Сам по себе поиск работы в сфере IT достаточно прост. Что же касается поиска вакансий с возможность релокации, здесь уже сложнее. Несмотря на то, что технологические компании по всему миру сейчас активно нанимают разработчиков и других IT-специалистов из-за рубежа, поиск таких вакансий забирает достаточно много сил и времени.
В этой статье я решил собрать наиболее популярные сайты/ресурсы, на которых реально найти вакансии с переездом в страны Европы.
Telegram-каналы
Джоб-борды для IT-специалистов и нишевые сайты
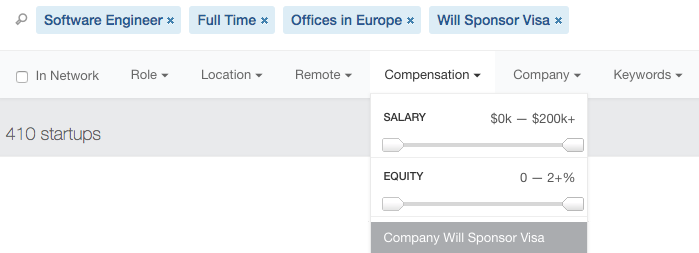
На сегодняшний день AngelList является одним из наиболее популярных сайтов по поиску работы в стартапах по всему миру. Процесс поиска вакансий с релокацией на этом сайте очень прост – во вкладке «
Compensation» выбираем опцию «
Company Will Sponsor Visa». Чтобы сузить полученный список вакансий до максимально релевантных, можно использовать фильтры «
Role» и «
Location».
Многие из вас, наверное, хотя бы раз сталкивались с сайтом Glassdoor. Прежде всего, Glassdoor известен как ресурс, на котором можно почитать отзывы инсайдеров о том или ином работодателе, а также о процессе собеседования и заработных платах в интересующей компании. Помимо этого, на сайте есть огромное количество вакансий в разных странах мира, и не только для IT-специалистов.
Чтобы найти вакансии, которые предлагают релокейт, пишем в поисковой строке
relocation developer или
relocation и название интересной вам позиции. Чтобы сузить результаты поиска, уточняем город/страну, куда хотели бы переехать.
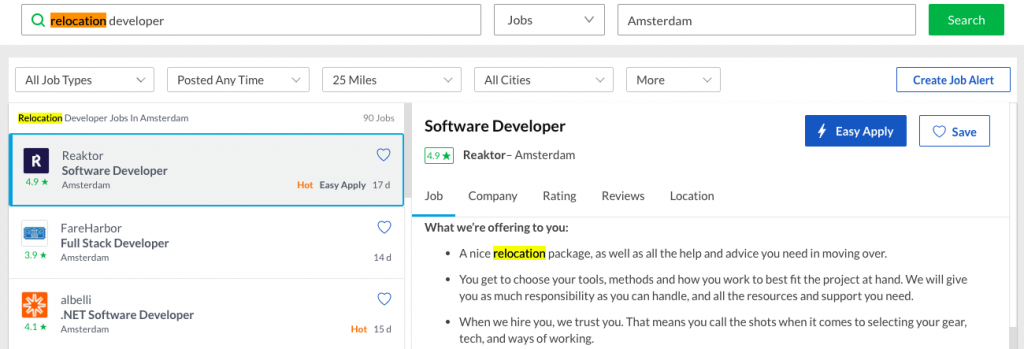
Поскольку на сайте Glassdoor нет специального фильтра для поиска работы с переездом, при поиске вакансий описанным выше методом могут попадаться нерелевантные. В целом же, ключевое слово
relocation в поисковой строке делает свое дело.









 Компания Badoo одной из первых перешла на PHP 7 — мы совсем недавно
Компания Badoo одной из первых перешла на PHP 7 — мы совсем недавно