
Существуют три вида лжи: ложь, наглая ложь и статистика (источник)
Есть такой замечательный жанр — "вредные советы", в котором детям дают советы, а дети, как известно, всё делают наоборот и получается всё как раз правильно. Может быть и со всем остальным так получится?
Статистика, инфографика, big data, анализ данных и data science — этим сейчас кто только не занят. Все знают как правильно всем этим заниматься, осталось только кому-то написать как НЕ нужно этого делать. В данной статье мы именно этим и займемся.
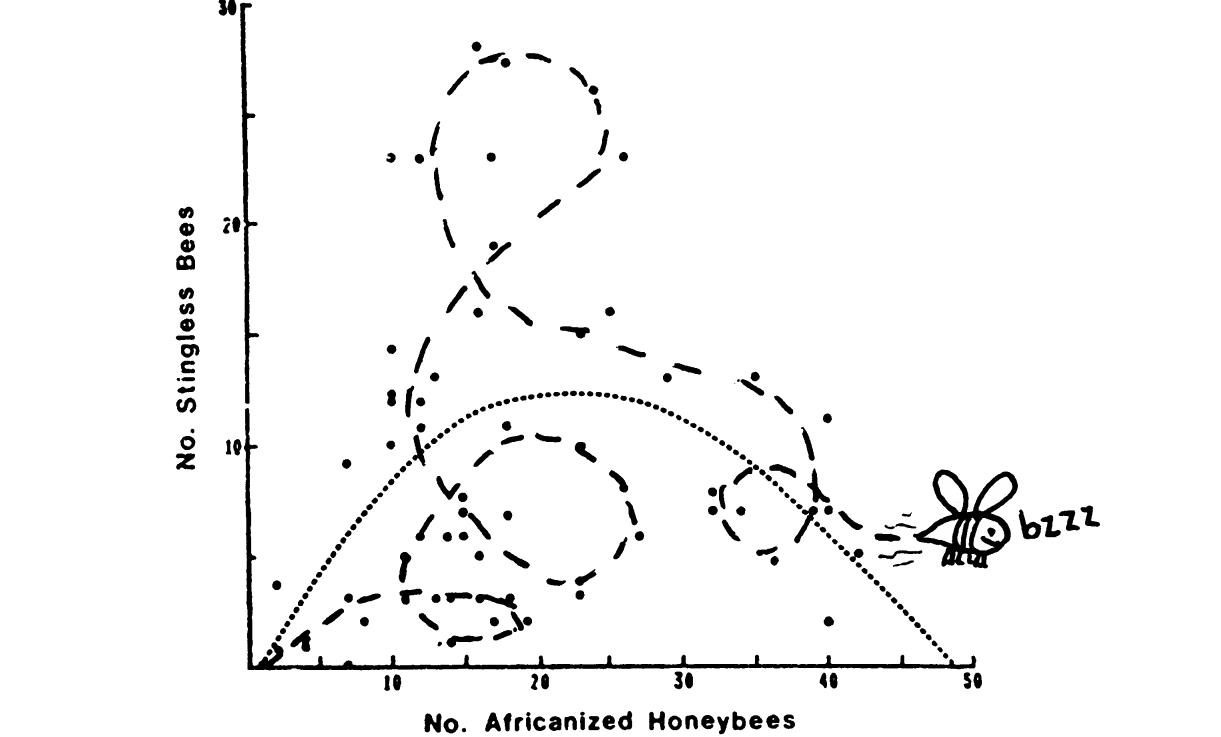
Hazen Robert "Curve fitting". 1978, Science.
Структура статьи:
- Введение
- Предвзятая выборка (Sampling bias)
- Правильно выбираем среднее (Well-chosen average)
- И еще 10 неудачных экспериментов, про которые мы не написали
- Играем со шкалой
- Выбираем 100%
- Скрываем нужные числа
- Визуальная метафора
- Пример качественной визуализации
- Заключение и дальнейшее чтение


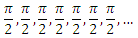
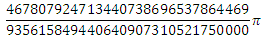
 (ну и 1 при x = 0, хотя неважно). Тогда каждый член ряда — это значение следующего интеграла в цепочке:
(ну и 1 при x = 0, хотя неважно). Тогда каждый член ряда — это значение следующего интеграла в цепочке: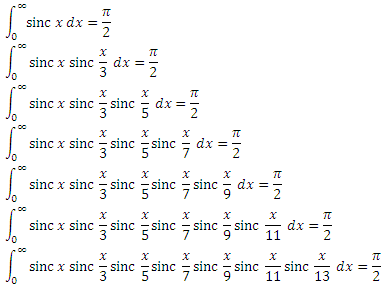




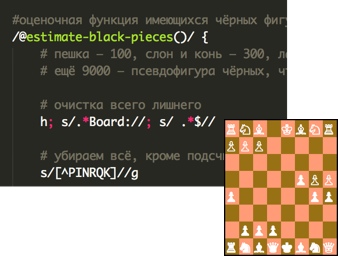 В Линуксе и многих других системах существует утилита командной строки sed («сед») — это несложный редактор, которые преобразует текст, попадающий ему на вход при помощи несложных команд.
В Линуксе и многих других системах существует утилита командной строки sed («сед») — это несложный редактор, которые преобразует текст, попадающий ему на вход при помощи несложных команд.



 Мультиязычные сайты — это хорошо, но довольно муторно. И если для
Мультиязычные сайты — это хорошо, но довольно муторно. И если для