Вы наверняка знакомы с ситуацией, когда при обращении в какую-либо крупную организацию приходится подавать целый пакет документов, точнее пакет их сканов. И это в век «цифры»! Теперь посмотрите на это глазами второй стороны и представьте, что у вас миллионы таких заявок со сканами, и они… не содержат информации о границах документов. Апокалипсис? Всё придётся сегментировать вручную? К счастью, существуют алгоритмы автоматической сегментации потоков многостраничных документов. Здесь мы расскажем о новом подходе в сегментации с использованием модели BERT.

Data Scientist
Основы статистики: просто о сложных формулах
6 min
Статистика вокруг нас
Статистика и анализ данных пронизывают практически любую современную область знаний. Все сложнее становится провести границу между современной биологией, математикой и информатикой. Экономические исследования и регрессионный анализ уже практически неотделимы друг от друга. Один из известных методов проверки распределения на нормальность — критерий Колмогорова-Смирнова. А вы знали, что именно Колмогоров внес огромный вклад в развитие математической лингвистики?
Еще будучи студентом психологического факультета СПбГУ, я заинтересовался когнитивной психологией. Кстати, Иммануил Кант не считал психологию наукой, так как не видел возможности применять в ней математические методы. Мои текущие исследования посвящены моделированию психических процессов, и я надеюсь, что такие направления в современной когнитивной психологии, как вычислительные и коннективисткие модели, смягчили бы его отношение!
Прогноз нестационарного ряда, или как жить дата-сайентисту в 2020 году
13 min
Пандемия и карантин изменили жизнь и поведение практически каждого жителя планеты. При этом некоторые изменения являются краткосрочными и исчезают со снятием карантинных мер, а другие могут остаться с нами надолго, возможно даже навсегда.
Мы, в Dentsu Aegis Network, в том числе прогнозируем изменения в поведении людей в части потребления видеоконтента, это необходимо для эффективного размещения рекламы наших клиентов в разных медиа. О том, как мы прогнозируем телесмотрение и насколько хорошо у нас это получается в реалиях динамично меняющегося 2020 года, и пойдёт речь в этой статье.
Простейший голосовой помощник на Python
4 min

Для создания голосового помощника не нужно обладать большими знаниями в программировании, главное понимать каким функционалом он должен владеть. Многие компании создают их на первой линии связи с клиентом для удобства, оптимизации рабочих процессов и наилучшей классификации звонков. В данной статье представлена программа, которая может стать основой для Вашего собственного чат-бота, а если точнее – голосового помощника для распознавания голоса и последующего выполнения команд. С ее помощью мы сможем понять принцип работы наиболее часто встречаемых голосовых помощников.
Искусственный интеллект в поиске. Как Яндекс научился применять нейронные сети, чтобы искать по смыслу, а не по словам
12 min
Сегодня мы анонсировали новый поисковый алгоритм «Палех». Он включает в себя все те улучшения, над которыми мы работали последнее время.
Например, поиск теперь впервые использует нейронные сети для того, чтобы находить документы не по словам, которые используются в запросе и в самом документе, а по смыслу запроса и заголовка.

Уже много десятилетий исследователи бьются над проблемой семантического поиска, в котором документы ранжируются, исходя из смыслового соответствия запросу. И теперь это становится реальностью.
В этом посте я постараюсь немного рассказать о том, как у нас это получилось и почему это не просто ещё один алгоритм машинного обучения, а важный шаг в будущее.
Например, поиск теперь впервые использует нейронные сети для того, чтобы находить документы не по словам, которые используются в запросе и в самом документе, а по смыслу запроса и заголовка.
Уже много десятилетий исследователи бьются над проблемой семантического поиска, в котором документы ранжируются, исходя из смыслового соответствия запросу. И теперь это становится реальностью.
В этом посте я постараюсь немного рассказать о том, как у нас это получилось и почему это не просто ещё один алгоритм машинного обучения, а важный шаг в будущее.
Более эффективное предварительное обучение NLP моделей с ELECTRA
5 min
Translation
Последние разработки в области предварительного обучения языковых моделей привели к значительным успехам в сфере обработки естественного языка (Natural Language Processing, NLP), породив такие высокоэффективные модели, как BERT, RoBERTa, XLNet, ALBERT, T5 и многие другие. Эти методы, имеющие различную архитектуру, тем не менее, объединяет идея использования больших объемов неразмеченных текстовых данных для создания общей модели понимания естественного языка, которая затем дообучается и тонко настраивается для решения конкретных прикладных задач, вроде анализа тональности или построения вопросно-ответных систем.
От эвристики до машинного обучения: поисковые подсказки в Ситимобил
8 min

Всем привет! Меня зовут Михаил Дьячков, и в Ситимобил я занимаюсь машинным обучением. Сегодня я расскажу вам о нашем новом алгоритме формирования поисковых подсказок конечных пунктов назначения. Вы узнаете, как на первый взгляд довольно простая задача превратилась в интересный сценарий, с помощью которого, мы надеемся, у нас получилось немного облегчить жизнь пользователей. Мы продолжаем внимательно следить за работой нового алгоритма и впоследствии будем его «подкручивать», чтобы поддерживать качество ранжирования на высоком уровне. Для всех пользователей мы запустим алгоритм в ближайшие несколько недель, но уже готовы рассказать о долгом пути, который мы прошли от эвристики до алгоритма машинного обучения и выкатки его в эксплуатацию.
Временные сверточные сети – революция в мире временных рядов
5 min
Translation
Перевод статьи подготовлен в преддверии старта курса «Deep Learning. Basic».

В этой статье мы поговорим о последних инновационных решениях на основе TCN. Для начала на примере детектора движения рассмотрим архитектуру временных сверточных сетей (Temporal Convolutional Network) и их преимущества перед традиционными подходами, такими как сверточные нейронные сети (CNN) и рекуррентные нейронные сети (RNN). Затем поговорим о последних примерах применения TCN, включая улучшение прогнозирования трафика, локализатор и детектор звука и вероятностное прогнозирование.
В этой статье мы поговорим о последних инновационных решениях на основе TCN. Для начала на примере детектора движения рассмотрим архитектуру временных сверточных сетей (Temporal Convolutional Network) и их преимущества перед традиционными подходами, такими как сверточные нейронные сети (CNN) и рекуррентные нейронные сети (RNN). Затем поговорим о последних примерах применения TCN, включая улучшение прогнозирования трафика, локализатор и детектор звука и вероятностное прогнозирование.
Выработка уникальных идей для Data Science-проектов за 5 шагов
8 min
Translation
Вероятно, самое сложное в любом Data Science-проекте — это придумать оригинальную, но реализуемую идею. Специалист, который ищет такую идею, легко может попасться в «ловушку наборов данных». Он тратит многие часы, просматривая существующие наборы данных и пытаясь выйти на новые интересные идеи. Но у такого подхода есть одна проблема. Дело в том, что тот, кто смотрит лишь на существующие наборы данных (c Kaggle, Google Datasets, FiveThirtyEight), ограничивает свою креативность, видя лишь небольшой набор задач, на которые ориентированы изучаемые им наборы данных.
Иногда мне нравится изучать интересующие меня наборы данных. Если я построю удачную модель для данных, взятых с Kaggle, для которых уже создано бесчисленное множество моделей, практической ценности в этом не будет, но это, по крайней мере, позволит мне научиться чему-то новому. Но дата-сайентисты — это люди, которые стремятся создавать что-то новое, уникальное, что-то такое, что способно принести миру реальную пользу.

Как вырабатывать новые идеи? Для того чтобы найти ответ на этот вопрос, я совместила собственный опыт и результаты исследований креативности. Это привело к тому, что мне удалось сформировать 5 вопросов, ответы на которые помогают находить новые идеи. Тут же я приведу и примеры идей, найденных благодаря предложенной мной методике. В процессе поиска ответов на представленные здесь вопросы вы пройдёте по пути создания новых идей и сможете задействовать свои креативные возможности на полную мощность. В результате у вас будут новые уникальные идеи, которые вы сможете реализовать в ваших Data Science-проектах.
Иногда мне нравится изучать интересующие меня наборы данных. Если я построю удачную модель для данных, взятых с Kaggle, для которых уже создано бесчисленное множество моделей, практической ценности в этом не будет, но это, по крайней мере, позволит мне научиться чему-то новому. Но дата-сайентисты — это люди, которые стремятся создавать что-то новое, уникальное, что-то такое, что способно принести миру реальную пользу.
Как вырабатывать новые идеи? Для того чтобы найти ответ на этот вопрос, я совместила собственный опыт и результаты исследований креативности. Это привело к тому, что мне удалось сформировать 5 вопросов, ответы на которые помогают находить новые идеи. Тут же я приведу и примеры идей, найденных благодаря предложенной мной методике. В процессе поиска ответов на представленные здесь вопросы вы пройдёте по пути создания новых идей и сможете задействовать свои креативные возможности на полную мощность. В результате у вас будут новые уникальные идеи, которые вы сможете реализовать в ваших Data Science-проектах.
10 вещей, которые вы могли не знать о scikit-learn
7 min
Translation
В этой переведенной статье ее автор, Rebecca Vickery, делится интересными функциями scikit-learn. Оригинал опубликован в блоге towardsdatascience.com.

Фото с сайта Unsplash. Автор: Sasha • Stories
Scikit-learn является одной из наиболее широко используемых библиотек Python для машинного обучения. Ее простой стандартный интерфейс позволяет производить препроцессинг данных, а также заниматься обучением, оптимизацией и оценкой модели.
Этот проект, разработанный Дэвидом Курнапо (David Cournapeau), появился на свет в рамках программы Google Summer of Code и был выпущен в 2010 году. С момента своего создания библиотека превратилась в инфраструктуру с широкими возможностями для создания моделей машинного обучения. Новые функции позволяют решать еще больше задач и повышают удобство использования. В этой статье я расскажу о десяти самых интересных функциях, о которых вы могли не знать.
Фото с сайта Unsplash. Автор: Sasha • Stories
Scikit-learn является одной из наиболее широко используемых библиотек Python для машинного обучения. Ее простой стандартный интерфейс позволяет производить препроцессинг данных, а также заниматься обучением, оптимизацией и оценкой модели.
Этот проект, разработанный Дэвидом Курнапо (David Cournapeau), появился на свет в рамках программы Google Summer of Code и был выпущен в 2010 году. С момента своего создания библиотека превратилась в инфраструктуру с широкими возможностями для создания моделей машинного обучения. Новые функции позволяют решать еще больше задач и повышают удобство использования. В этой статье я расскажу о десяти самых интересных функциях, о которых вы могли не знать.
5 алгоритмов регрессии в машинном обучении, о которых вам следует знать
7 min
Translation

Источник: Vecteezy
Да, линейная регрессия не единственная
Быстренько назовите пять алгоритмов машинного обучения.
Вряд ли вы назовете много алгоритмов регрессии. В конце концов, единственным широко распространенным алгоритмом регрессии является линейная регрессия, главным образом из-за ее простоты. Однако линейная регрессия часто неприменима к реальным данным из-за слишком ограниченных возможностей и ограниченной свободы маневра. Ее часто используют только в качестве базовой модели для оценки и сравнения с новыми подходами в исследованиях.
Команда Mail.ru Cloud Solutions перевела статью, автор которой описывает 5 алгоритмов регрессии. Их стоит иметь в своем наборе инструментов наряду с популярными алгоритмами классификации, такими как SVM, дерево решений и нейронные сети.
8 ML/AI-проектов, которые украсят ваше портфолио
6 min
Translation
Автор материала, перевод которого мы сегодня публикуем, предлагает вниманию читателей 8 идей проектов в сферах машинного обучения и искусственного интеллекта. Описание идей сопровождается ссылками на дополнительные материалы. Реализации этих идей способны украсить портфолио проектов профильного специалиста.

Обзор Gartner MQ 2020: Платформы машинного обучения и искусственного интеллекта
7 min
Невозможно объяснить причину, зачем я это прочел. Просто было время и было интересно, как устроен рынок. А это уже полноценный рынок по Gartner с 2018го года. С 2014-2016 называлось продвинутой аналитикой (корни в BI), в 2017 – Data Science (не знаю, как перевести это на русский). Кому интересны передвижения вендоров по квадрату – можно здесь посмотреть. А я буду говорить про квадрат 2020го года, тем более, что изменения там с 2019го минимальные: выехал SAP и Altair купил Datawatch.
Это не систематизированный разбор и не таблица. Индивидуальный взгляд, еще с точки зрения геофизика. Но мне всегда любопытно читать Gartner MQ, они прекрасно некоторые моменты формулируют. Так что тут вещи, на которые я обратил внимание и в техническом плане, и в рыночном, и в философском.
Это не для людей, которые глубоко в теме ML, но для людей, которые интересуются тем, что вообще происходит на рынке.
Сам DSML рынок логично гнездится между BI и Cloud AI developer services.
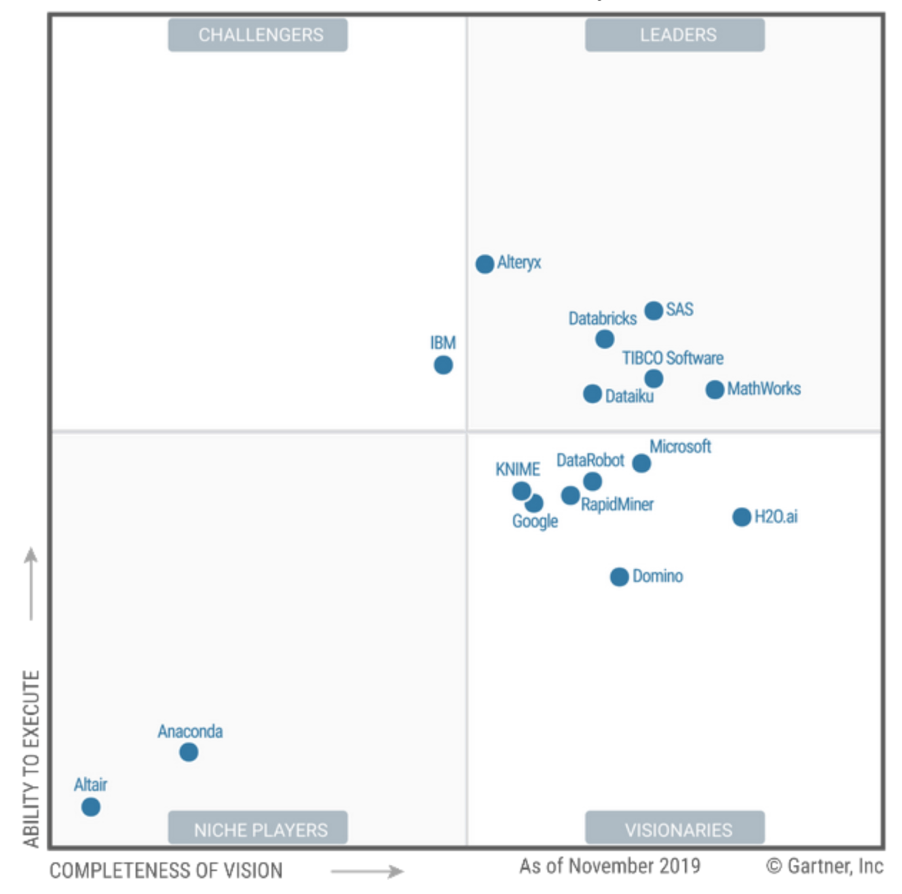
Это не систематизированный разбор и не таблица. Индивидуальный взгляд, еще с точки зрения геофизика. Но мне всегда любопытно читать Gartner MQ, они прекрасно некоторые моменты формулируют. Так что тут вещи, на которые я обратил внимание и в техническом плане, и в рыночном, и в философском.
Это не для людей, которые глубоко в теме ML, но для людей, которые интересуются тем, что вообще происходит на рынке.
Сам DSML рынок логично гнездится между BI и Cloud AI developer services.
Уроки волшебства для кота, дейтинг для беременных и астрология
10 min
Data Scientists узнают, что интересует людей и на что они тратят деньги
В ходе исследований различных аудиторий Data Scientists наблюдают как закономерные, так и удивительные факты, которые ярко характеризуют социум вокруг нас. В этой статье я расскажу о тех курьёзах и необычных случаях, которые заметила при выполнении задач, связанных с аудиторным анализом, исследованием интересов пользователей Интернета и покупательского поведения различных социальных групп.
Какие социологические особенности удалось выяснить благодаря применению моделей машинного обучения? Что мы знаем о покупателях?

{kind=link}
Нейросетевой визуальный поиск
10 min
История знает много примеров преждевременных открытий и изобретений. Хочу рассказать об одном из них.
Речь пойдет о визуальном поисковике, получившим первые западные венчурные инвестиции в области ИТ в России, построенном на основе активных семантических нейронных сетях. Под катом мы расскажем об его основных принципах работы и архитектуре.
Речь пойдет о визуальном поисковике, получившим первые западные венчурные инвестиции в области ИТ в России, построенном на основе активных семантических нейронных сетях. Под катом мы расскажем об его основных принципах работы и архитектуре.
«Другой» менеджмент или почему бывает сложно общаться с людьми на работе
9 min
Недавно сменил очередное место работы, я программист, Team Lead, PM, BA, Data Analytic, HR, QA, CTO, продюсер и психолог (последнее и по образованию, и по факту).
Не так давно я очень заинтересовался конфликтами в рабочем коллективе, а точнее – от куда они берутся и что с ними можно делать, чтобы они не мешали работе, а или даже наоборот – помогали. Больше всего бросилось в глаза то, что люди никогда не говорят о том, что они действительно хотят сказать, даже когда переходят на повышенные тона.
Приведу пример. Если вы как-то связаны с it, то, наверное, вам удавалось слышать такие фразы как:
- Я уже 3 года, тут работаю, а он только пришёл
- Front End ничего не смыслит в Back End
- Менеджеры надоели со своими бесполезными митингами
- Дизайнеру это просто вправо подвинуть, а нам переделывать неделю
И вроде бы эти фразы производит впечатление лаконично и логично аргументированной позиции. Но мне кажется люди совсем не то хотят сказать на самом деле. По моему, сугубо личному, опыту все эти фразы можно заменить на «заметьте меня, я тоже важен», а иногда и «я важнее других».
Книга «Обработка естественного языка в действии»
16 min
 Привет, Хаброжители! Мы издали практическое руководство по обработке и генерации текстов на естественном языке. Книга снабжена всеми инструментами и методиками, необходимыми для создания прикладных NLP-систем с целью обеспечения работы виртуального помощника (чат-бота), спам-фильтра, программы — модератора форума, анализатора тональностей, программы построения баз знаний, интеллектуального анализатора текста на естественном языке или практически любого другого NLP-приложения, какое только можно себе представить.
Привет, Хаброжители! Мы издали практическое руководство по обработке и генерации текстов на естественном языке. Книга снабжена всеми инструментами и методиками, необходимыми для создания прикладных NLP-систем с целью обеспечения работы виртуального помощника (чат-бота), спам-фильтра, программы — модератора форума, анализатора тональностей, программы построения баз знаний, интеллектуального анализатора текста на естественном языке или практически любого другого NLP-приложения, какое только можно себе представить.Книга ориентирована на Python-разработчиков среднего и высокого уровня. Значительная часть книги будет полезна и тем читателям, которые уже умеют проектировать и разрабатывать сложные системы, поскольку в ней содержатся многочисленные примеры рекомендуемых решений и раскрываются возможности самых современных алгоритмов NLP. Хотя знание объектно-ориентированного программирования на Python может помочь создавать лучшие системы, для использования приводимой в этой книге информации оно не обязательно.
Sktime: унифицированная библиотека Python для машинного обучения и работы с временными рядами
7 min
Translation
Всем привет. В преддверии старта базового и продвинутого курсов «Математика для Data Science», мы подготовили перевод еще одного интересного материала.

Почему? Существующие инструменты плохо подходят для решения задач, связанных с временными рядами и эти инструменты сложно интегрировать друг с другом. Методы пакета scikit-learn предполагают, что данные структурированы в табличном формате и каждый столбец состоит из независимых и одинаково распределенных случайных величин – предположений, которые не имеют ничего общего с данными временных рядов. Пакеты, в которых есть модули для машинного обучения и работы с временными рядами, такие как statsmodels, не особо хорошо дружат между собой. Более того, множество важных операций с временными рядами, такие как разбиение данных на обучающий и тестовый наборы по временным промежуткам, в существующих пакетах недоступны.
Для решения подобных задач и была создана sktime.
Решение задач из области data science на Python – это непросто
Почему? Существующие инструменты плохо подходят для решения задач, связанных с временными рядами и эти инструменты сложно интегрировать друг с другом. Методы пакета scikit-learn предполагают, что данные структурированы в табличном формате и каждый столбец состоит из независимых и одинаково распределенных случайных величин – предположений, которые не имеют ничего общего с данными временных рядов. Пакеты, в которых есть модули для машинного обучения и работы с временными рядами, такие как statsmodels, не особо хорошо дружат между собой. Более того, множество важных операций с временными рядами, такие как разбиение данных на обучающий и тестовый наборы по временным промежуткам, в существующих пакетах недоступны.
Для решения подобных задач и была создана sktime.
Наш опыт работы с DeepPavlov: голосовой помощник за 20 дней и приём 5000 звонков на горячей линии
Hard
5 min
Tutorial
Когда объявили режим самоизоляции, на горячую линию по коронавирусу в Татарстане поступало множество вопросов от жителей. Чтобы разгрузить операторов коллцентра, мы в Центре Цифровой Трансформации республики вместе с уполномоченным по ИИ в Татарстане разработали голосового помощника, который отвечал на несложные вопросы.
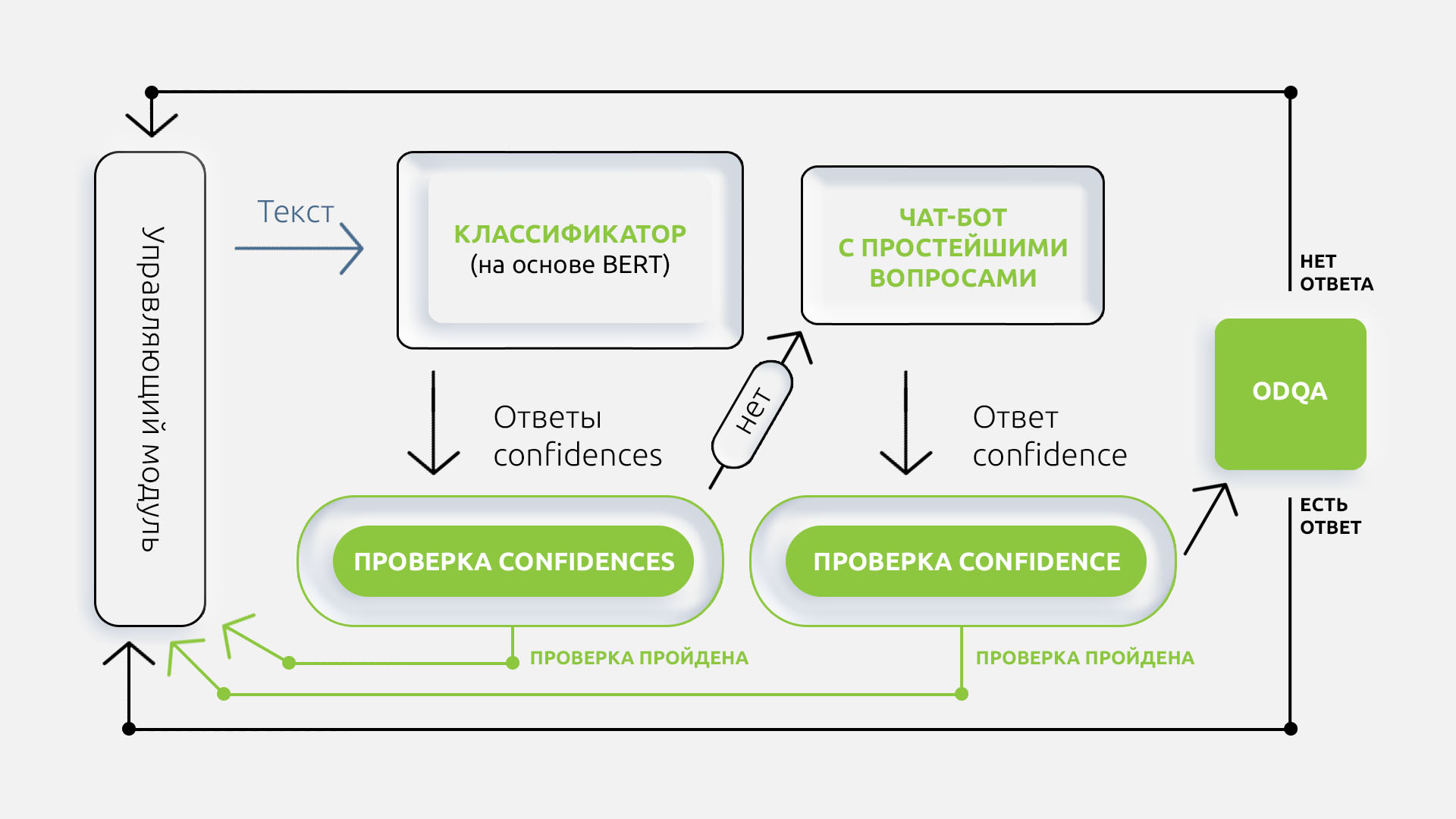
Для приема звонков мы использовали платформу Voximplant, а для распознавания вопросов и ответов — DeepPavlov. Голосового помощника получилось запустить за две с половиной недели, и он помог обработать 5000 звонков. У нас получилось выкатить продукт, который помогал жителям Татарстана получать достоверную информацию от властей, да и просто выходить на улицу. Ниже расскажем, как мы это делали.
Для приема звонков мы использовали платформу Voximplant, а для распознавания вопросов и ответов — DeepPavlov. Голосового помощника получилось запустить за две с половиной недели, и он помог обработать 5000 звонков. У нас получилось выкатить продукт, который помогал жителям Татарстана получать достоверную информацию от властей, да и просто выходить на улицу. Ниже расскажем, как мы это делали.
Как объединить 10 BERT-ов для задач общего понимания текста?
10 min
Всем привет! В этом посте я расскажу о проекте, который выполнил совместно с командой Google Brain во время исследовательской стажировки в Цюрихе. Мы работали над моделью обработки естественного языка, которая решает задачи на общее понимание текста (задачи из набора GLUE: General Language Understanding Evaluation).
BERT-подобные модели мы комбинировали с помощью маршрутизирующих сетей и добились того, что при увеличении мощности скорость вывода почти не изменилась. Финальная модель объединяет 10 BERTlarge моделей и имеет более 3,4 миллиарда параметров. Подробности под катом!
