
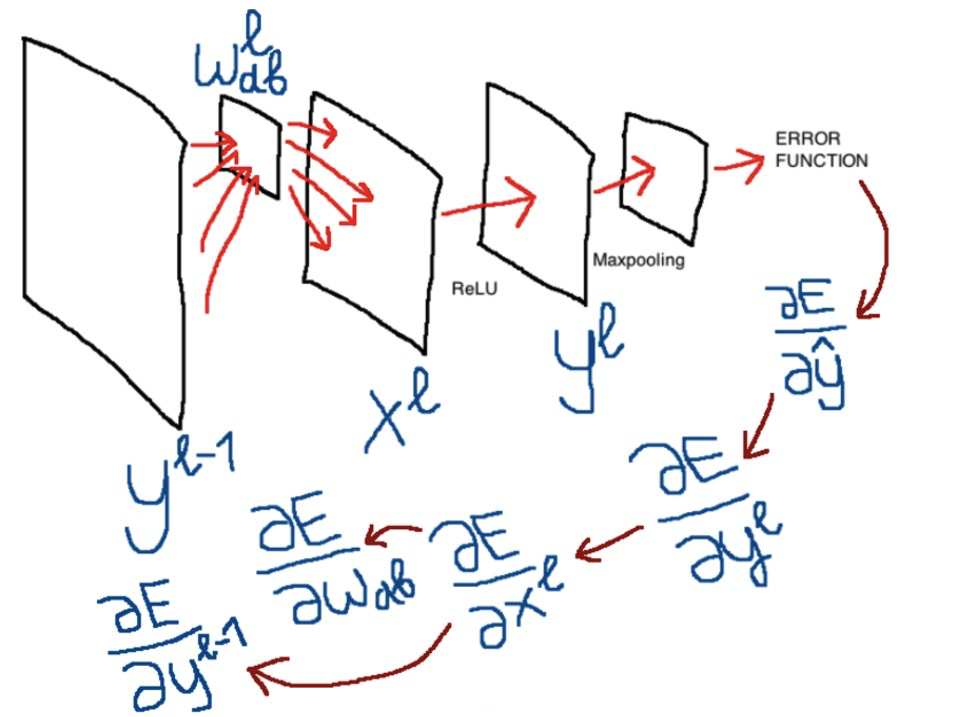
Несмотря на то, что можно найти не одну статью, объясняющую принцип метода обратного распространения ошибки в сверточных сетях (раз, два, три и даже дающих “интуитивное” понимание — четыре), мне, тем не менее, никак не удавалось полностью понять эту тему. Кажется, что авторы недостаточно внимания уделяют обычным примерам либо же опускают какие-то хорошо понятные им, но не очевидные другим особенности, и весь материал по этой причине становится неподъемным. Мне хотелось разложить все по полочкам для самого себя и в итоге конспекты вылились в статью. Я постарался исключить все недостатки существующих объяснений и надеюсь, что эта статья ни у кого не вызовет вопросов или недопониманий. И, может, следующий новичок, который, также как и я, захочет во всем разобраться, потратит уже меньше времени.





 В
В 
 Здравствуйте, коллеги! Это блог открытой русскоговорящей
Здравствуйте, коллеги! Это блог открытой русскоговорящей 


 Мы вновь публикуем расшифровку доклада с конференции
Мы вновь публикуем расшифровку доклада с конференции 
