач заменой линейному косиносному сходству. Он позволяет улучшить точность обработки языка и открывает новые перспективы для разработчиков и исследователей в области NLP.
Порой бывает сложно перематывать длинный ролик в надежде найти хоть что-то интересное или тот самый момент из Shorts. Или иногда хочется за ночь узнать, о чём шла речь на паре научных конференций. Для этого в Браузере есть волшебная кнопка — «Пересказать», которая экономит время и помогает лучше понять, стоит ли смотреть видео, есть ли в нём полезная информация, и сразу перейти к интересующей части.
Сегодня я расскажу про модель, которая быстро перескажет видео любой длины и покажет таймкоды для каждой части. Под катом — история о том, как мы смогли выйти за лимиты контекста модели и научить её пересказывать даже очень длинные видео.

Предлагается пошаговое руководство по дообучению Whisper для любого многоязычного набора данных ASR с использованием Hugging Face ? Transformers. Эта заметка содержит подробные объяснения модели Whisper, набора данных Common Voice и теории дообучения, а также код для выполнения шагов по подготовке данных и дообучению. Для более упрощенной версии с меньшим количеством объяснений, но со всем кодом, см. соответствующий Google Colab.
Меня зовут Дмитрий Гуреев. Я занимаю должность CDTO в одной из медицинских компаний и параллельно веду работу по популяризации ИИ в среднем бизнесе. Генеративные модели привлекли мое внимание ещё в феврале 2022 года. Тогда я внедрил цифрового ассистента для полевых продавцов.
Летом 2022 года хороший знакомый из крупной компании предложил совместный эксперимент. Создать цифрового юриста, способного отвечать на вопросы первой линии, используя в качестве базы знаний 200-страничный регламент из более чем 1200 пунктов. Все это должно было функционировать в закрытом контуре. Без интернета.
Задача представлялась крайне интересной...
Вторая часть здесь.

Применение искусственного интеллекта в окружающей нас действительности стремительно растет — международная консалтинговая компания McKinsey подсчитала, что среднее количество возможностей ИИ, используемых в организациях, удвоилась за последние четыре года. Занимаясь автоматизацией бизнес‑процессов, мы также начали исследования в этой области для упрощения и ускорения решения корпоративных задач. Мы уже писали ранее о первом опыте работы над автоматической генерацией протоколов совещаний. А в данной статье расскажем, как применили нейросетевые технологии для абстрактивной суммаризации, требующей минимальной доработки человеком.

Цель данной статьи — простым языком объяснить ключевые технологии, необходимые для начала разработки приложений на основе LLM. Oна подойдёт как и разработчикам, так и специалистам по машинному обучению, у которых есть базовое понимание концепций и желание заглянуть поглубже. Также я прикрепил множество полезных ссылок для дальнейшего изучения. Давайте начинать!

Сегодня мы затронем сторону, отличную от написания кода. Мы займемся оформлением и написанием документации, как правильно делать коммиты и как оформлять код.
Все, что вы увидите в данной статье, будет касаться прочитанных мною материалов и полученного опыта.
В мире разработки программного обеспечения правильное оформление документации играет ключевую роль в обеспечении ясности и понятности проекта. Особенно важным этапом в этом процессе является создание и поддержание README файлов в Git репозиториях. README файлы - это первое, что увидит разработчик, приступая к работе с проектом, и хорошо оформленная документация может значительно упростить процесс взаимодействия с кодом.
В данной статье мы рассмотрим ключевые аспекты оформления документации в Git репозитории, обсудим лучшие методики и практики для создания качественной документации. Независимо от того, являетесь ли вы опытным разработчиком или новичком в области Git, эта статья поможет вам создать четкую, структурированную и информативную документацию для вашего проекта. Погружайтесь в мир оформления документации, улучшайте ваши проекты и делитесь своими идеями с сообществом разработчиков Хабр!

Привет, Хабр!
С вами Вадим Дарморезов, участник профессионального сообщества NTA.
Сегодня рассмотрю кейс поиска изображений-«близнецов», которые были размещены в pdf-файлах, насчитывающих десятки, а порой и сотни страниц.
В проектах, связанных с распознаванием лиц своеобразными «флагманами» являются библиотеки dlib/face‑recognition и свёрточные нейронные сети. При этом на просторах русскоязычного интернета довольно мало статей о библиотеке insightface. Именно о ее использовании хотелось бы поговорить более подробно. Всем, кому это интересно, добро пожаловать по кат.

Делимся своими открытыми библиотеками для разработки рекомендательных систем. Что? Да! Рассказываем подробнее. Всем известно, что Сбер это уже не просто банк, а огромная технологическая компания, которая включает в себя и сервисы компаний-партнёров: электронную коммерцию, индустрию развлечений и даже медицину. Количество пользователей достигло 108 млн, и для каждого из них мы создаём персональные рекомендации, которые помогают не потеряться в разнообразии предложений и выбрать лучшее.

Привет Хабр! В этой статье мы рассмотрим некоторые полезные библиотеки Python для задач обработки данных, с которыми, возможно, вы еще не знакомы. Хотя для задач машинного обучения на ум приходят такие библиотеки, как pandas, numpy, scikit-learn, keras, tensorflow, matplotlib и т.д., но всегда полезно знать о других предложениях Python, особенно если это поможет улучшить ваши проекты.

За пределами всем известного GitHub Copilot лежит огромный мир полезных приложений для программистов, и каждую неделю в нем появляется что-нибудь новенькое. В этом посте мы расскажем об этих инструментах — как полноценных конкурентах продукта GitHub, так и более специфических плагинах, а также о нашей собственной разработке в этом направлении.
Я уже недавно писал на Хабре, что понемногу пилю свой сервис VseGPT с доступом по OpenAI API и чатом к различным нейросетям - ChatGPT, Claude, LLama и пр. (Коротко: потому что вендорлок - зло, разнообразие и опенсорс - добро)
Большая часть работы - это, конечно, роутинг запросов на разные сервера, которые осуществляют обработку нейросетевых моделей; свой у меня скорее общий универсальный интерфейс, который сглаживает разницу между моделями, ну и некоторые прикольные фишечки.
Но я давно задумывался развернуть что-то уникальное, собственное, чего нет у других - в особенности опенсорсную Сайгу.
TLDR: Сайга-Мистраль 7B сравнима с 70B моделью. Доступна на сайте, её можно использовать по API или через интерфейс чата.