Приветствую.
Существует приложение для iOS — Tydlig, которое буквально переосмысливает калькулятор, и делает его потрясающе удобным. Попользовавшись один раз этим приложением, остаешься его любителем.
Однако для бытового использования на десктопе ничего удобнее, чем консоль браузера, по моему мнению, нет. В консоли можно использовать переменные, функции, работать с выражениями как с текстом — выделять, копировать и вставлять. Это удобно, и многие годы консоль верно заменяла мне калькулятор даже для самых простых операций.
Ввиду специфики работы, проводить различные вычисления приходится часто, и со временем появилось ощущение, что в консоли чего-то не хватает. Не хватает того самого динамического обновления значений, как в Tydlig.
Поиск чего-то похожего на Tydlig ничего не дал, и было принято решение писать свое приложение.
Что из этой затеи получилось:
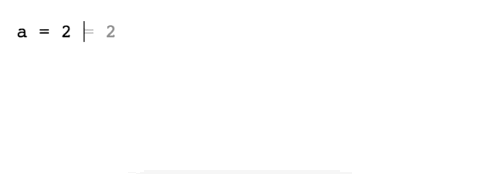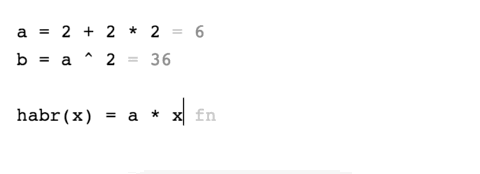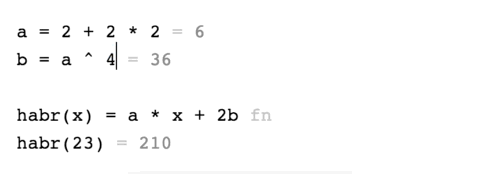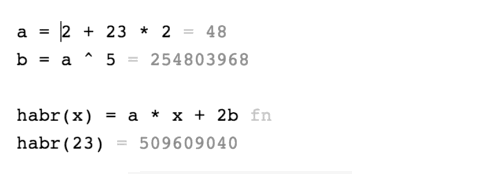
Существует приложение для iOS — Tydlig, которое буквально переосмысливает калькулятор, и делает его потрясающе удобным. Попользовавшись один раз этим приложением, остаешься его любителем.
Однако для бытового использования на десктопе ничего удобнее, чем консоль браузера, по моему мнению, нет. В консоли можно использовать переменные, функции, работать с выражениями как с текстом — выделять, копировать и вставлять. Это удобно, и многие годы консоль верно заменяла мне калькулятор даже для самых простых операций.
Ввиду специфики работы, проводить различные вычисления приходится часто, и со временем появилось ощущение, что в консоли чего-то не хватает. Не хватает того самого динамического обновления значений, как в Tydlig.
Поиск чего-то похожего на Tydlig ничего не дал, и было принято решение писать свое приложение.
Что из этой затеи получилось: