Сегментация строки на символы является одним из важнейших этапов в процессе оптического распознавания символов (OCR), в частности, при оптическом распознавании изображений документов. Сегментацией строки называется декомпозиция изображения, содержащего последовательность символов, на фрагменты, содержащие отдельные символы.
Важность сегментации обусловлена тем обстоятельством, что в основе большинства современных систем оптического распознавания текста лежат классификаторы (в том числе — нейросетевые) отдельных символов, а не слов или фрагментов текста. В таких системах ошибки неправильного проставления разрезов между символами как правило являются причиной львиной доли ошибок конечного распознавания.
Поиск границ символов усложняется из-за артефактов печати и оцифровки (сканирования) документа, приводящим к “рассыпанию” и “склеиванию” символов. В случае использования стационарных или мобильных малоразмерных видеокамер спектр артефактов оцифровки существенно пополняется: возможны дефокусировка и смазывание, проективные искажения, деформирование и изгибы документа. При съемке камерой в естественных сценах на изображениях часто возникают паразитные перепады яркости (тени, отражения), а также цветовые искажения и цифровой шум в результате низкой освещенности. На рисунке ниже показаны примеры сложных случаев при сегментации полей паспорта РФ.





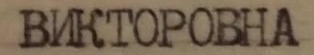
В этой статье мы расскажем о методе сегментации символов текстовых строк документов, разработанном нами в Smart Engines, основанный на обучении сверточных и рекуррентных нейронных сетей. Основным рассматриваемым в работе документом является паспорт РФ.
Важность сегментации обусловлена тем обстоятельством, что в основе большинства современных систем оптического распознавания текста лежат классификаторы (в том числе — нейросетевые) отдельных символов, а не слов или фрагментов текста. В таких системах ошибки неправильного проставления разрезов между символами как правило являются причиной львиной доли ошибок конечного распознавания.
Поиск границ символов усложняется из-за артефактов печати и оцифровки (сканирования) документа, приводящим к “рассыпанию” и “склеиванию” символов. В случае использования стационарных или мобильных малоразмерных видеокамер спектр артефактов оцифровки существенно пополняется: возможны дефокусировка и смазывание, проективные искажения, деформирование и изгибы документа. При съемке камерой в естественных сценах на изображениях часто возникают паразитные перепады яркости (тени, отражения), а также цветовые искажения и цифровой шум в результате низкой освещенности. На рисунке ниже показаны примеры сложных случаев при сегментации полей паспорта РФ.
В этой статье мы расскажем о методе сегментации символов текстовых строк документов, разработанном нами в Smart Engines, основанный на обучении сверточных и рекуррентных нейронных сетей. Основным рассматриваемым в работе документом является паспорт РФ.