Часто в проектах возникает необходимость выполнения отложенных задач, таких как отправка email, push и других специфических задач, свойственных доменной области вашего приложения. Сложности начинаются, когда обычного crontab уже не достаточно, когда пакетная обработка не подходит и когда у каждой единицы задачи свое время выполнения или оно назначается динамически.
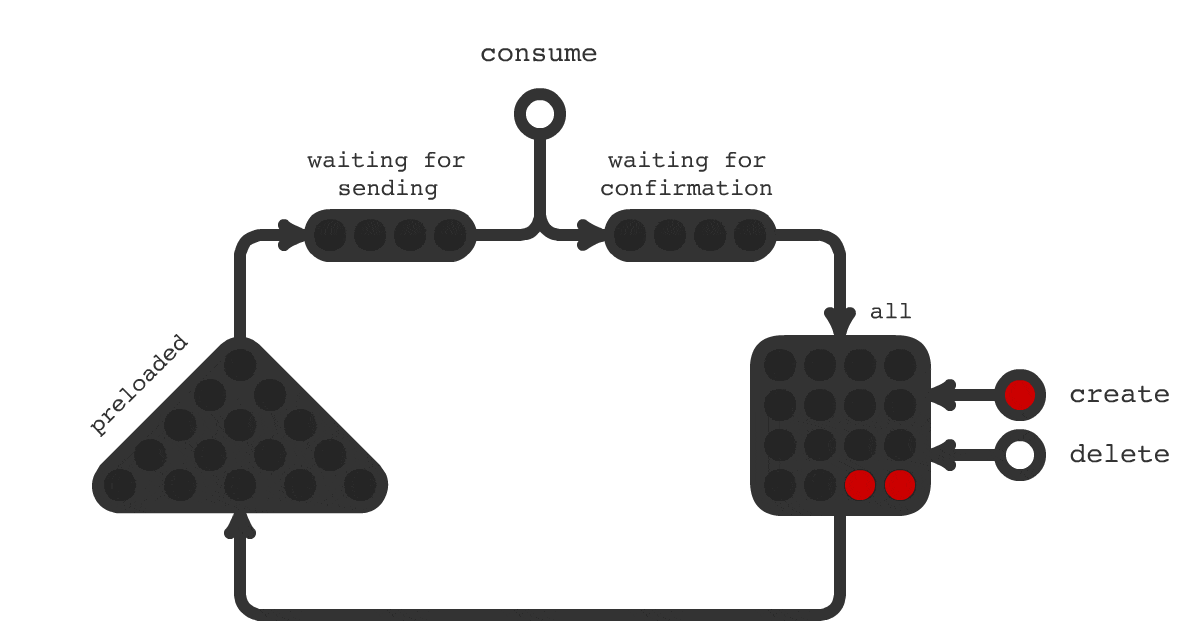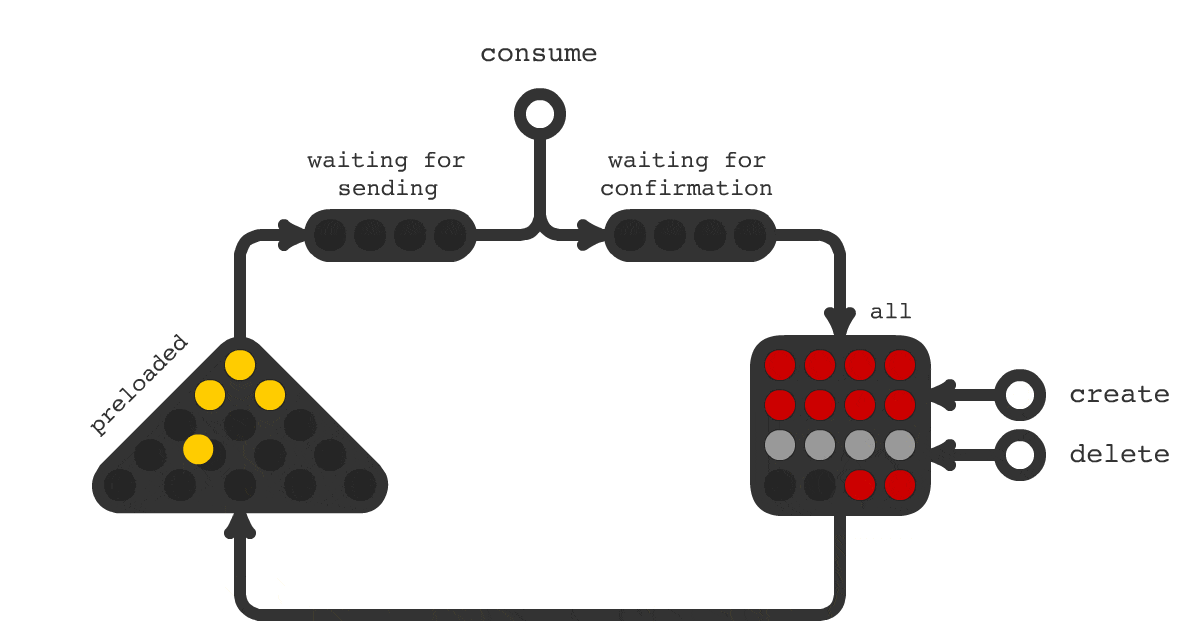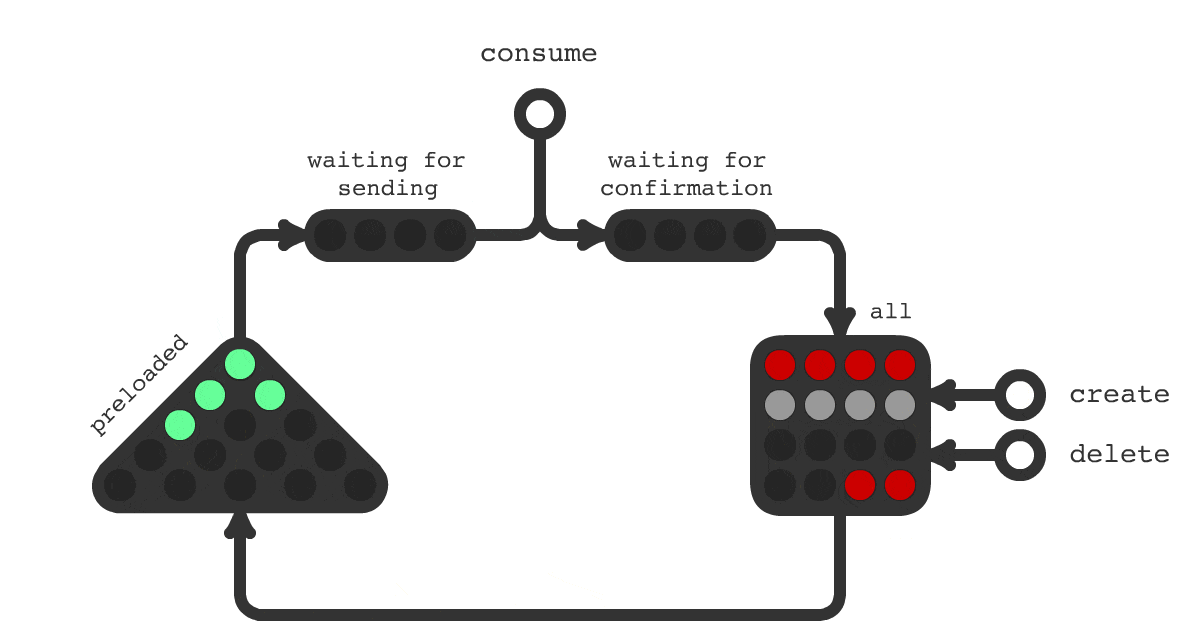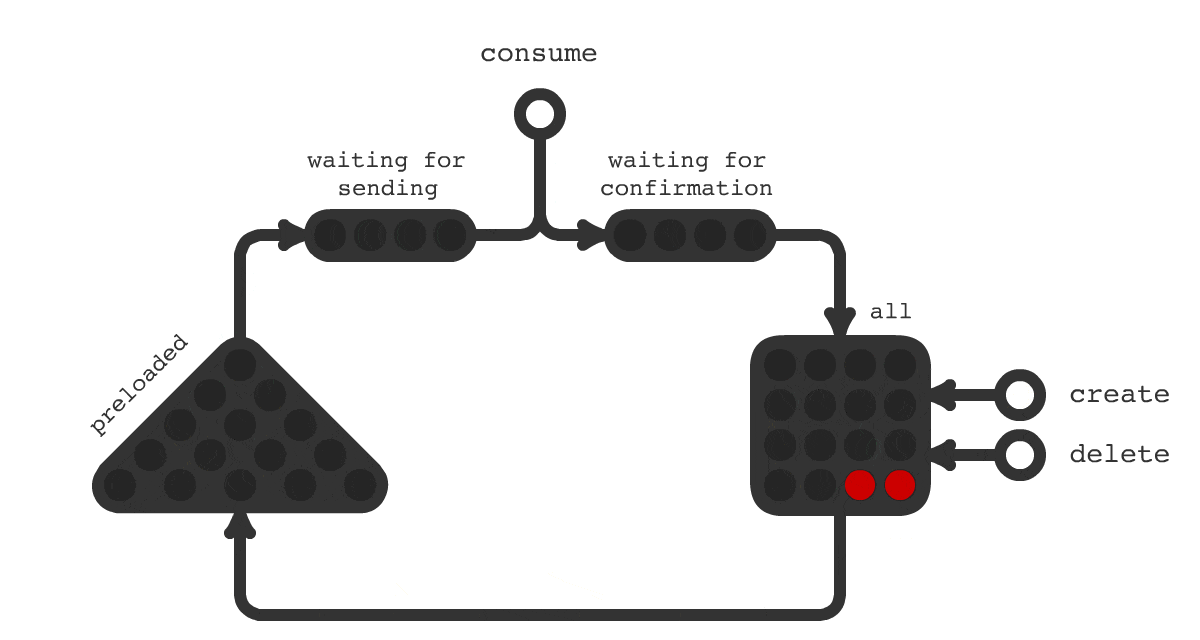
Для решения такой задачи было создано очередное решение под названием Trigger Hook. Принципиальная схема работы показана на рисунке 1. На схеме показано, что происходит с заданиями в течения всего их жизненного цикла. Смена цвета означает смену статуса задачи.









 Делиться с ближним своим для нас, божьих тварей, это очень характерно, считается добродетелью, и вообще, как утверждает
Делиться с ближним своим для нас, божьих тварей, это очень характерно, считается добродетелью, и вообще, как утверждает