
Понимание ООП в JavaScript [Часть 1]
16 min
Tutorial
Translation
— Прототипное наследование — это прекрасно
JavaScript — это объектно-ориентированный (ОО) язык, уходящий корнями в язык Self, несмотря на то, что внешне он выглядит как Java. Это обстоятельство делает язык действительно мощным благодаря некоторым приятным особенностям.
Одна из таких особенностей — это реализация прототипного наследования. Этот простой концепт является гибким и мощным. Он позволяет сделать наследование и поведение сущностями первого класса, также как и функции являются объектами первого класса в функциональных языках (включая JavaScript).
К счастью, в ECMAScript 5 появилось множество вещей, которые позволили поставить язык на правильный путь (некоторые из них раскрыты в этой статье). Также будет рассказано о недостатках дизайна JavaScript и будет произведено небольшое сравнение с классической моделью прототипного ОО (включая его достоинства и недостатки).
JavaScript — это объектно-ориентированный (ОО) язык, уходящий корнями в язык Self, несмотря на то, что внешне он выглядит как Java. Это обстоятельство делает язык действительно мощным благодаря некоторым приятным особенностям.
Одна из таких особенностей — это реализация прототипного наследования. Этот простой концепт является гибким и мощным. Он позволяет сделать наследование и поведение сущностями первого класса, также как и функции являются объектами первого класса в функциональных языках (включая JavaScript).
К счастью, в ECMAScript 5 появилось множество вещей, которые позволили поставить язык на правильный путь (некоторые из них раскрыты в этой статье). Также будет рассказано о недостатках дизайна JavaScript и будет произведено небольшое сравнение с классической моделью прототипного ОО (включая его достоинства и недостатки).

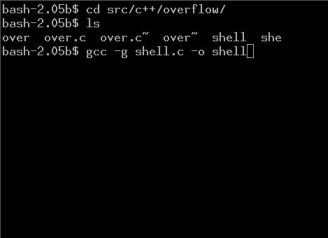 Одной из важных особенностей IDE является встроенная система управления файлами. Она должна включать в себя как базовые возможности, такие как переименование, удаление перемещение, так и более специфические для разработки: компиляция и проверка синтаксиса. Вдобавок было бы удобно оперировать группами файлов для поиска по размеру, расширению или по маске. В этой первой статье я покажу несколько вариантов использования инструментов, знакомых любому пользователю Linux, для работы с группами файлов в проекте.
Одной из важных особенностей IDE является встроенная система управления файлами. Она должна включать в себя как базовые возможности, такие как переименование, удаление перемещение, так и более специфические для разработки: компиляция и проверка синтаксиса. Вдобавок было бы удобно оперировать группами файлов для поиска по размеру, расширению или по маске. В этой первой статье я покажу несколько вариантов использования инструментов, знакомых любому пользователю Linux, для работы с группами файлов в проекте.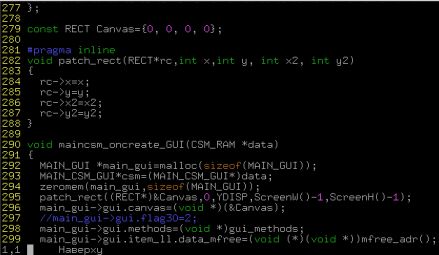 Текстовый редактор — это основной инструмент для любого программиста, вот почему вопрос его выбора становится причиной яростных дебатов. Unix традиционно тесно связан с двумя своими многолетними фаворитами, Emacs и Vi, и их современными версиями GNU Emacs и Vim. Эти редакторы имеют очень разный подход к редактированию текста, но при этом сравнимы по мощи.
Текстовый редактор — это основной инструмент для любого программиста, вот почему вопрос его выбора становится причиной яростных дебатов. Unix традиционно тесно связан с двумя своими многолетними фаворитами, Emacs и Vi, и их современными версиями GNU Emacs и Vim. Эти редакторы имеют очень разный подход к редактированию текста, но при этом сравнимы по мощи. 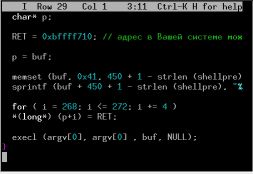 Профессиональные программисты, как новички, так и опытные, обычно придерживаются концепции IDE, или «интегрированной среды разработки». Правда, удобно же иметь самые необходимые средства организации, написания, поддержки и тестирования кода в одном приложении с единым интерфейсом для всех инструментов? К тому же, среда, специально спроектированная для программирования, дает ряд преимуществ, таких как автодополнение, проверка и подсветка синтаксиса.
Профессиональные программисты, как новички, так и опытные, обычно придерживаются концепции IDE, или «интегрированной среды разработки». Правда, удобно же иметь самые необходимые средства организации, написания, поддержки и тестирования кода в одном приложении с единым интерфейсом для всех инструментов? К тому же, среда, специально спроектированная для программирования, дает ряд преимуществ, таких как автодополнение, проверка и подсветка синтаксиса.