
Julie Zhuo, директор по продуктовому дизайну в Facebook, однажды выступала на «TNW Europe», и рассказывала о фрэймворке, который используется в Facebook, чтобы сфокусироваться на разработке продукта.
Работа над этой речью заставила меня подумать о других уроках, которые я усвоила с годами о том, как сделать великие вещи.
Этот список не идеальный и не полный. Если бы была какая-то пошаговая инструкция (Шаг 1: Идея. Шаг 2: ??? Шаг 3: Профит!), тогда я бы потратила на неё хорошие деньги, а потом похлопала нас по спинам и смотрела бы, как новые потрясающие продукты цветут вокруг нас, словно цветочные поля в мае.
Путешествие завершено на 1%. Давайте продолжим идти дальше и обучаться.
Работа над этой речью заставила меня подумать о других уроках, которые я усвоила с годами о том, как сделать великие вещи.
Этот список не идеальный и не полный. Если бы была какая-то пошаговая инструкция (Шаг 1: Идея. Шаг 2: ??? Шаг 3: Профит!), тогда я бы потратила на неё хорошие деньги, а потом похлопала нас по спинам и смотрела бы, как новые потрясающие продукты цветут вокруг нас, словно цветочные поля в мае.
Путешествие завершено на 1%. Давайте продолжим идти дальше и обучаться.
Фрейминг
- Продукт успешен, потому что решает проблемы за людей. Это звучит очень просто, но это самая важная вещь, которую нужно понимать в создании хороших продуктов.
- Первым шагом в создании чего-то нового является понимание того, какую проблему ты хочешь решить и для кого. Это должно быть предельно ясно до того, как вы начнете думать над решением.
- Третий вопрос, который вы должны себе задать: «Почему именно эту проблему стоит решать?»
- Если аудитория, для которой вы создаете, узко определена (и вы её часть), то вы можете положиться на свою интуицию, чтобы принимать решения по продукту. Если же нет, то стоит полагаться на исследования и данные.
- Если вы — основатель стартапа, будет легче начать с решения проблем узкой аудитории, а затем расширяться к общей аудитории после того, как вы заручитесь изначальной поддержкой.
- Проблема, которую вы пытаетесь решить, должна быть поняла за пару предложений и резонировать с кем-либо из вашей целевой аудитории. Если этого не происходит, то считайте это тревожным признаком.







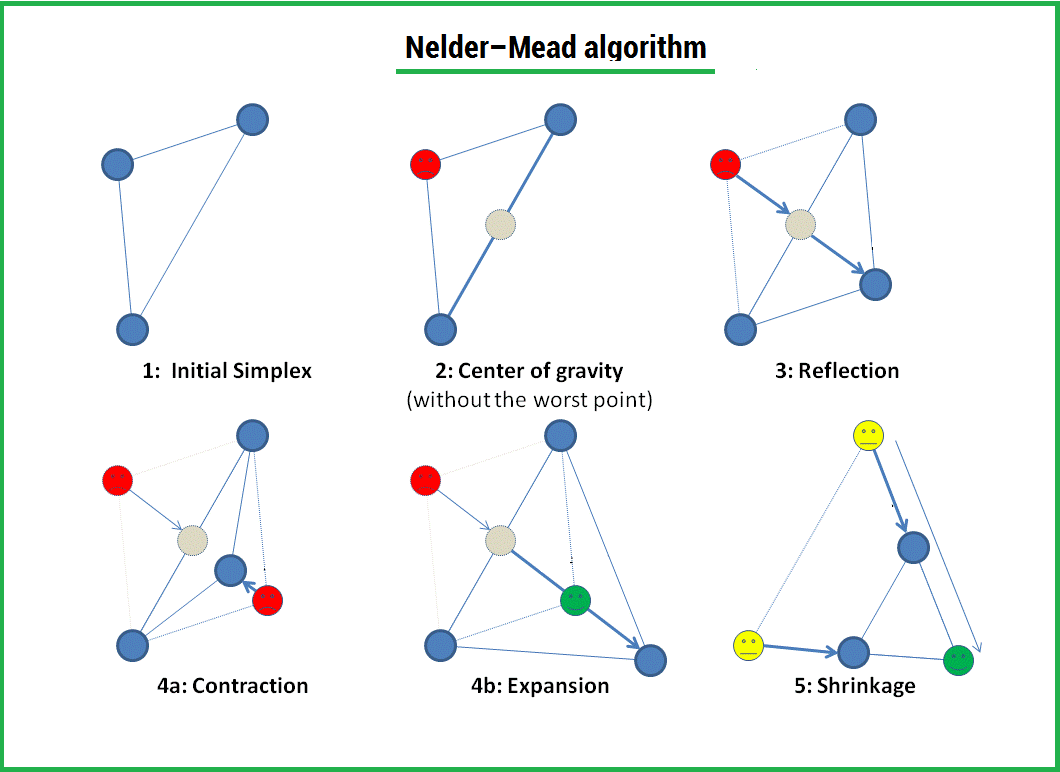


 Источник
Источник

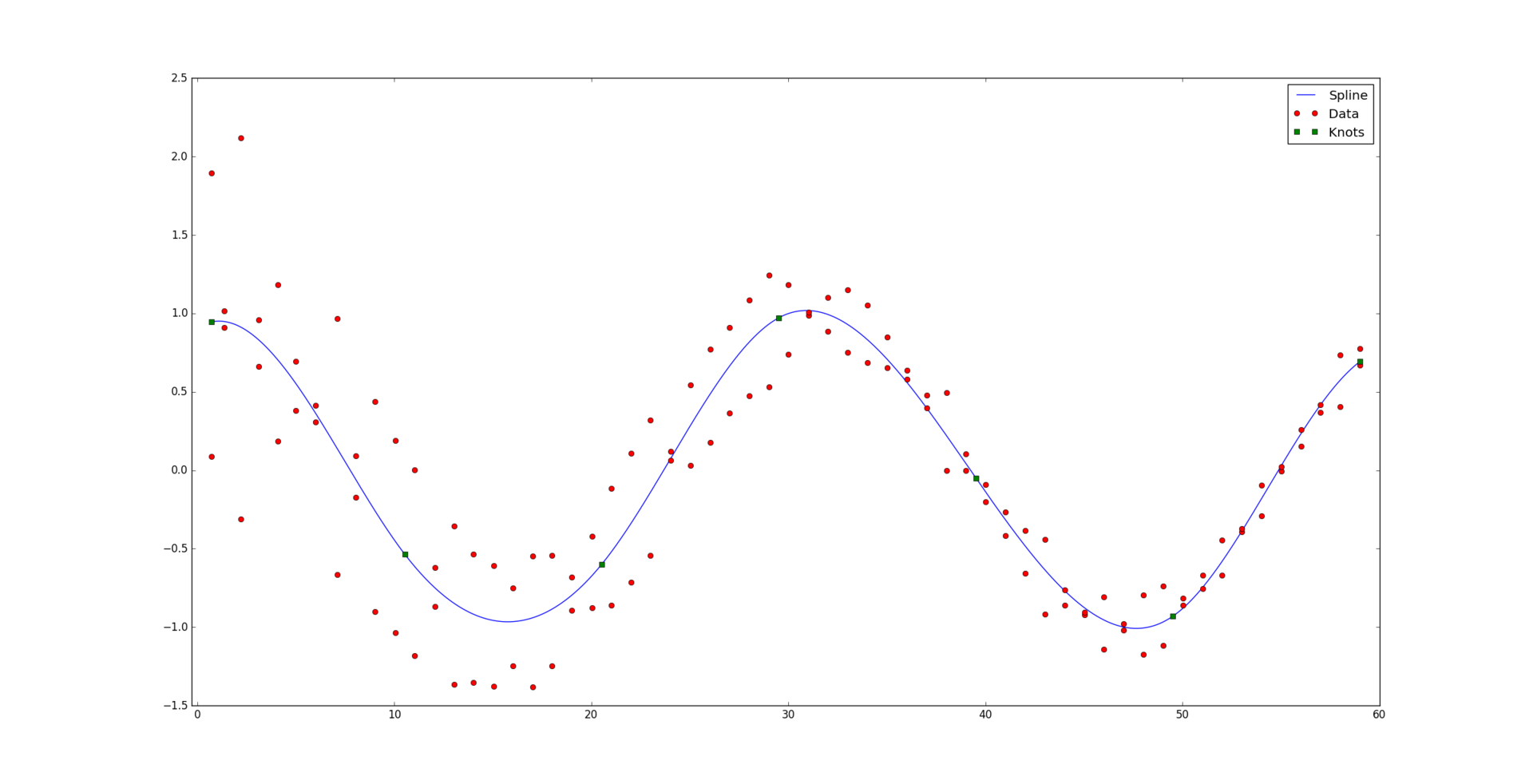
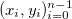 и соответствующий им набор положительных весов
и соответствующий им набор положительных весов 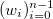 . Мы считаем, что некоторые точки могут быть важнее других (если нет, то все веса одинаковые). Неформально говоря, мы хотим, чтобы на соответствующем интервале была проведена красивая кривая таким образом, чтобы она «лучше всего» проходила через эти данные.
. Мы считаем, что некоторые точки могут быть важнее других (если нет, то все веса одинаковые). Неформально говоря, мы хотим, чтобы на соответствующем интервале была проведена красивая кривая таким образом, чтобы она «лучше всего» проходила через эти данные. 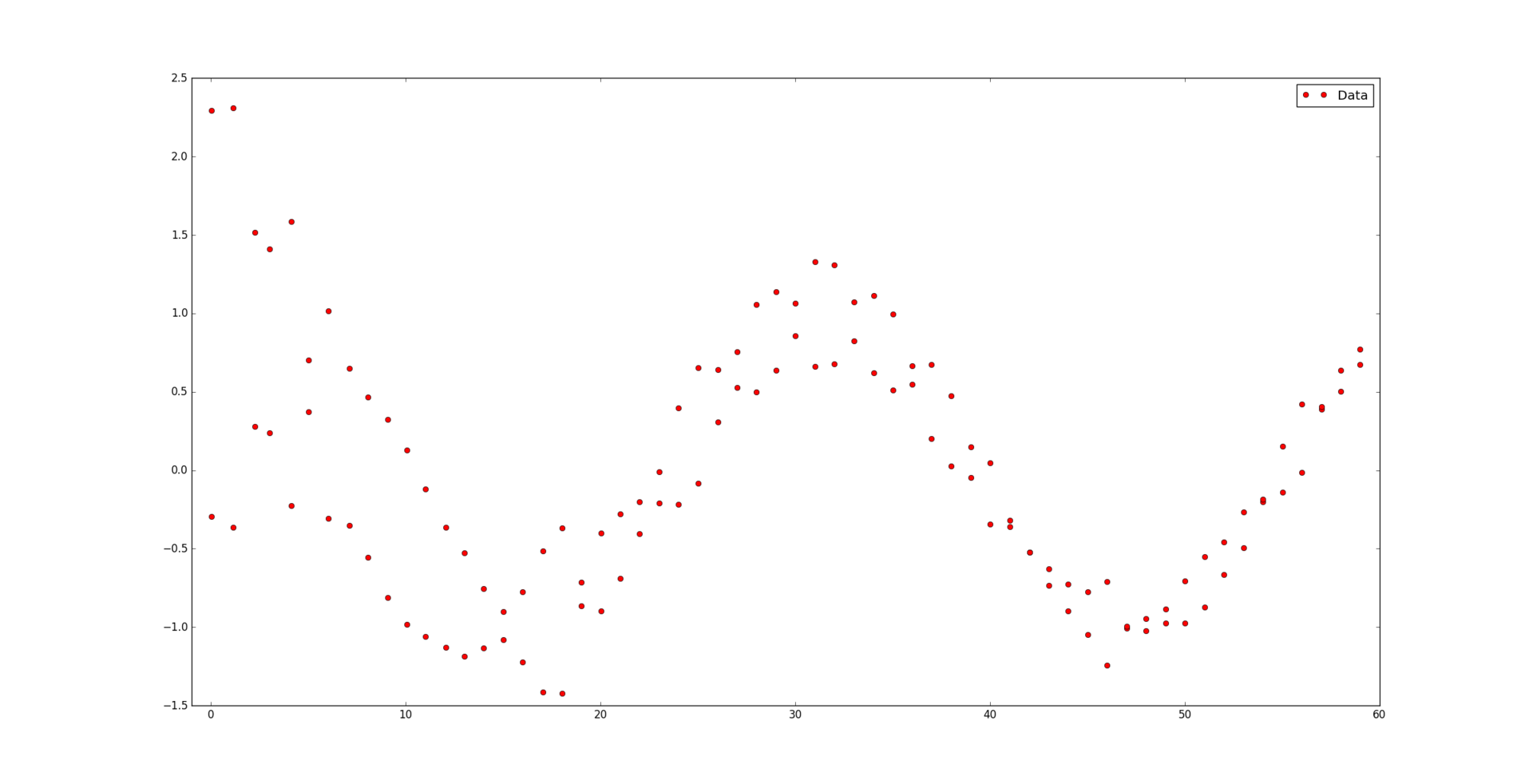
{kind=link}