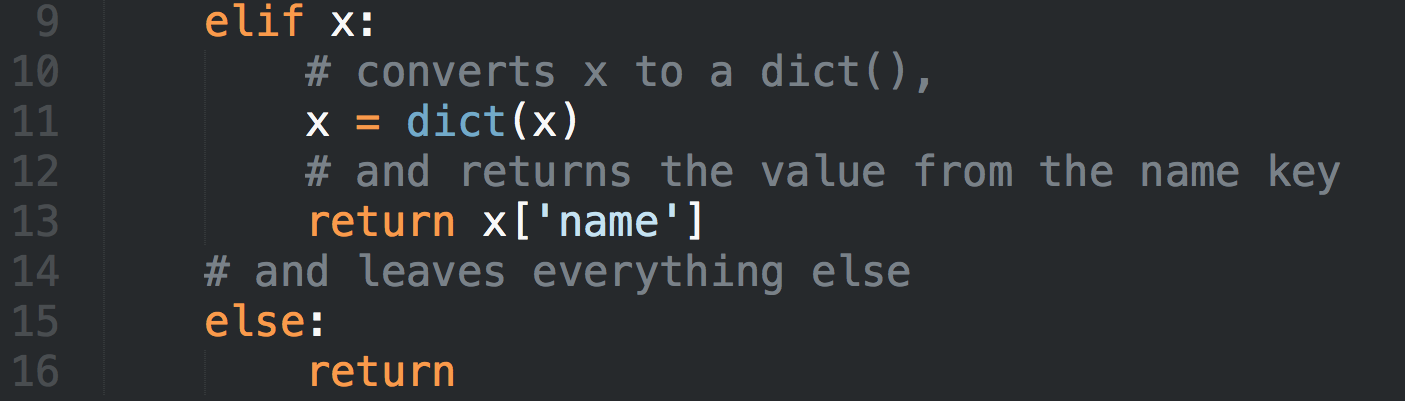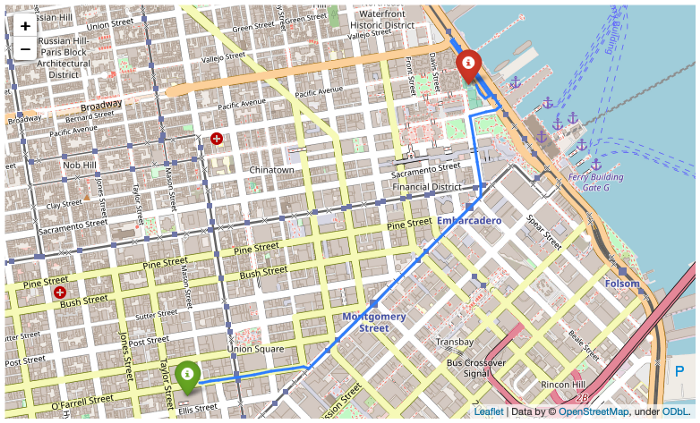
Распространённая задача программистов в работе с геопространственными данными — отобразить маршруты между различными точками. Решением, которое может понадобиться в разработке веб-сайта, делимся к старту курса по Fullstack-разработке на Python.

Пользователь
Распространённая задача программистов в работе с геопространственными данными — отобразить маршруты между различными точками. Решением, которое может понадобиться в разработке веб-сайта, делимся к старту курса по Fullstack-разработке на Python.

Представьте, что вы вместе со своим коллегой, ведущим программистом, с которым работали последние 4 года в банке, придумали нечто невообразимое, так нужное рынку. Вы выбрали хорошую бизнес-модель и к вам присоединились сильные ребята в команду. Ваша идея приобрела вполне осязаемые черты и бизнес практически начал приносить деньги.
Если вообще не соблюдать правила гигиены, быть токсичным, не последовательным, корыстным, обманывать других, то до первых денег вообще не добраться. Представим, что все хорошо, вы все молодцы и не за горами время, когда пойдет первая серьезная прибыль. Тут рушатся воздушные замки, которые были так скрупулезно выстроены каждым членом команды. Первый думал, что он главный и он заберет 80% прибыли, так как именно он продал машину и на его деньги жила первое время вся команда. Второй думал, что два основателя получат по 50%, так как он программист и создал то самое приложение, на котором все сейчас зарабатывают. Третий и четвертый думали, что они получат долю в бизнесе, как только пойдут деньги, ведь они работали почти круглосуточно и получали значительно меньше, чем могли бы в том же банке.
В итоге бизнес под угрозой развала. А ведь всего бы этого можно было бы избежать, правильно договорившись на берегу. Как?

Rcpp, увеличивая скорость на несколько порядков, так что можно будет нормально обрабатывать 100 миллионов строк данных или даже больше. # Создание набора данных
col1 <- runif (12^5, 0, 2)
col2 <- rnorm (12^5, 0, 2)
col3 <- rpois (12^5, 3)
col4 <- rchisq (12^5, 2)
df <- data.frame (col1, col2, col3, col4)
def log_progress(sequence, every=10):
for index, item in enumerate(sequence):
if index % every == 0:
print >>sys.stderr, index,
yield item