 Период скачка проблем с видео
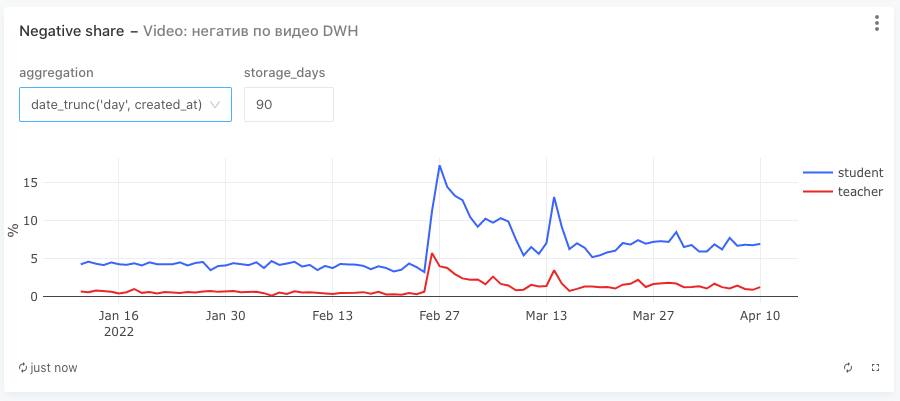
Период скачка проблем с видео
26 февраля у нас начались серьёзные проблемы с видеосвязью. Роскомнадзор начал замедлять трафик для Facebook (запрещённой в России организации). Если вы помните, как они блокировали Телеграм, когда из нормально работающих сервисов остался только он, то вот получилось примерно то же самое. Конкретно, как мы предполагаем, они закрывали целые подсети, и наши Янус-сервера для видео тоже попали под эти баны. Также, похоже, применялась какая-то маска по пакетам, потому что в Хроме видео отвалилось почти сразу, а вот в Firefox ещё работало. Проблемы были у всего WebRTC-сообщества.
Мы сначала по возможности переводили пользователей на другие браузеры, потом начали проксировать видеотрафик через другие страны, а затем подняли сборки видеосерверов на других протоколах.
Что гораздо хуже, с развитием ситуации стало понятно, что нас либо могут заблокировать, либо заблокируют самые разные сервисы, которые так или иначе использовались в стеке разработки и деплоя. Причём блокировки шли и по аккаунту регистрации (при наличии русского юрлица или русской карты), и по адресам почт (*.ru), и даже просто по источникам трафика из русских подсетей.
Ну и дополнительным приятным аккордом стало то, что опенсорс-библиотеки были дискредитированы, и просто включать их, как раньше, было нельзя: некоторые контрибьютеры контаминировали их.
Пришлось заняться большой уборкой, заменой вендоров и вообще масштабно рассмотреть все возможные риски.