Морфологический анализатор для русского языка — это что-то заумное? Программа, которая приводит слово к начальной форме, определяет падеж, находит словоформы — непонятно, как и подступиться? А на самом деле все не так и сложно. В статье — как я писал аналог mystem, lemmatizer и phpmorphy на Python, и что из этого получилось.

Алексей @ksurent
User
Penisland, или как написать спеллчекер
7 min
Есть хорошая статья Питера Норвига, в которой он рассказывает как написать спеллчекер в 20 строк кода. В этой статье он показывает как поисковые системы могут исправлять ошибки в запросах. И делает это довольно элегантно. Однако, у его подхода есть два серьезных недостатка. Во-первых, исправление более трех ошибок требует больших ресурсов. А гугл, кстати, неплохо справляется и с четырьмя ошибками. Во-вторых, нет возможности проверки связного текста.

Итак, хочется исправить эти проблемы. А именно, написать корректор коротких фраз или запросов, который:
Остальное — под катом.
Итак, хочется исправить эти проблемы. А именно, написать корректор коротких фраз или запросов, который:
- умел бы выявлять три (и более) ошибки в запросе;
- умел бы проверять «разорванные» или «слипшиеся» фразы, например expertsexchange — experts_exchange, ma na ger — manager
- не требовал много кода для реализации
- мог бы достраиваться до исправления ошибок на других языках и других типов" ошибок
Остальное — под катом.
Map/Reduce: решение реальных задач — TF-IDF
6 min
Вчера я задал вопрос в своем ХабраБлоге — интересно ли людям узнать, что такое Hadoop с точки зрения его реального применения? Оказалось, интересно. Дело недолгое — статью я написал довольно быстро (по крайней мере, ее первую часть) — как минимум, потому, что уже давно знал, о чем собираюсь написать (потому как еще неплохо помню как я сам тыкался в поиске информации, когда начинал пользоваться Hadoop). В первой статье речь пойдет об основах — но совсем не о тех, про которые обычно рассказывают :-)
Перед прочтением статьи я настоятельно рекомендую изучить как минимум первый и последний источники из списка для чтения — их понимание или хотя бы прочтение практически гарантирует, что статья будет понята без проблем. Ну что, поехали?

Ну скажите, какой смысл об этом писать? Уже не раз это проговаривалось, неоднократно начинали писаться посты на тему Hadoop, HDFS и прочая. К сожалению, обычно все заканчивалось на довольно пространном введении и фразе “Продолжение следует”. Так вот: это — продолжение. Кому-то тема, затрагиваемая в этой статье может показаться совершенно тривиальной и неинтересной, однако же лиха беда начало — любые сложные задачи надо решать по частям. Это утверждение, в частности, мы и реализуем в ходе статьи. Сразу замечу, что я постараюсь избежать написания кода в рамках этой конкретной статьи — это может подождать, а понять принципы построения программ, работающих с Map/Reduce можно и “на кошках” (к тому же с текущей частотой кардинального изменения API Hadoop любой код становится obsolete примерно через месяц).
Когда я начинал разбираться с Хадупом, очень большой сложностью лично для меня стало первоначальное понимание идеологии Map/Reduce (я предпочитаю писать это словосочетание именно так, чтобы подчеркнуть, что речь идет не о продукте, а о принципе). Суть и ценность метода станет понятна в самом конце — после того, как мы решим несложную задачу.
Перед прочтением статьи я настоятельно рекомендую изучить как минимум первый и последний источники из списка для чтения — их понимание или хотя бы прочтение практически гарантирует, что статья будет понята без проблем. Ну что, поехали?
Что такое Hadoop?
Ну скажите, какой смысл об этом писать? Уже не раз это проговаривалось, неоднократно начинали писаться посты на тему Hadoop, HDFS и прочая. К сожалению, обычно все заканчивалось на довольно пространном введении и фразе “Продолжение следует”. Так вот: это — продолжение. Кому-то тема, затрагиваемая в этой статье может показаться совершенно тривиальной и неинтересной, однако же лиха беда начало — любые сложные задачи надо решать по частям. Это утверждение, в частности, мы и реализуем в ходе статьи. Сразу замечу, что я постараюсь избежать написания кода в рамках этой конкретной статьи — это может подождать, а понять принципы построения программ, работающих с Map/Reduce можно и “на кошках” (к тому же с текущей частотой кардинального изменения API Hadoop любой код становится obsolete примерно через месяц).
Когда я начинал разбираться с Хадупом, очень большой сложностью лично для меня стало первоначальное понимание идеологии Map/Reduce (я предпочитаю писать это словосочетание именно так, чтобы подчеркнуть, что речь идет не о продукте, а о принципе). Суть и ценность метода станет понятна в самом конце — после того, как мы решим несложную задачу.
Map/Reduce: решение реальных задач — TF-IDF — 2
3 min
Продолжая статью “Использование Hadoop для решения реальных задач”, хочу напомнить, что в прошлой статье мы остановились на том, что посчитали такую характеристику как tf(t,d), и сказали, что в следующем посте мы будем считать idf(t) и завершим процесс вычисления значения TF-IDF для данного документа и термина. Поэтому предлагаю долго не откладывать и переходить к этой задаче.
Важно заметить, что idf(t) не зависит от документа, потому как считается на всем корпусе. Это нетрудно увидеть, посмотрев на формулу:
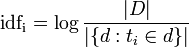
Вероятно, она нуждается в некоторых пояснениях. Итак, |D| это мощность корпуса документов — иными словами, просто количество документов. Мы знаем его, поэтому считать ничего не надо. Знаменатель же логарифма — это количество таких документов d которые содержат интересующий нас токен t_i.
Важно заметить, что idf(t) не зависит от документа, потому как считается на всем корпусе. Это нетрудно увидеть, посмотрев на формулу:
Вероятно, она нуждается в некоторых пояснениях. Итак, |D| это мощность корпуса документов — иными словами, просто количество документов. Мы знаем его, поэтому считать ничего не надо. Знаменатель же логарифма — это количество таких документов d которые содержат интересующий нас токен t_i.
Сверхжадные квантификаторы
4 min
В статье Regexp — это «язык программирования». Основы была поставлена задача: написать регулярное выражение, находящее в цепочке символов текст в двойных кавычках, причем внутри кавычек "..." могут быть и сами символы ", если они экранированы обратным слэшем, например:
Здесь наш регекс должен найти соответствие цепочке
Автором (той статьи) было предложено такое решение:
(здесь и далее синтаксис Perl; ключ /x означает, что пробелы в регексе не учитываются, мы добавили их лишь для наглядности, чтобы части регекса не слились в единый «модемный шум»).
Этот регекс работает в том случае, когда есть совпадение (текст в кавычках). Проблема же в том, что он находит текст в кавычках даже тогда, когда текста в кавычках (согласно нашим правилам экранирования обратным слэшем) просто нет. Например, в цепочке "\" регекс находит соответствие (равное всей строке "\" ), хотя его быть не должно: кавычка открыта, экранированная кавычка… а вот закрывающей-то кавычки нет.
Ситуацию легко исправить, исходную задачу решить несложно, внеся несколько простых изменений в регекс… но речь не об этом, а о том, что если у вас в руках современный инструмент, т. е. движок регексов (свежая версия Perl, Java или PHP с PCRE), то вы можете «исправить» описанный регекс, добавив в него всего лишь 1 символ. Какой? Куда? Почему? Если знаете ответы, то читать дальше вам не стОит ;-)
one two "foo:=\"quux\"; print" three "four"Здесь наш регекс должен найти соответствие цепочке
"foo:=\"quux\"; print"Автором (той статьи) было предложено такое решение:
/ " ( \\" | [^"] )* " /x(здесь и далее синтаксис Perl; ключ /x означает, что пробелы в регексе не учитываются, мы добавили их лишь для наглядности, чтобы части регекса не слились в единый «модемный шум»).
Этот регекс работает в том случае, когда есть совпадение (текст в кавычках). Проблема же в том, что он находит текст в кавычках даже тогда, когда текста в кавычках (согласно нашим правилам экранирования обратным слэшем) просто нет. Например, в цепочке "\" регекс находит соответствие (равное всей строке "\" ), хотя его быть не должно: кавычка открыта, экранированная кавычка… а вот закрывающей-то кавычки нет.
Ситуацию легко исправить, исходную задачу решить несложно, внеся несколько простых изменений в регекс… но речь не об этом, а о том, что если у вас в руках современный инструмент, т. е. движок регексов (свежая версия Perl, Java или PHP с PCRE), то вы можете «исправить» описанный регекс, добавив в него всего лишь 1 символ. Какой? Куда? Почему? Если знаете ответы, то читать дальше вам не стОит ;-)
Распространенные заблуждения про банковские карточки
5 min
Работая долгое время области банковского ПО, а в частности по всяким электронным платежам, вместе с коллегами я составил мини-ЧАВО на тему банковских пластиковых карт. Многие вопросы очевидны, а некоторые могут быть весьма туманными. В России бизнес пластиковых карт набирает обороты, что приятно, и лучше быть подкованным по «матчасти».
Итак, 10 распространенных заблуждений.
Итак, 10 распространенных заблуждений.
Иерархические структуры данных и производительность
14 min
Введение
В своей предыдущей статье я дал краткий обзор основных моделей хранения иерархических структур в реляционных БД. Как и положено тому быть, у многих читателей стал вопрос ребром о производительности представленных алгоритмов.
В данной статье я постараюсь приоткрыть завесу над этим животрепещущим вопросом, а в следующей обещаю коснуться вопросов оптимизации и поисков нестандартных решений.
Full Hierarchy — иерархические структуры в базах данных
5 min
 Здравствуйте. В этой статье я хотел бы написать про один очень интересный способ хранения иерархических структур в базах данных, не относящийся при этом к общепринятым и общеизвестным трём (Adjacency List, Nested Set, Materialized Path). Я не встречал в интернете упоминания о нём, о чём очень удивлен, ведь, по моему мнению, — это лучший и единственный способ хранить иерархические структуры. При разработке console-like форума я воспользовался именно этим способом, о чём ни на грамм не жалею. Это авторская статья и ни одно предложение не было вставлено метотодом копипаста.
Здравствуйте. В этой статье я хотел бы написать про один очень интересный способ хранения иерархических структур в базах данных, не относящийся при этом к общепринятым и общеизвестным трём (Adjacency List, Nested Set, Materialized Path). Я не встречал в интернете упоминания о нём, о чём очень удивлен, ведь, по моему мнению, — это лучший и единственный способ хранить иерархические структуры. При разработке console-like форума я воспользовался именно этим способом, о чём ни на грамм не жалею. Это авторская статья и ни одно предложение не было вставлено метотодом копипаста.Система разделения прав доступа в веб-приложении
14 min
В этой статье мы пройдём с вами полный цикл от идеи, проектирования БД, написания PHP-Кода, и завершающей оптимизации. Постараюсь рассказать обо всем, как можно проще. Использовать для примеров буду PHP и Mysql. Заодно потренирую новичков :).
В этой статье я коснусь вопросов:
1. Идея ACL
2. Проектирование БД
3. Нормализация БД
4. Рефакторинг кода
5. Оптимизация рабочего кода
Статья является ответом на Бинарное распределение прав доступа в CMS. Пока автором пишется практическая часть, я хочу предоставить мой вариант, который я использую довольно давно.
То, что я сейчас расскажу, похоже на ACL.
В этой статье я коснусь вопросов:
1. Идея ACL
2. Проектирование БД
3. Нормализация БД
4. Рефакторинг кода
5. Оптимизация рабочего кода
Статья является ответом на Бинарное распределение прав доступа в CMS. Пока автором пишется практическая часть, я хочу предоставить мой вариант, который я использую довольно давно.
То, что я сейчас расскажу, похоже на ACL.
Ликбез по основам безопасности и криптографии
6 min
Криптография
Три кита криптографии — хеш, шифрование симметричное, шифрование асимметричное (с открытым ключом). Основываются криптографические алгоритмы на сложности вычисления больших чисел, но подробнее об этом, если вас конкретно интересует «начинка», стоит читать не в общих обзорах, именуемых ликбезом. Здесь же содержится простое изложение, без лишних заморочек, то есть поверхностное.
Представления (VIEW) в MySQL
10 min
В комментариях Хабра упоминались вопросы по использованию представлений. Данный топик является обзором представлений, появившихся в MySQL версии 5.0. В нем рассмотрены вопросы создания, преимущества и ограничения представлений.
Представление (VIEW) — объект базы данных, являющийся результатом выполнения запроса к базе данных, определенного с помощью оператора SELECT, в момент обращения к представлению.
Представления иногда называют «виртуальными таблицами». Такое название связано с тем, что представление доступно для пользователя как таблица, но само оно не содержит данных, а извлекает их из таблиц в момент обращения к нему. Если данные изменены в базовой таблице, то пользователь получит актуальные данные при обращении к представлению, использующему данную таблицу; кэширования результатов выборки из таблицы при работе представлений не производится. При этом, механизм кэширования запросов (query cache) работает на уровне запросов пользователя безотносительно к тому, обращается ли пользователь к таблицам или представлениям.
Что такое представление?
Представление (VIEW) — объект базы данных, являющийся результатом выполнения запроса к базе данных, определенного с помощью оператора SELECT, в момент обращения к представлению.
Представления иногда называют «виртуальными таблицами». Такое название связано с тем, что представление доступно для пользователя как таблица, но само оно не содержит данных, а извлекает их из таблиц в момент обращения к нему. Если данные изменены в базовой таблице, то пользователь получит актуальные данные при обращении к представлению, использующему данную таблицу; кэширования результатов выборки из таблицы при работе представлений не производится. При этом, механизм кэширования запросов (query cache) работает на уровне запросов пользователя безотносительно к тому, обращается ли пользователь к таблицам или представлениям.
Что такое нити (threads)?
3 min
Навеяно предыдущей статьей на эту тему.
Для того чтобы, структурировать свое понимание – что представляют собой threads (это слово переводят на русский язык как «нити» почти везде, кроме книг по Win32 API, где его переводят как «потоки») и чем они отличаются от процессов, можно воспользоваться следующими двумя определениями:
Для того чтобы, структурировать свое понимание – что представляют собой threads (это слово переводят на русский язык как «нити» почти везде, кроме книг по Win32 API, где его переводят как «потоки») и чем они отличаются от процессов, можно воспользоваться следующими двумя определениями:
- Thread – это виртуальный процессор, имеющий свой собственный набор регистров, аналогичных регистрам настоящего центрального процессора. Один из наиважнейших регистров у виртуального процессора, как и у реального – это индивидуальный указатель на текущую инструкцию (например, индивидуальный регистр EIP на процессорах семейства x86),
- Процесс – это в первую очередь адресное пространство. В современной архитектуре создаваемое ядром ОС посредством манипуляции страничными таблицами. И уже во вторую очередь на процесс следует смотреть как на точку привязки «ресурсов» в ОC. Если мы разбираем такой аспект, как многозадачность для того, чтобы понять суть threads, то нам не нужно в этот момент думать о «ресурсах» ОС типа файлов и к чему они привязаны.
Процессы и потоки in-depth. Обзор различных потоковых моделей
10 min
Здравствуйте дорогие читатели. В данной статье мы рассмотрим различные потоковые модели, которые реализованы в современных ОС (preemptive, cooperative threads). Также кратко рассмотрим как потоки и средства синхронизации реализованы в Win32 API и Posix Threads. Хотя на Хабре больше популярны скриптовые языки, однако основы — должны знать все ;)
Блокировки в MySQL
4 min
На хабре часто обсуждаются принципы работы MySQL. Данный хабратопик посвящен механизмам блокировок, используемым в MySQL. Топик поможет начинающим изучать MySQL и, в некоторой степени, опытным хабралюдям.
Одновременный доступ нескольких клиентов к хранилищу данных может приводить к ошибкам различного типа. Например, одновременное чтение одним клиентом и запись другим клиентом одной и той же строки таблицы с большой вероятностью приведет к сбою или чтению некорректных данных. Механизмы блокировок позволяют избежать ситуаций одновременного доступа к данным, регламентируя механизм взаимодействия пользователей между собой.
Механизм блокирования в MySQL
Одновременный доступ нескольких клиентов к хранилищу данных может приводить к ошибкам различного типа. Например, одновременное чтение одним клиентом и запись другим клиентом одной и той же строки таблицы с большой вероятностью приведет к сбою или чтению некорректных данных. Механизмы блокировок позволяют избежать ситуаций одновременного доступа к данным, регламентируя механизм взаимодействия пользователей между собой.
Проблема одновременного перестроения кэшей
4 min
Серия постов про “Web, кэширование и memcached” продолжается. Начало здесь: 1, 2 и 3.
В этих постах мы поговорили о memcached, его архитектуре, возможном применении, выборе ключа кэширования, кластеризации, атомарных операциях и реализации счетчиков в memcached.
Сегодня мы рассмотрим проблему одновременного перестроения кэша, которая возникает при большом количестве одновременных обращений к кэшу, который был только что сброшен или потерян, что может привести к перегрузке БД.
Следующий пост будет посвящен тэгированию кэшей.
В этих постах мы поговорили о memcached, его архитектуре, возможном применении, выборе ключа кэширования, кластеризации, атомарных операциях и реализации счетчиков в memcached.
Сегодня мы рассмотрим проблему одновременного перестроения кэша, которая возникает при большом количестве одновременных обращений к кэшу, который был только что сброшен или потерян, что может привести к перегрузке БД.
Следующий пост будет посвящен тэгированию кэшей.
Атомарность операций и счетчики в memcached
5 min
Серия постов про “Web, кэширование и memcached” продолжается. В первом и втором постах мы поговорили о memcached, его архитектуре, возможном применении, выборе ключа кэширования и кластеризации memcached.
Сегодня речь пойдет о:
Следующий пост будет посвящен проблеме одновременного перестроения кэшей.
Сегодня речь пойдет о:
- атомарных операциях в memcached;
- реализации счетчиков просмотров и онлайнеров.
Следующий пост будет посвящен проблеме одновременного перестроения кэшей.
Кластеризация memcached и выбор ключа кэширования
4 min
Серия постов под общим заглавием “Web, кэширование и memcached” продолжается. В первом мы поговорили о memcached, его архитектуре и возможном применении.
Сегодня речь пойдет о:
Следующий пост будет посвящен атомарности операций и счетчикам в memcached.
Сегодня речь пойдет о:
- выборе ключа кэширования;
- кластеризации memcached и алгоритмах распределения ключей.
Следующий пост будет посвящен атомарности операций и счетчикам в memcached.
Проектирование сетевых протоколов
5 min
Поискал по хабру статьи о проектировании протоколов и к своему удивлению ничего не нашел. Пожалуй, стоит тогда поделиться своими соображениями по сабжу. Сразу скажу, что деление на типы сугубо мое и может не совпадать с тем, что вы найдете в справочниках. Также заранее условимся, что используется язык С/C++.
Обзор моделей работы с потоками
4 min
Translation
Обзор моделей работы с потоками
Многие люди не понимают того, как многопоточность реализована в различных языках программирования. В наши времена многоядерных процессоров такое знание будет весьма полезно.
Вот вам небольшой обзор.