США, Техас, Остин, клуб Continental
Воскресенье, 5 января 1987 г.
— Спасибо за приглашение, мистер Ломуто. Скоро я возвращаюсь в Англию, так что это было очень вовремя.
— Спасибо, что согласились со мной встретиться, мистер… сэр… Чарльз… Энтони Ричард… Хоар. Это большая честь для меня. Я даже не знаю, как к вам обращаться. У вас есть рыцарский титул?
— Зовите меня Тони, и, если вы позволите, я буду называть вас Нико.
На первый взгляд — обычная картина: два человека наслаждаются виски. Однако внимательному наблюдателю открываются интригующие подробности. Прежде всего — напряжение, которое можно было резать ножом.
Одетый в безупречно подогнанный костюм-тройку с нарочитой небрежностью, на какую способен только англичанин, Тони Хоар был таким же воплощением Британии, как и чашка чая. Смиренное выражение лица, с которым он попивал из своего стакана, без всяких слов выражало его мнение в споре между бурбоном и скотчем. Сидевший напротив Нико Ломуто представлял полную ему противоположность: одетый в джинсы программист, мешавший виски с колой (что для Тони было настолько возмутительно, что он сразу решил подчёркнуто это игнорировать — как резкий запах пота или оскорбительную татуировку), в состоянии некого расслабленного трепета перед гигантом информатики, с которым он только что познакомился лично.
— Послушайте, Тони, — сказал Нико после того, как иссякли темы для обычной лёгкой беседы. — По поводу того алгоритма разбиения. Я даже не собирался его публиковать...
— Что? Ах да, алгоритм разбиения, — Тони поднял брови в притворном изумлении, словно забыв, что каждая статья или книга о быстрой сортировке за последние пять лет упоминала их имена вместе. Очевидно, что именно это связывало этих двух людей и было причиной этой встречи, но Тони, как безупречный джентльмен, мог бы часами говорить о погоде, если бы собеседник не упомянул о стоящем в комнате розовом слоне.







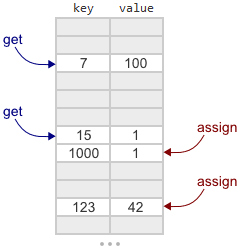
 Коллекция в Python — программный объект (переменная-контейнер), хранящая набор значений одного или различных типов, позволяющий обращаться к этим значениям, а также применять специальные функции и методы, зависящие от типа коллекции.
Коллекция в Python — программный объект (переменная-контейнер), хранящая набор значений одного или различных типов, позволяющий обращаться к этим значениям, а также применять специальные функции и методы, зависящие от типа коллекции.