В предыдущей статье говорилось о том как работает агрегат WITH ROLLUP. В этой статье мы рассмотрим, как реализована агрегация WITH CUBE. Как и предложение WITH ROLLUP, предложение WITH CUBE позволяет просчитать несколько «уровней» агрегации в одном операторе. Разницу между двумя этими агрегатами давайте рассмотрим на примере. Мы будем использовать те же вымышленные данные о продажах, что и в прошлый раз.

Пользователь
Chat GPT как замена системного аналитика: сравнение эффективности
9 min
Analytics

Сегодня тяжело найти человека, который бы не слышал прогнозов о том, что нейросети уже готовы заменить системных аналитиков, в особенности на этапе формирования требований к новым системам. Например, тренер в школы системного анализа, ИТ-архитектор в “Systems.Education“ Юрий Куприянов ещё год назад писал на Хабре о том, что системные аналитики с junior level рискуют потерять работу, т.к их способен заменить ИИ. Аналогичные выводы сделал наш руководитель практики технологических решений Виталий Волнянский в своих комментариях и публикациях о нейросетях в СМИ.
Между тем, из ЕАЕ-Консалт после релиза Chat GPT до настоящего времени не был уволен ни один сотрудник, занимающийся системным анализом. Более того, среди знакомых мне системных интеграторов, компаний, разрабатывающих сложный софт для промышленности, крупного ритейла и систем безопасности (например, на основе компьютерного зрения), также не было массовых увольнений специалистов моего профиля. Более того, только на Хабр карьера в настоящий момент 479 вакансий системных аналитиков, профессия остаётся крайне востребованной и за пределами России, например считается дефицитной в США. В посте предлагаю данные небольшого сравнительного исследования, не претендую на научную репрезентативность, но полагаю, что результаты, отчасти, раскрывают причины того, о чем я написал выше.
Как был создан потоковый SQL-движок
10 min
Translation

Возможно, вы как раз их тех, кто, просыпаясь каждое утро, задаёт себе три самых вечных жизненных вопроса: 1) как мне сделать потоковый SQL‑движок? 2) Что это такое — потоковый SQL‑движок? 3) Способен ли Господь наш сбрасывать те таблицы, коими владеет иной пользователь?
Я тоже ловил себя на том, что задаю себе эти вопросы, и порой они не оставляют меня даже во сне. Мне снятся различные SQL‑операторы, которые тычут в меня пальцем, насмехаются над моей некомпетентностью, а я умоляю их, чтобы они ответили на эти вопросы.
Так вот, где‑то год назад я (довольно смело, если «смелость» — это вообще про меня) снарядился как следует и пустился в долгий и тернистый путь, искать ответы на эти вопросы. Я шёл от монаха к пресвитеру, а от того — к жрецу макаронного монстра, и только в ужасе осознавал, сколь жалкие вопросы их занимают — например, каков смысл жизни, и как обрести мир с самим собой. Но, в конце концов, потерявшись в глубочайших расщелинах моего разума, я набрёл на часовенку, над входом которой значилось: «Epsio Labs». Тут я преисполнился откровения и вошёл в двери этого храма.
Друзья, сегодня я поделюсь с вами теми таинствами, которые познал там (за исключением тех, что подпадают под многочисленные NDA).
Прохожу собеседование у бота на английском для подготовки к реальному
Easy
4 min
Review
Привет, Хабр! Недавно я вышел на рынок вакансий и решил рассказать о том, что происходит на собеседованиях и как к ним готовиться.
Интерактивный парсер web страниц
Easy
2 min

Всем привет. Меня зовут Влад и по профессии я Java Backend.
Для начала вкратце введу в курс дела. 3 года назад ко мне в голову закралась навязчивая мысль написать интерактивный словарь-помощник для чтения на английском языке. И с тех пор начались мои приключения в мире расширений для браузеров на ядре Chrome'а.
Mimesis: идеальное решение для генерации данных
Easy
6 min

Сбор данных имеет решающее значение для каждого проекта, связанного с машинным обучением. Однако не всегда искомые данные существуют или общедоступны. Во многих случаях получение данных является дорогостоящим или затрудненным из-за внешних условий. Кроме того, правила конфиденциальности влияют на способы использования или распространения набора данных. По всем этим причинам использование синтетических данных является хорошей альтернативой, поскольку с их помощью можно удовлетворить те же потребности без особых усилий.
В этой статье мы рассмотрим один из лучших пакетов для генерации синтетических данных.
Solutions architect, который не пишет код
Medium
4 min
Review
В данной статье рассматривается профстандарт архитектора ПО (06.003).
Чем он занимается и как им стать.
Данной статьей я преследую цель ознакомить аудиторию с профстандартом архитектора программного обеспечения, чтобы дискуссии/диалоги велись с единым пониманием терминов, а также для расширения общего кругозора тех экспертов, кому это необходимо.
Как мы создавали и внедряли свою матрицу компетенций
7 min
Привет, Хабр!
Сегодня поговорим про матрицы компетенций и, как мы их внедряли в «Рексофт». Мы уже рассказывали про матрицу Android-программиста, и как мы вводили кросс-интервью при повышении грейда, а сегодня я расскажу, о том, как все начиналось и куда мы пришли. Итак, поехали!
Как в 180 000 раз ускорить анализ данных с помощью Rust
Medium
18 min
Tutorial
Translation

В этой статье я опишу одно из последних своих дерзновений в сфере оптимизации производительности с помощью Rust. Надеюсь, что в ней вы откроете для себя какие-то новые приёмы для написания быстрого кода на Rust.
Clickhouse — непростая жизнь в продакшене
Hard
13 min
Case

Около двух лет назад вышла небольшая статья Kafka Streams — непростая жизнь в production, в которой я описывал сложности, с которыми наша команда столкнулась при попытке решить задачи проекта с помощью kafka-streams. Эксперимент вышел неудачным, и мы в итоге совсем отказались от этой технологии. Вместо нее решили попробовать Clickhouse (CH), и сейчас уже можно сказать, что эта база нам очень хорошо подошла и отлично решает почти все задачи, которые нам ставит бизнес. В этой статье я расскажу об особенностях использования CH.
Искусство ETL. Пишем собственный движок SQL на Spark [часть 1 из 5]
Hard
18 min
Tutorial
В данной серии статей я подробно расскажу о том, как написать на Java собственный интерпретатор объектно-ориентированного диалекта SQL с использованием Spark RDD API, заточенный на задачи подготовки и трансформации наборов данных.
— Евдокимов, ты что, совсем уже там кукухой поехал?! При живом-то Spark SQL! Опять ты ненормальным программированием маешься, нет бы что-то полезное делал…
— Ну-ну-ну, спокойно, спокойно. Я ещё настолько не уехал, чтобы потратить целый год на страдание полной ерундой. Речь на сей раз пойдёт не о развлекухе, а о диалекте языка, специализированном для решения целого класса задач, для которых любой существующий SQL был бы, в теории, хорошим решением, если бы не несколько серьёзных «но».
Короче, у нас будет немного не такой SQL, который вы все так хорошо знаете, но и этот вариант вы полюбите, я обещаю. Тут лучше другой вопрос задать:
— Разве кому-то нужен голый SQL-ный движок?
Нет, голый — не нужен. Так рассказывать я буду о разработке настоящего production ready инструмента, с интерактивным шеллом с подсветкой синтаксиса и автодополнением, который сможет работать в клиент-серверном режиме, и не только на кластере, но и локально. Да не монолитный, а расширяемый при помощи подключаемых функций. И с автогенератором документации впридачу. Короче, всё будет совсем по-взрослому, с рейтингом M for Mature.
В каком смысле «M for Mature»?
Уровень сложности данной серии статей — высокий. Базовые понятия по ходу текста вообще не объясняются, да и продвинутые далеко не все. Поэтому, если вы не разработчик, уже знакомый с терминологией из области бигдаты и жаргоном из дата инжиниринга, данные статьи будут сложно читаться, и ещё хуже пониматься. Я предупредил.
Архитектурные решения для обработки потоковых данных
22 min

Под потоковыми данными понимаются непрерывно поступающие и быстро изменяющиеся информационные потоки, генерируемые различными источниками, такими как сенсоры, логи приложений, социальные сети, интернет вещей и многие другие. Эти данные часто характеризуются высокой скоростью поступления, большим объемом и коротким временем жизни.
Важность потоковых данных заключается в их способности предоставлять актуальную информацию в режиме реального времени. Они позволяют нам вовремя реагировать на события, принимать обоснованные решения и адаптироваться к меняющимся условиям. Эта актуальность имеет особенное значение во многих областях, начиная от бизнеса и финансов и заканчивая медициной и научными исследованиями.
С каждым днем интерес к обработке потоковых данных становится все более заметным. зовами, связанными с обработкой данных в высокоскоростных потоках.
Идиоматический код на Rust для тех, кто перешел с других языков программирования
Medium
6 min
Tutorial
Привет, дорогие читатели! В предыдущей моей статье "Как легко перейти с Java на Rust" я делился с вами советами по переходу на Rust и уменьшению количества "потерянной крови" на этом пути. Но что делать дальше, когда вы уже перешли на Rust, и ваш код хотя бы компилируется и работает? Сегодня я хочу поделиться с вами некоторыми идеями о том, как писать идиоматический код на Rust, особенно если вы привыкли к другим языкам программирования.
MongoDB vs PostgreSQL. Сравнение документо-ориентированной и реляционной базы данных
Easy
6 min
Opinion

Дети часто задаются вопросом - кто сильнее, кит или слон? каратист или боксер? В этой статье мы попробуем ответить на на похожий вопрос, сравнив SQL (ну или почти SQL) базу данных PostgreSQL и NoSQL базу данных MongoDB. И понять, для каких проектов лучше подойдет реляционная PostgreSQL, а для каких MongoDB.
Данное сравнение также важно, потому что, учитывая новый функционал, MongoDB стала обладать некоторыми качествами SQL СУБД, включая многодокументные ACID-транзакции, вторичный индекс и расширенные возможности запросов. А PostgreSQL расширяет возможности работы с JSON, включаяиндексирование и оптимизацию запросов.
Redpanda в сравнении с Apache Kafka: Сопоставление эксплуатационных затрат
12 min
Translation

В этой статье мы исследуем общие затраты на функционирование кластеров Apache Kafka и Redpanda для потоковой передачи данных и пропускной способности в реальных условиях с использованием модели развертывания с собственным хостингом. Мы начнем с определения модели затрат, протестируем физические характеристики обеих систем с использованием репрезентативных конфигураций, включая аспекты безопасности и аварийное восстановление (Disaster Recovery, DR), и затем оценим их инфраструктурные, административные и общие затраты.
Книга «Современный подход к программной архитектуре: сложные компромиссы»
23 min
 Привет, Хаброжители!
Привет, Хаброжители!В архитектуре программного обеспечения нет простых решений. Напротив, есть масса сложностей — задач и проблем, для решения которых нет готовых ответов и приходится выбирать между различными компромиссами. Эта книга научит вас критически относиться к компромиссам, связанным с распределенными архитектурами.
Опытные архитекторы Нил Форд, Марк Ричардс, Прамод Садаладж и Жамак Дехгани обсуждают стратегии выбора архитектуры, подходящей для тех или иных случаев. История Sysops Squad — вымышленной группы специалистов — позволяет исследовать все аспекты выбора архитектуры: от определения степени гранулярности сервисов, управления рабочими процессами и оркестрации, разделения контрактов и управления распределенными транзакциями до оптимизации таких операционных характеристик, как масштабируемость, адаптируемость и производительность.
Обработка больших и очень больших графов
Medium
18 min

Однажды ко мне обратилась одна крупная фруктовая телефонная компания с просьбой подготовить для них курс по Apache Spark продвинутого уровня, и в нем обязательно должен быть раздел про обработку графов (Neo4j не предлагать). На тот момент я знал про классические алгоритмы обработки графов на базе DFS (поиск в глубину) и BFS (поиск в ширину). При этом неотъемлемым условием применения того или иного подхода является локальная поддержка стека (DFS) или очереди (BFS). Следовательно, классические алгоритмы можно применять для обработки графов, которые умещаются в память одной машины.
В современном мире данные накапливаются очень быстро, и классические подходы, ориентированные на обработку графов в рамках одной машины, перестают работать, а значит высока потребность в алгоритмах распределенной обработки графов. Интуитивно можно предположить, что необходимо разбивать граф на части, но каким образом и как потом их собирать вместе?
Dagster и Great Expectations: Интеграция без боли
Medium
11 min

Меня зовут Артем Шнайдер, и я занимаюсь DataScience в Бланке. Сегодня я хочу рассказать вам о том, как можно интегрировать два мощных инструмента – Dagster и Great Expectations.
Great Expectations позволяет определить так называемые ожидания от ваших данных, то есть задать правила и условия, которым данные должны соответствовать.
Dagster, с другой стороны, это платформа с открытым исходным кодом для управления данными, которая позволяет создавать, тестировать и развертывать пайплайны данных. Написан на python, что позволяет пользователям гибко настраивать и расширять его функциональность.
Исходный код к этой статье на GitHub.
Давайте начнем? :-)
Как сделать быстрый дашборд по таблице из 150 млн строк с помощью Yandex DataLens и ClickHouse
Medium
6 min
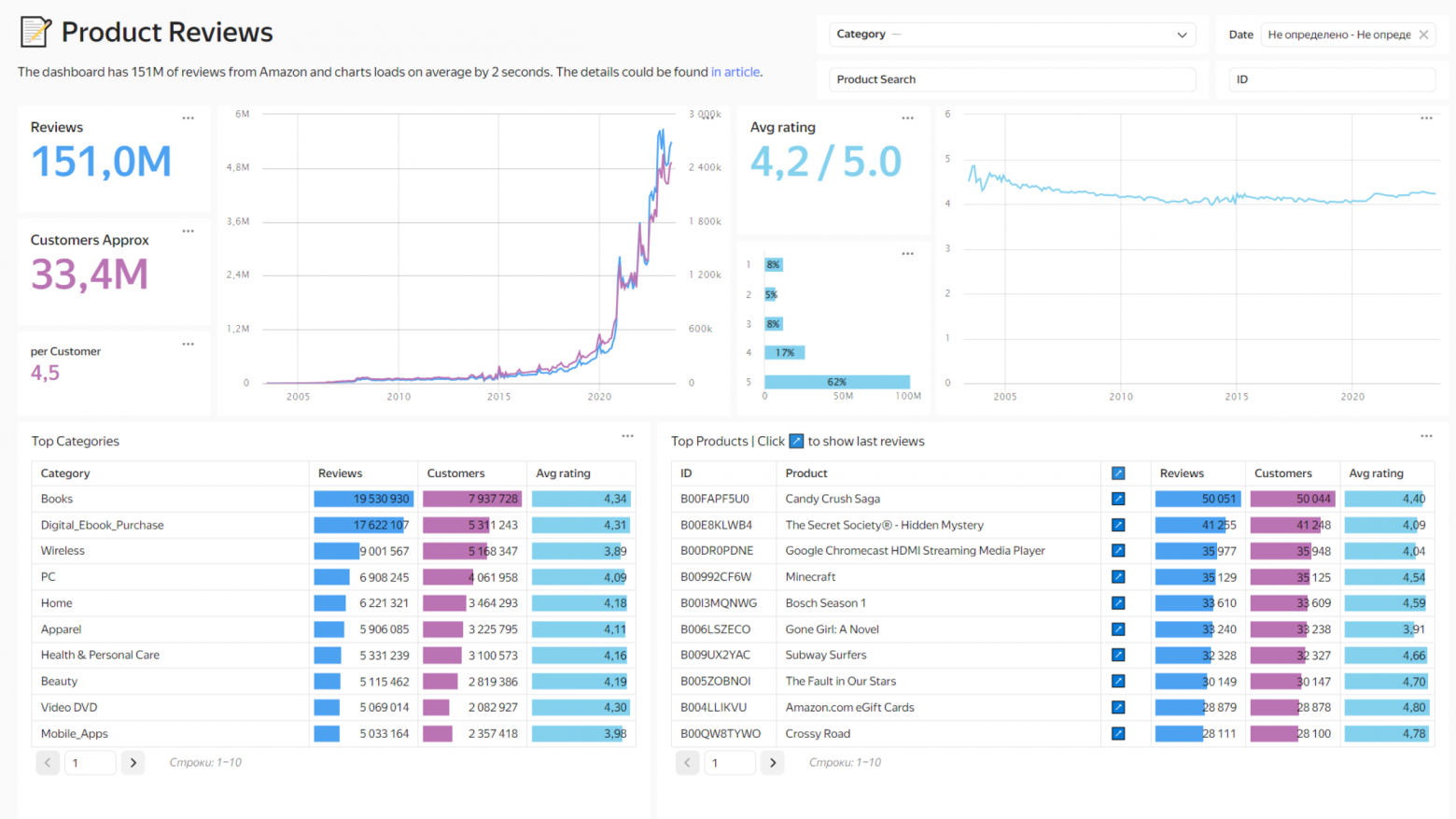
Привет! Меня зовут Роман Бунин, я BI-евангелист Yandex DataLens. При росте объёма данных, что неизбежно для любой компании, загрузка дашбордов может замедляться до десятков секунд. И чем больше появляется данных, тем медленнее становятся дашборды, особенно если вы хотите строить их по детализированным таблицам.Связка базы данных ClickHouse и BI-системы Yandex DataLens — популярное решение для анализа данных: эти инструменты нативно интегрируются и быстро работают вместе. В этой статье вместе с моим коллегой, архитектором Yandex Cloud Игорем Путятиным, покажем, как на основе таблицы из 150 миллионов строк построить максимально быстрый дашборд, и расскажем о технических ограничениях.
Три месяца ошибок, или как я создала чек-лист для проверки ТЗ
Easy
7 min
Case

Привет! Меня зовут Настя, я системный аналитик в X5 Tech. В этой статье хочу поделиться своим опытом создания чек-листа для технического задания (далее – ТЗ), какие ошибки совершала на начальных этапах работы над продуктом, и как сформированный чек-лист помогает мне уже на протяжении трёх лет. Такой чек-лист может пригодиться не только для самостоятельной работы над ТЗ, но и как инструмент проверки уже готового документа.
Статья будет полезна, как мне кажется, системным и бизнес-аналитикам, владельцам продуктов и тем, кто работает с разработкой требований.