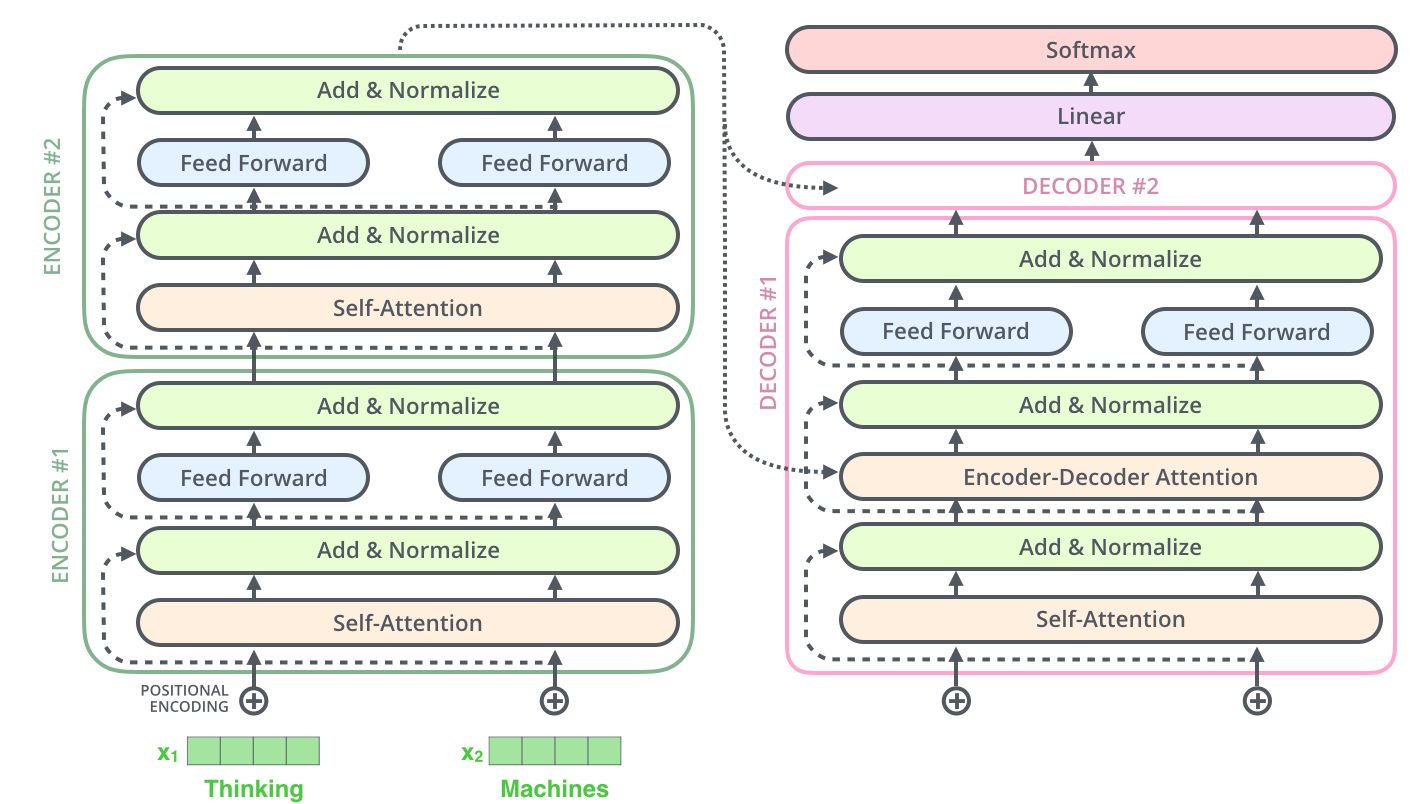
Несколько лет спустя, после описанных в предыдущей части событий, в один прекрасный день, мне вспомнились собственно описанные в предыдущей части события, а после этого в мою голову пришел неожиданный (для меня) и довольно очевидный (для остальных) вопрос — а что именно я хотел извлечь из LHX? На что я логично ответил сам себе — а что вообще там есть? Опуская нюансы типа специфических кишок (как вычисляется попадание в противника, код отслеживания карьеры пилота и т.п), как и в любой игре, остаются, по большому счету, графика (движок + модельки/текстуры) и звук (движок + файлы звуков). Звук меня мало интересовал (в те годы у меня даже ковокса не было — я просто не знал о таком) — писк из спикера это всего лишь писк из спикера. А вот графика — да. И я наконец(!) понял, что хочу вытащить из игры именно модельки.