qreal QTextDocumentLayoutPrivate::scaleToDevice(qreal value) const
{
if (!paintDevice)
return value;
return value * paintDevice->logicalDpiY() / qreal(qt_defaultDpi());
}
Общая примерная формула фактора скейла — DPI экрана/96.
Но иногда в разных тулкитах фактор может немного отличаться, например DPI/96=1.86, а отскейлят на 2 или прочитают из настроек, игнорируя реальный дисплей.
Вот, например, функция из glfw:
// Retrieve system content scale via folklore heuristics
//
static void getSystemContentScale(float* xscale, float* yscale)
{
// NOTE: Fall back to the display-wide DPI instead of RandR monitor DPI if
// Xft.dpi retrieval below fails as we don't currently have an exact
// policy for which monitor a window is considered to "be on"
float xdpi = DisplayWidth(_glfw.x11.display, _glfw.x11.screen) *
25.4f / DisplayWidthMM(_glfw.x11.display, _glfw.x11.screen);
float ydpi = DisplayHeight(_glfw.x11.display, _glfw.x11.screen) *
25.4f / DisplayHeightMM(_glfw.x11.display, _glfw.x11.screen);
// NOTE: Basing the scale on Xft.dpi where available should provide the most
// consistent user experience (matches Qt, Gtk, etc), although not
// always the most accurate one
char* rms = XResourceManagerString(_glfw.x11.display);
if (rms)
{
XrmDatabase db = XrmGetStringDatabase(rms);
if (db)
{
XrmValue value;
char* type = NULL;
if (XrmGetResource(db, "Xft.dpi", "Xft.Dpi", &type, &value))
{
if (type && strcmp(type, "String") == 0)
xdpi = ydpi = atof(value.addr);
}
XrmDestroyDatabase(db);
}
}
*xscale = xdpi / 96.f;
*yscale = ydpi / 96.f;
}
На удаленной машине соответственно отличаются параметры виртуального дисплея.
Так нет его. Нельзя зарегать еще акк вместо забаненого. А если бы даже не был — этот метод для десятка пользователей с нарушением правил, не для сотен и тысяч. Это не тоже самое что сейчас в андройде.
Ipa возможно тоже можно перекинуть, но не уверен что не надо пересобирать после кидания нового разраба в тиму.
Ну даже так этот новый акк быстро заблокируют, это сразу нарушение, не говоря уже о странной куче фейк-девелоперов (куда миллионы скорее всего технически не запихнуть).
Это как раз один из самых частых кейсов. Интел делает новый чипсет, сата контроллер в нем. В итоге не то что не увидеть — инсталер может просто зависнуть. Так же помню когда на сата только переходили, на фре отваливались сата винты, причем это довольно продолжительное время происходило. Потом вроде стабилизировали, но осадочек остался.
Да, я тоже натыкался, и в msvc тоже. Кстати, чтобы выправить код, его хорошо под свежими компилерами прогнать с -fsanitize=undefined (в старом коде от UB часто баги), address и thread тоже не помешает.
Ууу, снимаю шляпу) Это 5.3 получается?
Но за 5.3 не припомню много багов за пределами того, что он не все поддерживает, sse уже с ним нормально использовали.
Я кстати недавно столкнулся с этой же проблемой — libmpg123 из убунты тормозит. Даже хотел пойти к ним ругаться. Так что да, в репах часто не оптимальные пакеты, потому видимо всякие Clear Linux часто в бенчмарках и обходят.
Так я разве писал что адрес таблички не выносится за цикл? Мне казалось это очевидно, но могут быть проблемы, например компилер может вынести из одного цикла, но не из второго, я с таким сталкивался (с PGO обычно сильно умнеет в этом плане).
Так же доп регистр создает доп давление на внутренний цикл + там есть лишний and который тоже может проявиться: https://gcc.godbolt.org/z/givtXP
Ну и лукап таблички, да. Все это вместе существенно сказывается, это вроде уже по факту просто 10 раз показали. Я это эксперементально проверял, результаты с кодом правда не постил т.к. уже запостили лучше моего. Так что неочень понятно чего тут не соглашаться.
Собственно про это я уже писал, glibc версии возьмут структуру локали из TLS и сделают лукап в табличке. При этом там еще будет вызов функции: https://gcc.godbolt.org/z/MC2oZi. Видно что накладные расходы существенны даже с случае си локали и тут ничего не сделать — только явно использовать/переключить на оптимизированные функции.
А какой-нибудь APC не может произойти и выделить память? А так же всякие CreateRemoteThread и то что после CreateToolhelp32Snapshot может добавиться тред.
Ну то есть для целиком своего приложения наверно можно, но для генерик либы, что может встраиваться куда угодно, например в игру, где еще система защиты работает выглядит опасно.
Я тоже с проблемой выделения не сталкивался. Но вот с другой проблемой столкнулся недавно. Оказывается нельзя надежно выделить Magic Ring Buffer (то есть одну и ту же память смапить 2 раза подряд).
Логичным решением было бы зарезервировать место VirtualAlloc с MEM_RESERVE и в это адресное пространство сделать MapViewOfFile 2 раза по фиксированному адресу.
Так вот это не работает, область MEM_RESERVE надо обязательно сделать VirtualFree, что не дает гарантии что после освобождения это пространство кто другой в процессе не займет. Из за этого в либах делают итерации попыток: https://github.com/gnzlbg/slice_deque/blob/master/src/mirrored/winapi.rs#L78 и 100% гарантии что сработает тут нет.
Если кто подскажет решение буду благодарен. Вообще странно что о такой простой вещи не подумали, и непонятно зачем вообще тогда нужна функциональность мапа по фиксированному адресу.
Круто :) Я примерно это и имел ввиду под вариантом "16бит табличку" но полного понимания как сделать еще не было. Я делал такое немного для других кейсов.
На оптимизацию wc (включая упомянутые мной кусочки) потратили менее получаса? Не верю, извините.
На wc не уверен, т.к. у него больше опций, а вот на вариант потипу yleo — да, во всяком случае в принципе столько, сколько уйдет у меня на это на си. То что си многословнее, тяжелее подстановки — я не спорю. Но ваш посыл, что напишите идеоматично на си и на хаскеле и получите быстрее хаскель — не верно.
Вот посыл напишите такие мелкие консольные утилиты на языках, которые для этого предназначены, например на перле, а не на си. Времени потратите меньше, а скорость будет возможно даже такая же, как на си. И корректное сравнение с вариантом yleo — вот тогда было бы все корректно в статье.
А coreutils — у него задача предоставить core утилиты на голом железе, с зависимостью только от си компилятора, который можно уместить в 300кб кода на нем же (привет tcc). Но кажется все знают что для текстового процессора не лучший выбор.
А там же нет вызовов рантайма. Вы просто бежите по куску памяти и просто инкреметируете счётчики. Там даже вызовов функций может не быть, если компилятор всё заинлайнил (или если используется прямая проверка на пробельные символы, как в предложенных альтернативных С-вариантах).
В wc есть вызовы glibc, может и не влияет, но надо проверять. Так же ghc стандартные isspace, — поддерживает только latin1 (как я понял), а в glibc — поддерживает локали и надо ходить в tls.
У ghc даже стека в привычном смысле нет, хехе. Вот это как раз сравнивать будет очень сложно.
Вот и я про то, надо глянуть асм, скорее всего -fomit-frame-pointer тоже потребуется для корректного сравнения.
Что си, что хаскель можно попробовать еще ускорить. Можно попробовать 16бит табличку, можно попробовать читать по 4-8 байт и разбираться с прочитанным в регистре (для парсинга http заголовков это помогало, односимвольные слова возможно ухудшит).

Есть еще вот такое: https://github.com/xoreaxeaxeax/movfuscator
Только инструкциями mov.
Для снапа:
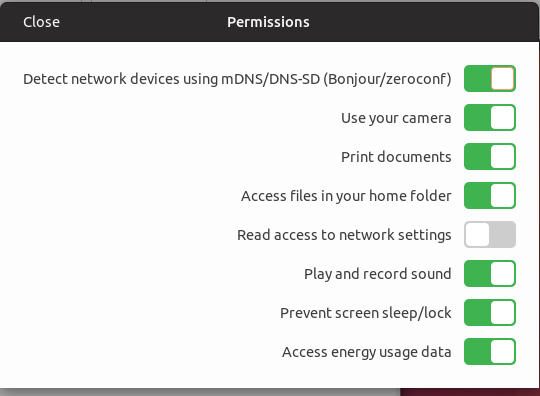
См тык.
Для Flatpack:
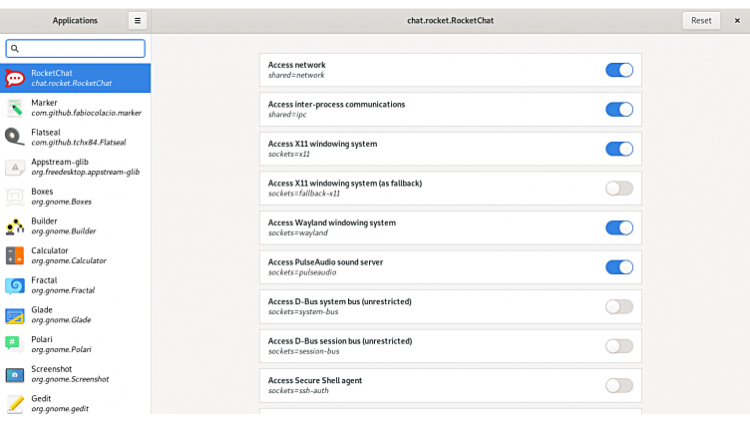
См тык.
В Qt шрифты вот так скейлятся:
Общая примерная формула фактора скейла — DPI экрана/96.
Но иногда в разных тулкитах фактор может немного отличаться, например DPI/96=1.86, а отскейлят на 2 или прочитают из настроек, игнорируя реальный дисплей.
Вот, например, функция из glfw:
На удаленной машине соответственно отличаются параметры виртуального дисплея.
Так нет его. Нельзя зарегать еще акк вместо забаненого. А если бы даже не был — этот метод для десятка пользователей с нарушением правил, не для сотен и тысяч. Это не тоже самое что сейчас в андройде.
Не очень понял, testflight улетит вместе с приложением из стора и дев аккаунтом.
А под нужно дать всем профиль на установку вы предлагаете завести новый аккаунт, и кидать миллионы пользователей в тиму как разработчиков
https://developer.apple.com/library/archive/documentation/General/Conceptual/ApplicationDevelopmentOverview/CreateYourDevelopmentTeam/CreateYourDevelopmentTeam.html
чтобы они скачали development provisioning profiles и смогли запустить проект из Xcode на локально подключенном девайсе?
Ipa возможно тоже можно перекинуть, но не уверен что не надо пересобирать после кидания нового разраба в тиму.
Ну даже так этот новый акк быстро заблокируют, это сразу нарушение, не говоря уже о странной куче фейк-девелоперов (куда миллионы скорее всего технически не запихнуть).
Уже работает: far2l --tty
Выглядит как то что надо, спасибо. Жаль что только десятка, прежде чем только на это полагаться придется подождать.
Кроме Tox, есть еще https://jami.net/ и https://github.com/loki-project/session-desktop
Это как раз один из самых частых кейсов. Интел делает новый чипсет, сата контроллер в нем. В итоге не то что не увидеть — инсталер может просто зависнуть. Так же помню когда на сата только переходили, на фре отваливались сата винты, причем это довольно продолжительное время происходило. Потом вроде стабилизировали, но осадочек остался.
Да, я тоже натыкался, и в msvc тоже. Кстати, чтобы выправить код, его хорошо под свежими компилерами прогнать с -fsanitize=undefined (в старом коде от UB часто баги), address и thread тоже не помешает.
Ууу, снимаю шляпу) Это 5.3 получается?
Но за 5.3 не припомню много багов за пределами того, что он не все поддерживает, sse уже с ним нормально использовали.
Не центось и не 7й gcc случаем?
Я кстати недавно столкнулся с этой же проблемой — libmpg123 из убунты тормозит. Даже хотел пойти к ним ругаться. Так что да, в репах часто не оптимальные пакеты, потому видимо всякие Clear Linux часто в бенчмарках и обходят.
Так я разве писал что адрес таблички не выносится за цикл? Мне казалось это очевидно, но могут быть проблемы, например компилер может вынести из одного цикла, но не из второго, я с таким сталкивался (с PGO обычно сильно умнеет в этом плане).
Так же доп регистр создает доп давление на внутренний цикл + там есть лишний and который тоже может проявиться: https://gcc.godbolt.org/z/givtXP
Ну и лукап таблички, да. Все это вместе существенно сказывается, это вроде уже по факту просто 10 раз показали. Я это эксперементально проверял, результаты с кодом правда не постил т.к. уже запостили лучше моего. Так что неочень понятно чего тут не соглашаться.
Собственно про это я уже писал, glibc версии возьмут структуру локали из TLS и сделают лукап в табличке. При этом там еще будет вызов функции: https://gcc.godbolt.org/z/MC2oZi. Видно что накладные расходы существенны даже с случае си локали и тут ничего не сделать — только явно использовать/переключить на оптимизированные функции.
А какой-нибудь APC не может произойти и выделить память? А так же всякие CreateRemoteThread и то что после CreateToolhelp32Snapshot может добавиться тред.
Ну то есть для целиком своего приложения наверно можно, но для генерик либы, что может встраиваться куда угодно, например в игру, где еще система защиты работает выглядит опасно.
На лине и маке да, такой проблемы нет.
Я тоже с проблемой выделения не сталкивался. Но вот с другой проблемой столкнулся недавно. Оказывается нельзя надежно выделить Magic Ring Buffer (то есть одну и ту же память смапить 2 раза подряд).
Логичным решением было бы зарезервировать место VirtualAlloc с MEM_RESERVE и в это адресное пространство сделать MapViewOfFile 2 раза по фиксированному адресу.
Так вот это не работает, область MEM_RESERVE надо обязательно сделать VirtualFree, что не дает гарантии что после освобождения это пространство кто другой в процессе не займет. Из за этого в либах делают итерации попыток: https://github.com/gnzlbg/slice_deque/blob/master/src/mirrored/winapi.rs#L78 и 100% гарантии что сработает тут нет.
Если кто подскажет решение буду благодарен. Вообще странно что о такой простой вещи не подумали, и непонятно зачем вообще тогда нужна функциональность мапа по фиксированному адресу.
Круто :) Я примерно это и имел ввиду под вариантом "16бит табличку" но полного понимания как сделать еще не было. Я делал такое немного для других кейсов.
Интересно конечно, с ходу больше не могу придумать как еще можно ускорить.
На wc не уверен, т.к. у него больше опций, а вот на вариант потипу yleo — да, во всяком случае в принципе столько, сколько уйдет у меня на это на си. То что си многословнее, тяжелее подстановки — я не спорю. Но ваш посыл, что напишите идеоматично на си и на хаскеле и получите быстрее хаскель — не верно.
Вот посыл напишите такие мелкие консольные утилиты на языках, которые для этого предназначены, например на перле, а не на си. Времени потратите меньше, а скорость будет возможно даже такая же, как на си. И корректное сравнение с вариантом yleo — вот тогда было бы все корректно в статье.
А coreutils — у него задача предоставить core утилиты на голом железе, с зависимостью только от си компилятора, который можно уместить в 300кб кода на нем же (привет tcc). Но кажется все знают что для текстового процессора не лучший выбор.
В wc есть вызовы glibc, может и не влияет, но надо проверять. Так же ghc стандартные isspace, — поддерживает только latin1 (как я понял), а в glibc — поддерживает локали и надо ходить в tls.
Вот и я про то, надо глянуть асм, скорее всего -fomit-frame-pointer тоже потребуется для корректного сравнения.
Что си, что хаскель можно попробовать еще ускорить. Можно попробовать 16бит табличку, можно попробовать читать по 4-8 байт и разбираться с прочитанным в регистре (для парсинга http заголовков это помогало, односимвольные слова возможно ухудшит).