Соревнование Data Fusion Contest 2023 в этом году состоялось во второй раз и собрало сильнейшие индустриальные команды и отдельных любителей моделей алгоритмов машинного обучения. Кто-то участвовал впервые, а кто-то, уже умудрённый прошлым опытом был явно настроен только на победу.
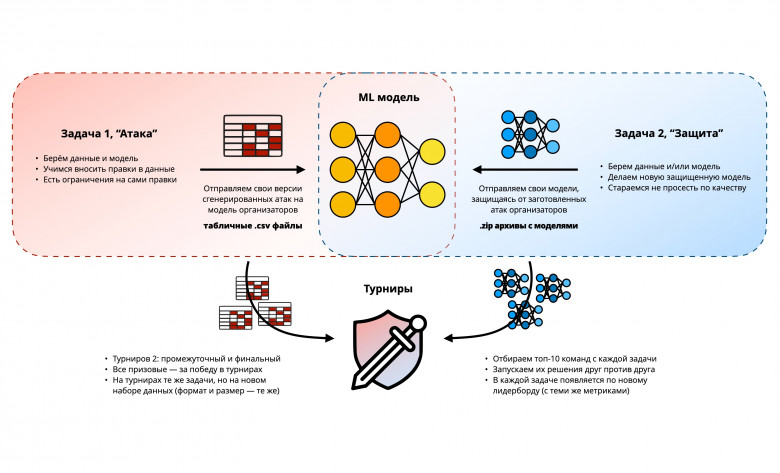
В этот раз мы решили принципиально изменить задание и придумали новый формат. Что произойдет, если столкнуть лицом к лицу участников, мотивированных атаковать модели машинного обучения, с другими участниками, мотивированными свои модели защищать? Кто победит, каким окажется тот стек моделей и подходов, который приведет к победе? Что важнее, знания и опыт, или гибкость ума или нестандартные подходы?
Мы задали себе все эти вопросы и решили найти ответы на практике, подготовив для участников Data Fusion Contest 2023 очень нестандартное и по теме и по формату соревнование по Adversarial ML с атаками на модели машинного обучения, а также с их защитой.
Давайте разбираться, что из этого получилось по факту, и какие решения предложили участники, чтобы оказаться в рядах победителей!