
Наверное многие php разработчики используют профайлер xdebug для поиска узких мест в приложениях. Но просто смотреть логи очень не удобно, поэтому были созданы инструменты для их визуализации. Об этих инструментах я и хочу коротко рассказать.
Webgrind
Webgrind это набор php скриптов, которые можно установить на локальный или удаленный веб сервер. Дальше все просто до неприличия — закачиваем файл лога и смотрим статистику.
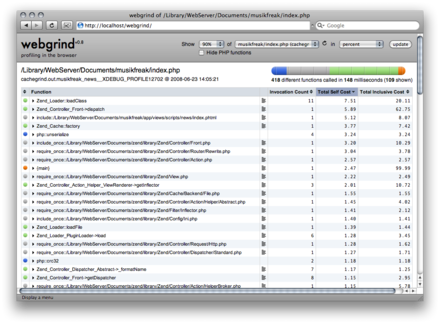
Самый очевидный плюс Webgrind'а это кроссплатформенность и простота установки.
Показывает список функций которые вызывались, количество вызовов (Invocation Count), общеё время потраченное на вызов (Total Self Cost) и общее время потраченное на выполнение (Total Inclusive Cost).
Можно скрыть php функции. Можно перейти внутрь функции, чтобы увидеть развернутую статистику.
Webgrind
Webgrind это набор php скриптов, которые можно установить на локальный или удаленный веб сервер. Дальше все просто до неприличия — закачиваем файл лога и смотрим статистику.

Самый очевидный плюс Webgrind'а это кроссплатформенность и простота установки.
Показывает список функций которые вызывались, количество вызовов (Invocation Count), общеё время потраченное на вызов (Total Self Cost) и общее время потраченное на выполнение (Total Inclusive Cost).
Можно скрыть php функции. Можно перейти внутрь функции, чтобы увидеть развернутую статистику.
 Здравствуйте. Хочу презентовать хабрасообществу альфа-версию новой open-source библиотеки на PHP для работы с примитивами(string, integer, float и array) как с объектами.
Здравствуйте. Хочу презентовать хабрасообществу альфа-версию новой open-source библиотеки на PHP для работы с примитивами(string, integer, float и array) как с объектами.





 Каждый раз, когда я ищу информацию в сети по
Каждый раз, когда я ищу информацию в сети по 
 Регулярные выражения — это арифметика для алгоритмов. Они доступны во многих языках программирования, редакторах и настройках приложений. Как и сложение с умножением они просты в использовании.
Регулярные выражения — это арифметика для алгоритмов. Они доступны во многих языках программирования, редакторах и настройках приложений. Как и сложение с умножением они просты в использовании.