В последнее время в специализированной прессе все чаще появляется «загадочная» аббревиатура ILM – Information Lifecycle Management. Ведущие разработчики один за другим предлагают решения для той или иной части ILM, красиво расписывая общую схему хранения данных в реорганизованном соответствующим образом датацентре. Однако ясного понимания, что же такое ILM, у российских заказчиков, на наш взгляд, пока не сложилось.
Первое, что стоит отметить: ILM – не панацея, не технология, не решение и не руководство к действию. Это концепция, отражающая современный взгляд на корпоративные данные; набор практик управления, нацеленных на достижение оптимального соотношения ценности информации для бизнеса и стоимости инфраструктуры её хранения.
ILM, согласно SNIA (Storage Networking Industry Association,
www.snia.org), это политики, процессы, практики, сервисы и инструменты, используемые для того, чтобы соотнести ценность информации с точки зрения бизнеса с наиболее подходящей и эффективной по стоимости инфраструктурой, начиная с момента создания информации и заканчивая ее размещением. Информация сопоставляется с бизнес-требованиями через политики управления и уровни предоставления сервиса, связанные с приложениями, данными и метаданными.
Говоря проще, это концепция автоматического размещения данных в инфраструктуре датацентра на основании требований бизнеса к параметрам защищенности, доступности информации и с учетом ее ценности для бизнеса, актуальности и минимизации расходов на хранение. Какие же проблемы хранения помогает решить ILM?
Не захлебнуться в океане данных
Ни для кого не секрет, что объем корпоративной информации с каждым годом увеличивается, и очень серьезно. В соответствии с отчетами IDC рост объемов хранимых и обрабатываемых данных составляет более 70% в год. В среднестатистической современной компании три тысячи сотрудников ежедневно передают по электронной почте терабайт данных. Всего в мире, по подсчётам Gartner, в 2005 году отправлялось 36 миллиардов электронных сообщений в день — в три раза больше, чем в 2001-м. В некоторых специфичных отраслях, например в медицине, наблюдается экспоненциальный рост информационных объёмов.
Ситуация осложняется требованиями нормативных актов и внутрикорпоративныхстандартов, предписывающих длительное хранение некоторых видов информации — иногда в течение 5--10 лет. А это значит, что компания, имеющая корпоративные данные скромного объема в 1 Тбайт и показывающая рост этих объёмов 60% в год (не самый большой по современным меркам), через 10 лет будет хранить уже 110 Тбайт информации. Увеличение более чем в 100 раз!
Проблема взрывного роста объемов данных тесно связана с другой проблемой: постоянно усложняются процессы управления распределенной инфраструктурой датацентров. Современный центр обработки данных состоит из тысяч взаимодействующих компонентов – серверов, элементов систем хранения (логических единиц, дисков, контроллеров, управляющих серверов, ленточных накопителей и т. д.), элементов сетей хранения и локальных сетей (маршрутизаторов, хост-контроллеров, адаптеров и пр.). Для управления сложной инфраструктурой применяются специальные инструменты, причём для каждого вида инфраструктурных элементов — свои. И чем больше в датацентре разнородных компонентов, тем больше инструментов управления вы вынуждены использовать. Что ещё больше увеличивает сложность системы.
Кроме того, использование специализированных инструментов управления инфраструктурой не решает основной задачи – управлять лавинообразно растущим потоком данных. Компании продолжают хранить информацию в дорогих высокопроизводительных системах и, несмотря на снижение стоимости оборудования, с каждым годом расходуют всё больше средств на её хранение. Процесс резервного копирования становится всё сложнее и требует больше и больше времени. При этом существующие инструменты управления не автоматизируют в достаточной степени процессы размещения информации – администраторы фактически вручную выделяют место для ее хранения, задают привязку к необходимым серверам, создают расписание резервного копирования, определяют источники и места назначения.
Сложившуюся ситуацию в области хранения данных можно охарактеризовать следующим образом:
объем данных катастрофически растет, а имеющиеся инструменты управления не в силах с этим справиться.
Нужны ли бизнесу все сохраняемые в системах данные?
Возвращаясь к примеру компании, за 10 лет увеличившей объём корпоративной информации в 100 раз, зададимся вопросом: так ли необходимы её бизнесу эти 110 Тбайт данных, размещенных в оперативных хранилищах?
Очевидно, что нет. С течением времени меняется как ценность данных, так и требования к их доступности и защищенности. Так, ценность финансовой транзакции максимальна в течение первого месяца и впоследствии неуклонно снижается. Кроме того, финансовая запись в ERP-системе компании и, скажем, личное письмо сотрудника имеют разную ценность для бизнеса уже в момент создания.
Между тем в оперативных высокопроизводительных хранилищах датацентра располагаются все данные, включая устаревшие и ненужные, в то время как храниться там должны только те, к которым предъявляются высокие требования доступности.
Анализ, проведенный Enterprise Storage Group, показывает, каким образом ценность информации для бизнеса изменяется с течением времени в зависимости от ее типа.
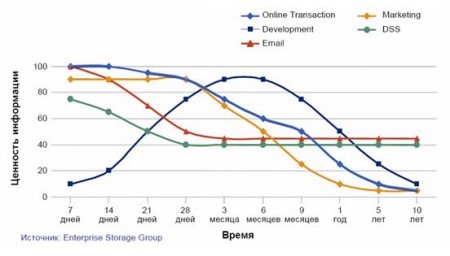
Мы можем сделать важный вывод:
разные классы информации имеют разную ценность для бизнеса, и эта ценность меняется с течением времени.
Следующее важное свойство корпоративных данных – их состояние. Создаваемые данные сохраняются в датацентре для последующей обработки и затем в зависимости от решаемых бизнесом задач изменяются. Пока данные изменяются, они находятся в активном состоянии и называются оперативными. Но с течением времени наступает момент, когда данные «закрепляются» и более изменениям не подвергаются. Они могут использоваться для генерации новых документов, сводных отчетов и т. п. Такие данные называют ссылочными. Естественный способ хранения ссылочных данных – архив.
В современных датацентрах обычно оперативные и ссылочные данные размещаются вместе, в одних и тех же хранилищах, что не только увеличивает стоимость хранения, но и создает трудности с соблюдением нормативных актов, регламентирующих хранение определенных видов информации.
Наконец, есть еще одно состояние – устаревшие данные, которые нигде более не используются, а срок их хранения, регламентируемый нормативными актами, истек. Такие данные больше не нужны бизнесу, их ценность нулевая, и они могут быть удалены. В настоящее время устаревшие данные отслеживаются практически вручную, их удаление из системы представляет собой кошмар для администратора, а хранение – пустую трату денег.
Вперед и вверх!
Описывая текущую ситуацию с хранением данных, мы намеренно не акцентировали внимания на различии между данными и информацией. Точно так же эти различия не учитываются в сложившейся сегодня практике организации процессов и инфраструктуры хранения. Однако именно этот аспект – один из важнейших в концепции ILM:
данные ≠ информация
Данные – это просто набор байтов, способ отражения бизнес-информации в инфраструктуре хранения. С такой точки зрения все они представляют одинаковую ценность, поскольку их семантика не определена, а значение здесь имеют такие параметры, как надежность хранения, защищенность и доступность. Именно этими характеристиками оперируют современные системы хранения данных и инструменты управления инфраструктурой.
Информация – это данные, представляющие определенный смысл для бизнеса. Аналогичные по структуре данные, одинаково размещенные в системе хранения, могут иметь совершенно разный смысл и, следовательно, разную ценность для компании. Например, личное письмо сотрудника, посланное по электронной почте, и письмо того же сотрудника, содержащее конфиденциальные сведения о клиенте.
ILM предлагает уйти от управления данными и сфокусироваться на управлении информацией. Для этого необходимо в первую очередь изменить подход к ее хранению. В рамках ILM предлагается классифицировать бизнес-информацию компании, прежде чем она попадет в инфраструктуру хранения. Классификация – это необходимый для эффективного управления жизненным циклом информации процесс, обеспечивающий хранимые данные адекватной семантикой.
Для этого процесса вводятся понятия целевых показателей уровня сервиса (Service Level Objectives — SLO) и «политик» (Policies), на основе которых будет осуществляться управление хранением информации. SLO определяет, какие показатели ключевых характеристик (надежности, доступности и др.) должны обеспечиваться инфраструктурой хранения для данного класса информации. «Политики» определяют необходимые действия с конкретными классами информации при возникновении определенных условий (например, при окончании срока жизни информации). Основой для формирования SLO и политик являются бизнес-требования и бизнес-процессы компании, а также различные нормативные акты.
Таким образом, подход к хранению данных в датацентре становится информационно-центричным.
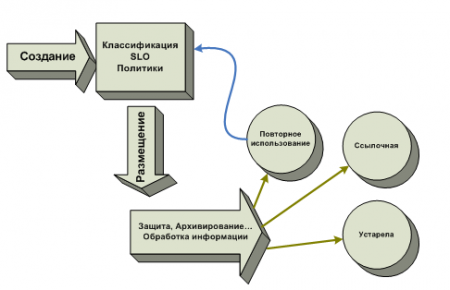
Создаваемая информация классифицируется, с ней связываются определенные SLO, на основании которых интегрированный в инфраструктуру механизм управления размещает эту информацию согласно заданным политикам. Это значит, что информация, требующая высокой доступности, попадет в высокопроизводительные системы хранения, а та, что не является критически важной для бизнеса, разместится в недорогих хранилищах.
При этом механизмы работы приложений с данными не меняются, но инструменты управления постоянно отслеживают ценность информации, ее состояние и перемещают ее в адекватные системы хранения согласно политикам и SLO. На определенном этапе жизненного цикла информация может стать ссылочной, устареть или повторно использоваться. Тогда механизм управления в первом случае передаст ее в архив, во втором – просто удалит, а в третьем – заново классифицирует и свяжет с другим SLO.
Таким образом, датацентр, построенный согласно ILM, обеспечивает следующие основные преимущества:
- снижение стоимости хранения информации (за счет своевременного переноса данных в недорогие системы хранения и уничтожения устаревшей информации);
строгое соблюдение нормативных актов, регламентирующих хранение данных, путем автоматического применения политик;
достижение соответствия характеристик хранения (надежности, защищенности, доступности и др.) различным классам информации;
исключение дублирования информации (за счет управления ссылочными данными).
И при этом информация всегда предоставляется в нужном месте, в нужное время и по оптимальной цене.


