Гибридное облако образуется в двух случаях: у кого-то остался парк железа, который ещё надо самортизировать, либо же стоят какие-то уникальные серверы, которые невозможно закупить у облачного провайдера.
Самая частая ситуация — слияние-поглощение, когда вы купили конкурента, а у него куча старого, но ещё хорошего железа. А у вас уже облачный подход. Или когда вы настолько круты, что у вас есть P-машины IBM либо какие-то особенные хранилища (бывают у телестудий и медицинских центров). В любом случае вы столкнетесь с ситуацией, когда есть безопасники в облаке, есть департамент ИБ на вашей стороне и куча костылей — посередине.
По данным Garnter, есть вероятность 90 %, что вопрос переезда в облако коснётся вас в этом или следующем году, поэтому стоит задуматься над кибербезопасностью уже сейчас.
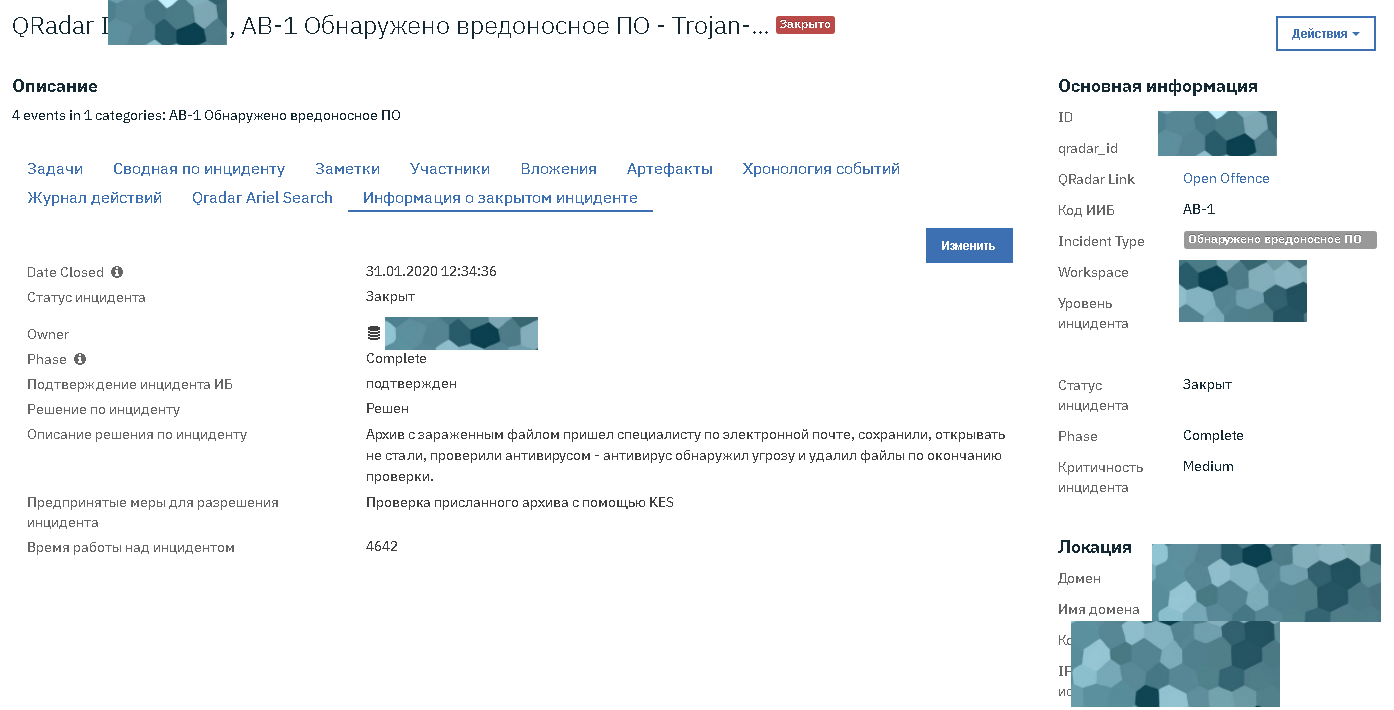
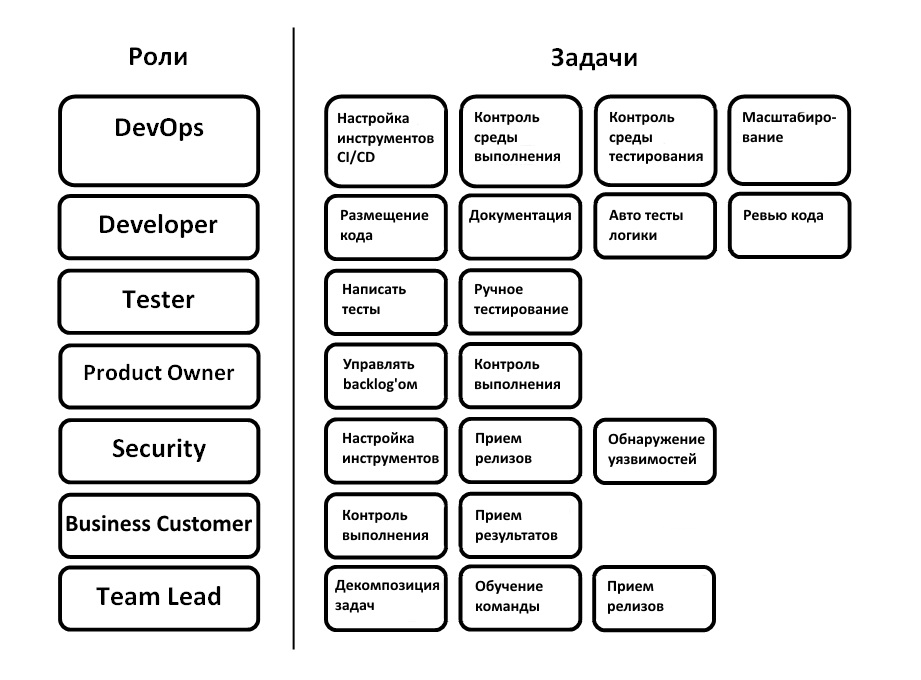
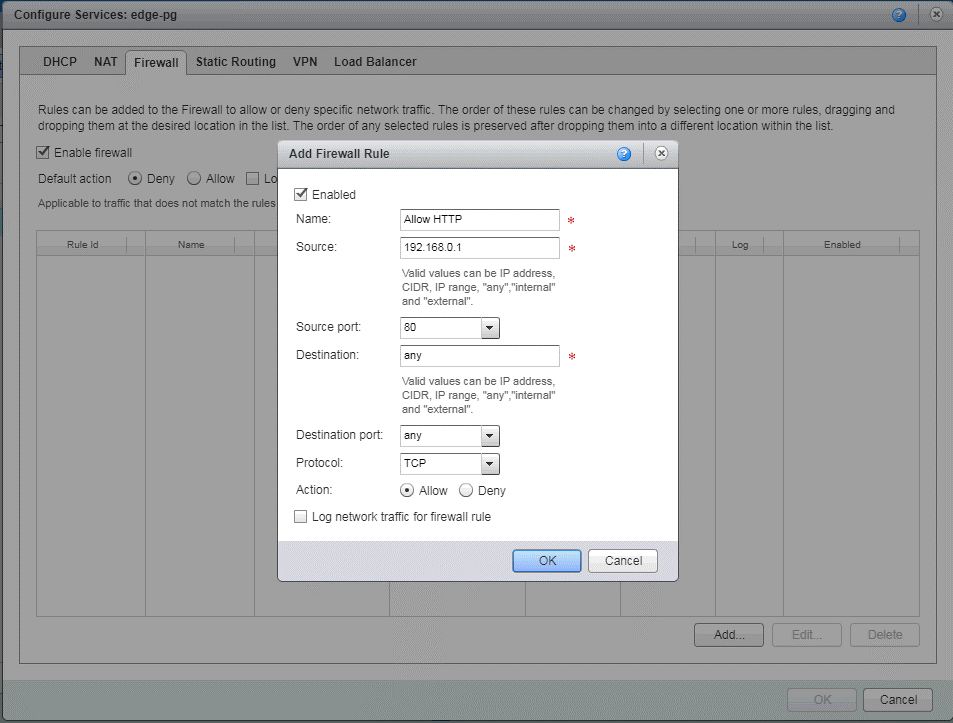
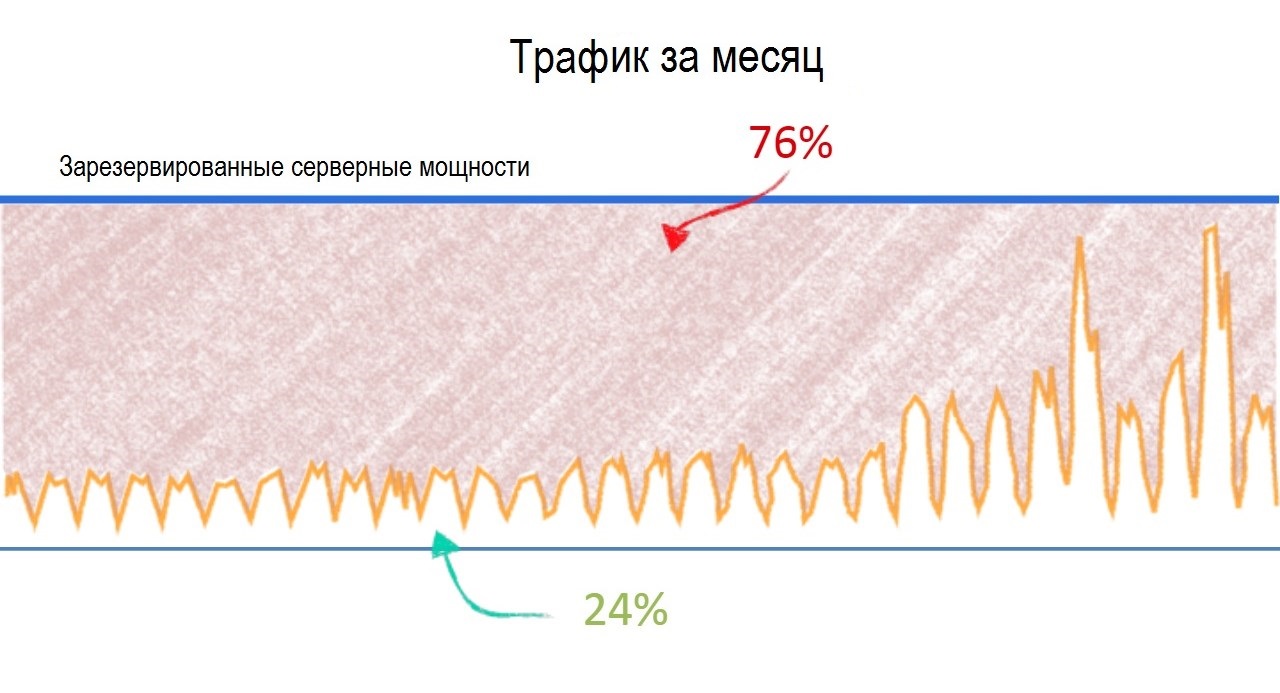
Ниже в статье — базовые вещи на тот случай, чтобы можно было легче договориться с провайдером о зонах ответственности и внедрить лучшие практики обеспечения информационной безопасности. Соответственно разделение зон ответственности и практики по ИБ мы используем в Техносерв Cloud для заказчиков с гибридными средами и потому знаем, что и где может пойти не так.




 Часто, когда я говорю кому-то про уязвимость, на меня смотрят как на сумасшедшего с табличкой «Покайтесь, ибо конец света близок»!
Часто, когда я говорю кому-то про уязвимость, на меня смотрят как на сумасшедшего с табличкой «Покайтесь, ибо конец света близок»!