
Бывала у вас такая ситуация. Выходит новая нейронная сеть и все руководство начинает требовать внедрить её? Половина коллег восторженно рассказывает о новом слое который позволил повысить точность сети? YoloV(N+1)? LLAMA100?

Программист
Бывала у вас такая ситуация. Выходит новая нейронная сеть и все руководство начинает требовать внедрить её? Половина коллег восторженно рассказывает о новом слое который позволил повысить точность сети? YoloV(N+1)? LLAMA100?

Данные - это важный компонент системы. Приложение может хранить их где угодно, но в результате все сводится к файлам. Файлы - это хорошая абстракция, но она протекает: если не знать того, как работают ОС или гарантии файловой системы, то легко выстрелить себе в ногу.
Меня увлекла тема отказоустойчивости, а конкретно - отказоустойчивой работы с файлами. В этой статье я попытался соединить все полученные знания:
Кто участвует в процессе записи
Ошибки, которые могут произойти
Что от нас зависит, а что нет
И самое главное - как это этого защититься

Обзор методов кодирования позиций токенов в нейросетевых моделях Transformer с упором на обработку длинных текстов. Для тех, кто учит и использует LLM, и для всех интересующихся.




Дизайнеры продукта получают тонны пользовательского фидбека по разным каналам. Это могут быть как результаты UX-исследований, так и тикеты от поддержки, замечания коллег, пожелания запилить ту или иную фичу от клиентов, бизнеса или маркетинга, отзывы и жалобы из сторов, сайтов с рейтингами или соцсетей. И даже это – лишь малая часть списка.
Фидбек от пользователей это всегда ценные вводные. Но если относится к этим вводным без достаточной доли осторожности, собранный фидбек может превратиться в бессмысленный список задач в бэклоге, в котором эти задачи приоритезированы по принципу «кто громче и чаще орал». Что, в свою очередь, приводит к распылению ресурсов команды, а сам продукт становится результатом скорее компромисса, чем результатом чёткого видения. На пользовательский опыт такой процесс разработки тоже влияет – есть немаленькие шансы, что он будет неконстистентным и непродуманным.
“Что с этим делать?” - спросите вы.

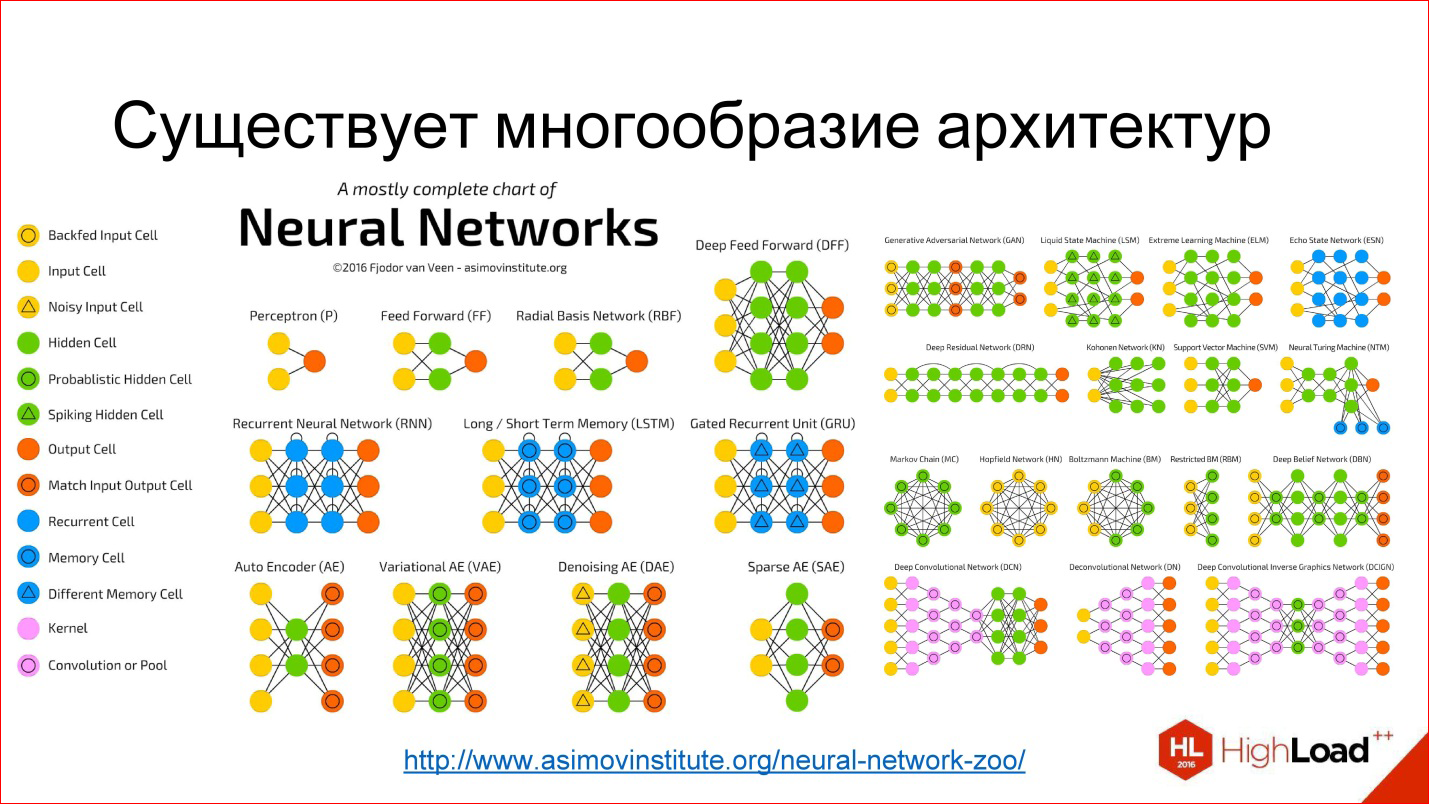
Сейчас в сфере ML постоянно слышно про невероятные "успехи" трансформеров в разных областях. Но появляется все больше статей о том, что многие из этих успехов мягко говоря надуманы (из недавнего помню статью про пре-тренировку больших CNN в компьютерном зрении, огромную MLP сетку, статью про деконструкцию достижений в сфере трансформеров).
Если очень коротко просуммировать эти статьи — примерно все более менее эффективные нерекуррентные архитектуры на схожих вычислительных бюджетах, сценариях и данных будут показывать примерно похожие результаты.
Тем не менее у self-attention модуля есть ряд плюсов: (i) относительная простота при правильной реализации (ii) простота квантизации (iii) относительная эффективность на коротких (до нескольких сотен элементов) последовательностях и (iv) относительная популярность (но большая часть имплементаций имеет код раздутый раз в 5).
Также есть определенный пласт статей про улучшение именно асимптотических свойств self-attention модуля (например Linformer и его аналоги). Но несмотря на это, если например открыть список пре-тренированных языковых моделей на основе self-attention модулей, то окажется, что "эффективных" моделей там буквально пара штук и они были сделаны довольно давно. Да и последовательности длиннее 500 символов нужны не очень часто (если вы не Google).
Попробуем ответить на вопрос — а как существенно снизить размер и ускорить self-attention модуль и при этом еще удовлетворить ряду production-ready требований:





Привет, Хабр! По традиции, представляем вашему вниманию дюжину рецензий на научные статьи от членов сообщества Open Data Science из канала #article_essense. Хотите получать их раньше всех — вступайте в сообщество ODS!
Статьи выбираются либо из личного интереса, либо из-за близости к проходящим сейчас соревнованиям. Напоминаем, что описания статей даются без изменений и именно в том виде, в котором авторы запостили их в канал #article_essence. Если вы хотите предложить свою статью или у вас есть какие-то пожелания — просто напишите в комментариях и мы постараемся всё учесть в дальнейшем.
Статьи на сегодня:


Предупреждение: в статье присутствуют заголовки реальных новостей. Я отношусь к ним исключительно как к рабочему материалу, не представляю какую-либо точку зрения на политическую или экономическую ситуацию в какой бы то ни было стране.

Привет, Хабр! Сегодня я хочу рассказать вам, как можно изменить свое лицо на фото, используя довольно сложный пайплайн из нескольких генеративных нейросетей и не только. Модные недавно приложения по превращению себя в даму или дедушку работают проще, потому что нейросети медленные, да и качество, которое можно получить классическими методами компьютерного зрения, и так хорошее. Тем не менее, предложенный способ мне кажется очень перспективным. Под катом будет мало кода, зато много картинок, ссылок и личного опыта работы с GAN'ами.

Привет, Хабр! Мы продолжаем нашу традицию и снова выпускаем ежемесячный набор рецензий на научные статьи от членов сообщества Open Data Science из канала #article_essense. Хотите получать их раньше всех — вступайте в сообщество ODS!
Статьи выбираются либо из личного интереса, либо из-за близости к проходящим сейчас соревнованиям. Напоминаем, что описания статей даются без изменений и именно в том виде, в котором авторы запостили их в канал #article_essence. Если вы хотите предложить свою статью или у вас есть какие-то пожелания — просто напишите в комментариях и мы постараемся всё учесть в дальнейшем.