
Кто разводит рыбок? Или решение загадки Эйнштейна регулярным языком
5 мин
Многие сталкивались с головоломкой про пять разноцветных домов, в каждом из которых живет человек со своими любимыми животным, напитком и сигаретами. Эта загадка приписывается Эйнштейну, хотя прямых подтверждений этому нет. Полный текст этой головоломки есть на википедии.
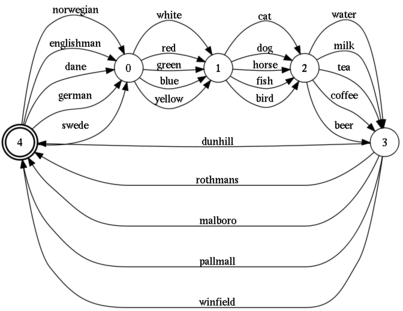
Ее можно решить на бумаге или в уме, последовательно исключая неподходящие варианты. Однако, ее также можно решить более технично. Один из способов — написать программку на прологе. Но здесь я хочу ее решить используя более простые механизмы — регулярные выражения. А именно, перевести условия загадки на язык регекспов и свести задачу к поиску подходящей строки во всем допустимом наборе строк. Кстати, этот набор строк показан на рисунке.
Ее можно решить на бумаге или в уме, последовательно исключая неподходящие варианты. Однако, ее также можно решить более технично. Один из способов — написать программку на прологе. Но здесь я хочу ее решить используя более простые механизмы — регулярные выражения. А именно, перевести условия загадки на язык регекспов и свести задачу к поиску подходящей строки во всем допустимом наборе строк. Кстати, этот набор строк показан на рисунке.
