
В давние времена разработки мобильных сайтов и приложений отладка была сложной задачей. Да, можно было заполучить устройство и быстренько проверить работу – но что было делать, если ты обнаруживал баг?
При отсутствии инструментов отладки приходилось полагаться на разные хаки. В целом они сводились к попыткам воспроизвести баг в десктопном браузере и затем отловить его при помощи Chrome Developer Tools или где-то ещё. К примеру, можно было уменьшить размер окна браузера или поменять user agent.
Грубо говоря, эти хаки не работали. Если ты правишь баг на десктопе, ты не уверен, что он исправлен на мобильном устройстве (МУ). Поэтому приходилось постоянно метаться между устройством и десктопом.
Теперь же у нас есть набор инструментов, позволяющих получать осмысленные данные прямо с МУ. Кроме того, можно использовать десктопные инструменты для отладки прямо на МУ.
В этой статье мы разберём несколько эмуляторов и симуляторов, которые позволяют быстро и легко тестировать сайты и приложения. Затем посмотрим на инструменты для удалённой отладки, позволяющие подключаться к МУ.
При отсутствии инструментов отладки приходилось полагаться на разные хаки. В целом они сводились к попыткам воспроизвести баг в десктопном браузере и затем отловить его при помощи Chrome Developer Tools или где-то ещё. К примеру, можно было уменьшить размер окна браузера или поменять user agent.
Грубо говоря, эти хаки не работали. Если ты правишь баг на десктопе, ты не уверен, что он исправлен на мобильном устройстве (МУ). Поэтому приходилось постоянно метаться между устройством и десктопом.
Теперь же у нас есть набор инструментов, позволяющих получать осмысленные данные прямо с МУ. Кроме того, можно использовать десктопные инструменты для отладки прямо на МУ.
В этой статье мы разберём несколько эмуляторов и симуляторов, которые позволяют быстро и легко тестировать сайты и приложения. Затем посмотрим на инструменты для удалённой отладки, позволяющие подключаться к МУ.
 Иногда так бывает: задачу можно решить чуть ли не арифметически, а на ум прежде всего приходят всякие интегралы Лебега и функции Бесселя. Вот начинаешь обучать нейронную сеть, потом добавляешь еще парочку скрытых слоев, экспериментируешь с количеством нейронов, функциями активации, потом вспоминаешь о SVM и Random Forest и начинаешь все сначала. И все же, несмотря на прямо таки изобилие занимательных статистических методов обучения,
Иногда так бывает: задачу можно решить чуть ли не арифметически, а на ум прежде всего приходят всякие интегралы Лебега и функции Бесселя. Вот начинаешь обучать нейронную сеть, потом добавляешь еще парочку скрытых слоев, экспериментируешь с количеством нейронов, функциями активации, потом вспоминаешь о SVM и Random Forest и начинаешь все сначала. И все же, несмотря на прямо таки изобилие занимательных статистических методов обучения, 


 Частенько читаю Хабр и заметил что в последнее время появились Дайджесты новостей по многим тематикам, таким как веб-разработка на php, разработка на Python, мобильные приложения, но не встретил ни одного подборки по популярному сейчас направлению, а именно анализу данных и big data.
Частенько читаю Хабр и заметил что в последнее время появились Дайджесты новостей по многим тематикам, таким как веб-разработка на php, разработка на Python, мобильные приложения, но не встретил ни одного подборки по популярному сейчас направлению, а именно анализу данных и big data.  Возможно, многие из читателей задавались вопросом, как людям удаётся собирать кубик Рубика 3×3
Возможно, многие из читателей задавались вопросом, как людям удаётся собирать кубик Рубика 3×3 
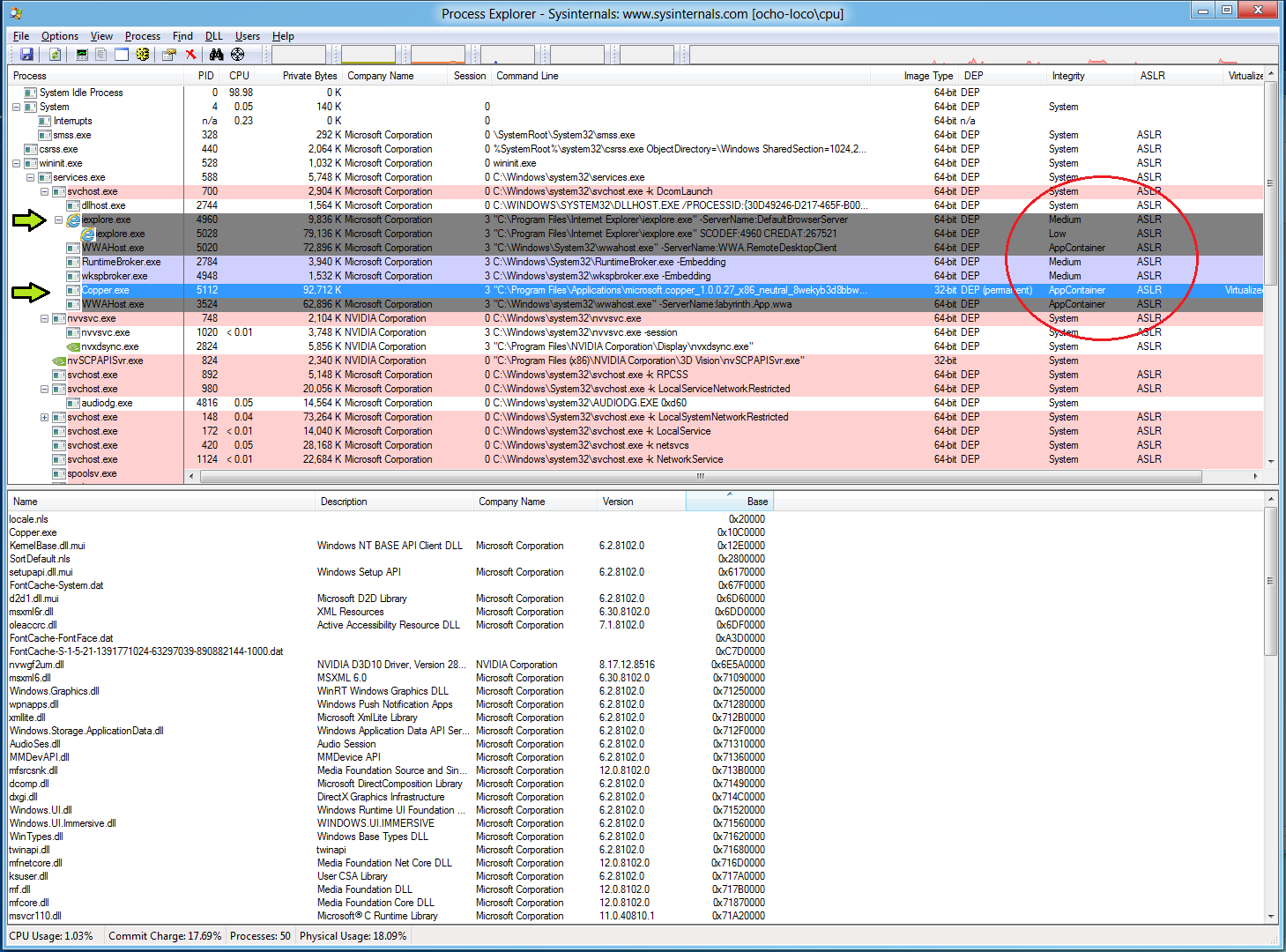
 Ещё в операционной системе Windows Vista компания Microsoft добавила средство создания «песочниц» — так называемые
Ещё в операционной системе Windows Vista компания Microsoft добавила средство создания «песочниц» — так называемые 

 В этой статье я расскажу об одном необычном подходе к генерации лабиринтов. Он основан на модели Амари́ нейронной активности коры головного мозга, являющейся непрерывным аналогом нейронных сетей. При определенных условиях она позволяет создавать красивые лабиринты очень сложной формы, подобные тому, что приведен на картинке.
В этой статье я расскажу об одном необычном подходе к генерации лабиринтов. Он основан на модели Амари́ нейронной активности коры головного мозга, являющейся непрерывным аналогом нейронных сетей. При определенных условиях она позволяет создавать красивые лабиринты очень сложной формы, подобные тому, что приведен на картинке.



{kind=link}