
Сводные таблицы хорошо известны всем аналитикам по Excel. Это прекрасный инструмент, который помогает быстро получить различную информацию по массиву данных. Рассмотрим реализацию и тонкости сводных таблиц в Pandas.

java / open source
Сводные таблицы хорошо известны всем аналитикам по Excel. Это прекрасный инструмент, который помогает быстро получить различную информацию по массиву данных. Рассмотрим реализацию и тонкости сводных таблиц в Pandas.

Для сложных информационных систем бывает крайне сложно принять компромиссные решения с учетом ограниченных ресурсов. Одним из возможных способов решения является подход Architecture Description Log, который внедрен в крупных компаниях, таких как Google, Spotify и Microsoft. В этой статье мы рассмотрим основные положения ADL и обсудим, чем это может быть полезно для создания сбалансированной архитектуры в гибкой методологии разработки.

Представьте, в вашем проекте есть куча разбросанных по пространству логически связанных элементов, которые (о ужас!) могут свободно перемещаться по пространству. Задача - красиво и наглядно показать пользователю эти связи, чтобы упорядочить представление. В данной статье я покажу нашу реализацию.

На днях я наткнулся на одно любопытное видео.
Моей первой реакцией было Братан, хорош, давай, давай, вперёд! Контент в кайф, можно ещё? Вообще красавчик! Можно вот этого вот почаще? отрицание и усталость, потому что всё это я уже слышу на протяжении лет пяти с разной интенсивностью в зависимости от текущих объектов хайпа. В этом посте я попытаюсь разобраться, что из сказанного в видео является правдой.
Утверждения:
1. Закон Мура больше не выполняется из-за фундаментальных физических ограничений ⇒ масштабирование нейросетевых моделей по вычислительному бюджету невозможно.
2. Нейросетевые модели внедряются слишком медленно.
3. Ответы нейросетевых моделей неконтролируемы и неинтерпретируемы.
Дальше обсудим каждое из них.

ffmpeg делает реальную работу. 
Я backend разработчик с опытом около 3-х лет, пишу в основном на Golang. Проработал в нескольких крупных российских компаниях. Сейчас я параллельно со своей работой пытаюсь сделать удобный, дешевый VPN сервис с высокой пропускной способностью. В этой статье я хочу просто рассказать про жизненный цикл своего проекта. Возможно кому-то будет просто интересно почитать, а кто-то может почерпнуть что-то новое для себя.
В этой статье мы разберемся, как работает типичная защита от роботов, рассмотрим подходы к автоматическому парсингу сайтов с такой защитой, и разработаем свое решение для её обхода. В конце статьи будет ссылка на гитхаб.
Речь не идет о каком-либо виде "взлома" или о создании повышенной нагрузки на сайт. Мы будем автоматизировать то, что и так можно сделать вручную.

За последние месяцы сотни тысяч сотрудников потеряли работу в Google, Meta и других IT-гигантах. Некоторые, оставшись без дела, решают создать собственные компании. Или раскручивают свои пет-проекты. Что закладывает новый фундамент для будущего всей индустрии.

В этом номере самое интересное за январь начало февраля 2023. В том числе, конечно, о релизах

Привет ХАБР. Тема, которой посвящена эта статья с одной стороны важна, ведь в кибер-пространстве «неспокойно». Каждый день приходят новости, что ту или иную компанию взломали хакеры, получили дампы или зашифровали данные. Защищаться от кибер-угроз, выстраивая целую инфраструктуру из всевозможных средств защиты хорошо и нужно, но никогда не стоит забывать о разведке. В кибер-пространстве как в армии. Хорошо, когда на границах вырыты окопы, дежурит артиллерия и ПВО, но без разведки не понятно куда и чем противник будет атаковать. В цифровом мире базовая военная стратегия в целом не отличается. Разведка важна и нужна, чтобы быть готовыми и собирать данные, которые собирают злоумышленники о вас и вашей инфраструктуре. В этой статье разберем вопрос о том как создавалось направление кибер-разведки(OSINT open-source intelligence ) в компании.
С чего зародилась идея создания направления OSINT?
В наше время стал мейнстримом тренд на защиту персональных данных и всякой конфиденциалки в компании. Запрос на поиск источников утечек и их закрытия очевиден. Самое сложное расставить приоритеты или ответить на вопрос: "Что будем собственно искать?" Если открыть внутренние документы любой компании, то сведений, составляющих какую-либо из тайн (персональные, конфиденциальные, коммерческие) большое количество. Важно выбрать те, которые являются самыми важными для контроля и утечки которых реально можем находить и устранять.
Путем расстановки приоритетов и реальных возможностей мы выделили основные направления для OSINT:

В большинстве учетных систем, типа нашего СБИС, рано или поздно возникает проблема быстрого отображения реестра, в который по просьбам бизнес‑пользователей накручено несколько комбинируемых фильтров с очень редкой выборкой, ну никак не ложащихся в вашу красивую структуру базы данных и индексов базовой таблицы реестра — что‑нибудь типа "список продаж покупателям, чей день рождения выпадает на 29 февраля".
Универсального способа сделать «хорошо» тут нет, но я расскажу про модель запроса, которая позволит вам дать пользователю быстрый отклик, но при этом весьма эффективно с точки зрения PostgreSQL.
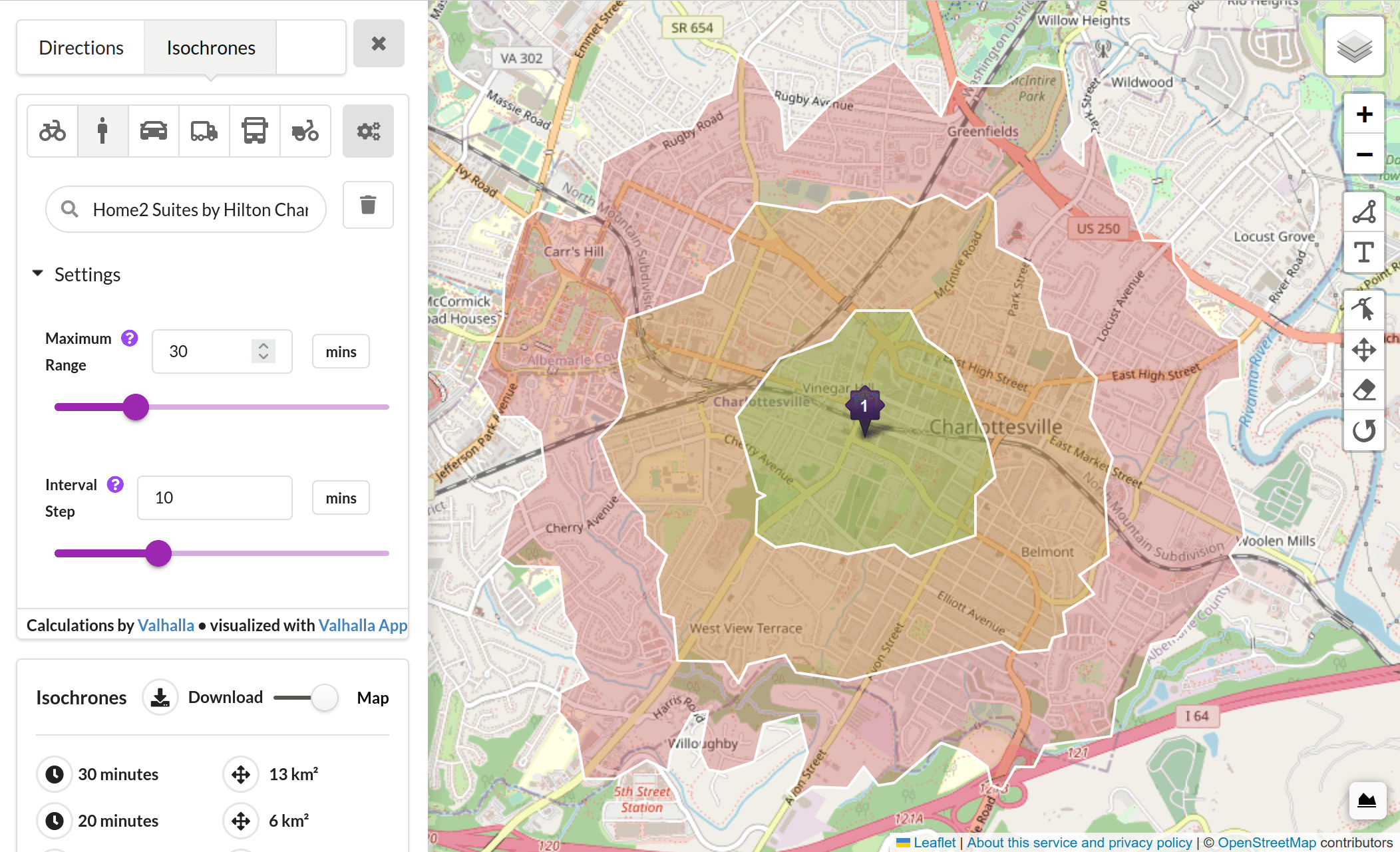

В рамках проекта Фото-Географического Атласа России (photogeomap.ru) мы собрали ряд фотографий различных ландшафтов страны. Многие из них сделаны в достаточно труднодоступных местах. Именно эту труднодоступность на качественном уровне мы и хотим оценить для каждой точки (фотографии).

Привет, Хабр! Меня зовут Сергей, я руководитель команды поиска в Ozon. Сегодня я расскажу об эволюции наших поисковых систем: как всё начиналось более 20 лет назад с обычных SQL-запросов, как мы осваивали Sphinx и Elasticsearch и как сейчас наш собственный поисковый движок O2 на базе Apache Lucene выдерживает нагрузку в десятки тысяч RPS в сезон распродаж. Исторические хроники восстанавливались по воспоминаниям современников и представлены для полноты картины. Новейшая история описана на основе собственного опыта, поэтому подробностей будет на порядок больше. Поехали!

Казалось бы, с документацией всё просто — пишешь, публикуешь, поддерживаешь актуальность. Например, вот у нас в Ozon есть пользовательские инструкции на docs.ozon.ru: выглядит просто как текст на сайтике, что ж необычного-то в его размещении и в целом в работе техписателей?
Если начать раскапывать, всплывёт ещё несколько вопросов:
• где хранить тексты и почему Confluence не подходит?
• как красиво оформить документацию с помощью статических генераторов сайтов
• зачем техписателям знать git и CI/CD?
• в какой момент пора искать разработчиков в команду и превращать документацию в платформу?
На связи Катя — руководитель отдела технических писателей в Ozon, и сегодня расскажу о платформе Docs Ozon изнутри.


Почти 4 года назад вашим покорным слугой была опубликована статья Увеличь это! Современное увеличение разрешения, которая набрала +376 хабролайков и 176 тысяч просмотров. Но прогресс на месте не стоит! Новые нейросетевые методы жгут! Их результаты прекрасны и великолепны. 1,5 года назад на хабре была неплохая статья Апскейл, который смог (+160), в которой были показаны плюсы новых алгоритмов.
Но всегда ли все прекрасно? Конечно нет!
Мой любимый пример фантастических способностей нейросетевых алгоритмов выше. В шарике отражается наша лаборатория. Бюст Зевса был взят в датасет, чтобы оценить работу нейросетей с полутенями, но результат «обработки полутеней» сильно превзошел ожидания. Во-первых, мудрые голубые глаза и покрасневшие губы! Во-вторых, Зевс теперь причесан! В-третьих, его борода стала короче и тоже аккуратно подстрижена! Наконец, Зевс теперь выглядит ощутимо моложе и… человечнее! О, жители Олимпа, согласитесь, это просто божественно!
Почему нам таки есть что сказать по теме? За последние годы мы создали 3 бенчмарка Video Super-Resolution под разные кейсы использования, которые на данный момент занимают первые 3 (из 14) места в соответствующем разделе на сайте paperswithcode.com.
Подобная деятельность безмерно актуальна, поскольку если 4 года назад на GitHub было меньше 200 репозиториев Super-Resolution, то сейчас их там больше 900 и разобраться в этом море исходников стало совсем непросто.
Естественно, при создании бенчмарков у нас было много чудных примеров. Более того, сейчас мы целенаправленно создаем датасет артефактов нейросетевых алгоритмов апскейла.
Кому интересно посмотреть, какие забавные косяки бывают у новых алгоритмов, а также как выглядят наилучшие результаты, которые даже меня, занимающегося темой 14+ лет, удивляют — добро пожаловать под кат!
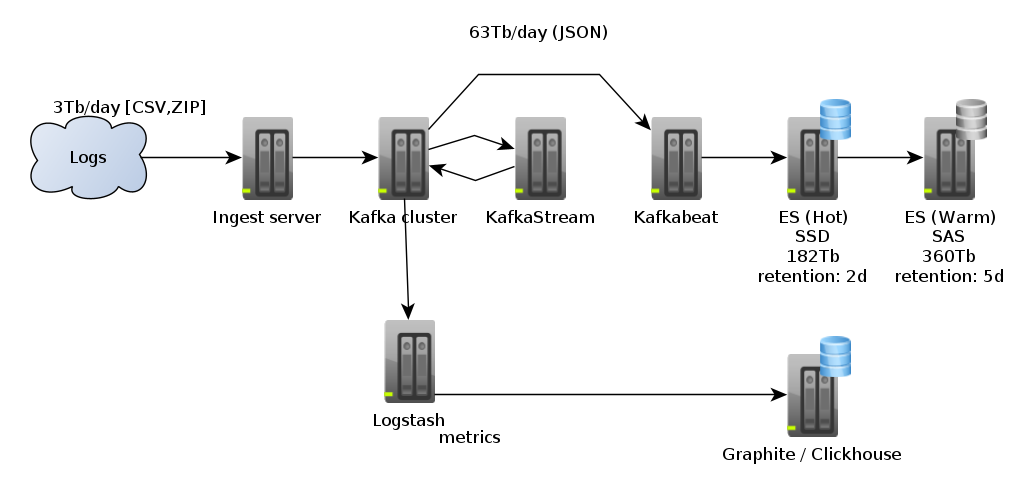
Черновик статьи был написан еще год назад, когда я работал на крупном международном проекте, но из-за разных событий прошлого года он остался неопубликованным.
На проекте в моем ведении находилось несколько on-premise кластеров в нескольких европейских датацентрах. «Мы» в этой статье — небольшая команда DataOps из 5 человек.
Было дело я читал на Хабре статью про «Кластер Elasticsearch на 200 ТБ+» и примерял написанное к нам, у нас такой кластер считался средним, самый маленький кластер под 0,1Ptb, а большой тогда был под 0,5Ptb. Потом была поставлена задача подготовить кластер к увеличению объемов входящих данных в 2-3 раза, а срок хранения в 2 раза, т. е. объем хранимых данных, если грубо экстраполировать, должен был стать в районе 2-3Ptb.
Хочу поделиться нашим опытом, может кому пригодиться.