Тестирование в Java. JUnit
8 min
Tutorial

Сегодня все большую популярность приобретает test-driven development(TDD), техника разработки ПО, при которой сначала пишется тест на определенный функционал, а затем пишется реализация этого функционала. На практике все, конечно же, не настолько идеально, но в результате код не только написан и протестирован, но тесты как бы неявно задают требования к функционалу, а также показывают пример использования этого функционала.
Итак, техника довольно понятна, но встает вопрос, что использовать для написания этих самых тестов? В этой и других статьях я хотел бы поделиться своим опытом в использовании различных инструментов и техник для тестирования кода в Java.
Ну и начну с, пожалуй, самого известного, а потому и самого используемого фреймворка для тестирования — JUnit. Используется он в двух вариантах JUnit 3 и JUnit 4. Рассмотрю обе версии, так как в старых проектах до сих пор используется 3-я, которая поддерживает Java 1.4.
Я не претендую на автора каких-либо оригинальных идей, и возможно многим все, о чем будет рассказано в статье, знакомо. Но если вам все еще интересно, то добро пожаловать под кат.

 За последнее время появилось
За последнее время появилось 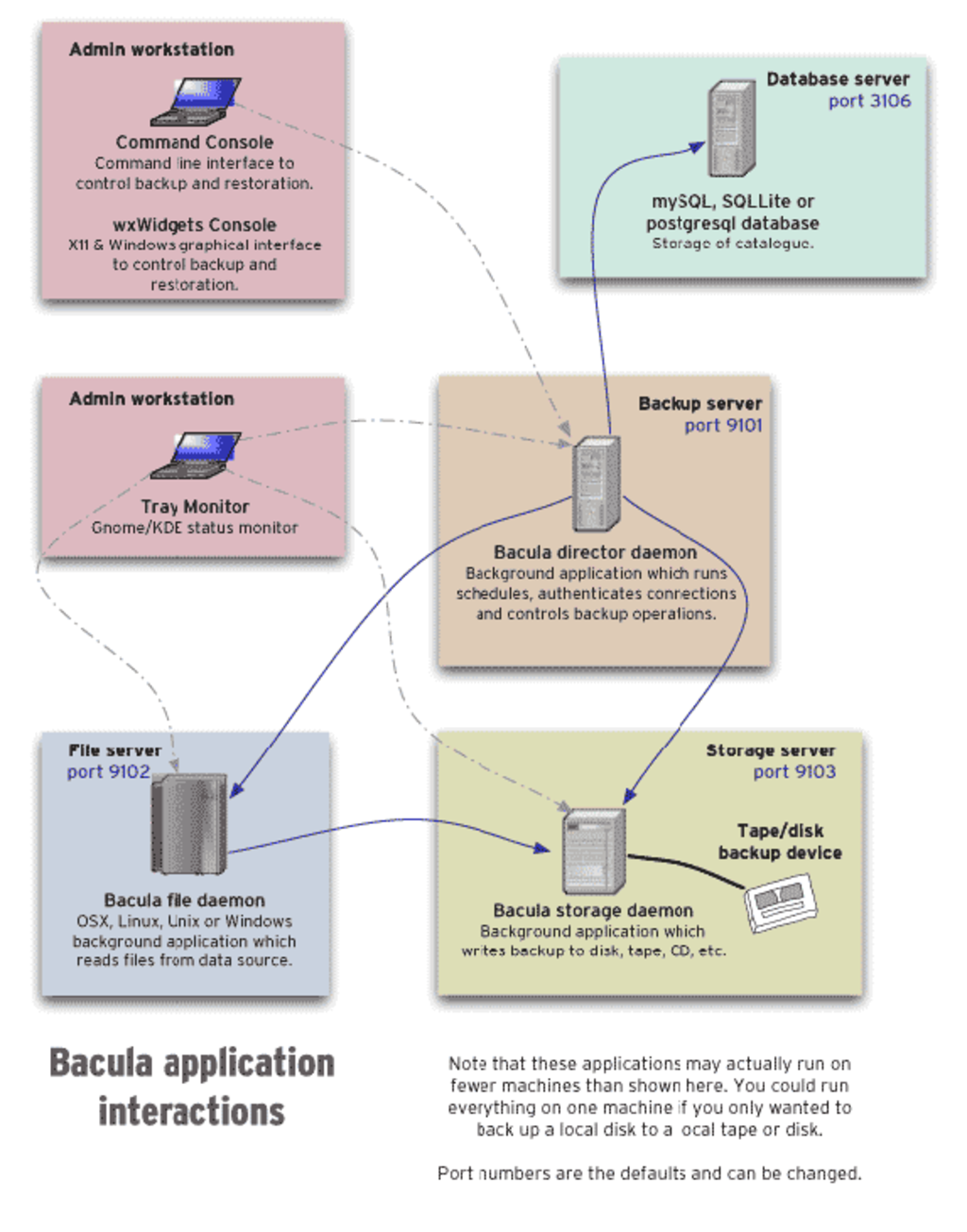
 В случае если вы разделяете данные по нескольким физическим базам данных,
В случае если вы разделяете данные по нескольким физическим базам данных,