Самое быстрое и эффективное взаимодействие между людьми происходит посредством устной речи. С помощью речи могут быть переданы различные чувства и эмоции, а главное — полезная информация. Необходимость создания компьютерных интерфейсов звукового ввода-вывода не вызывает сомнений, поскольку их эффективность основана на практически неограниченных возможностях формулировки в самых различных областях человеческой деятельности.

Анатолий Левчик @mirt
Пользователь
Чему нас не научил профессор Ng
6 min
 Как видно по дискуссиям на хабре, несколько десятков хабровчан прослушали курс ml-class.org Стэнфордского университета, который провел обаятельнейший профессор Andrew Ng. Я тоже с удовольствием прослушал этот курс. К сожалению, из лекций выпала очень интересная тема, заявленная в плане: комбинирование обучения с учителем и обучения без учителя. Как оказалось, профессор Ng опубликовал отличный курс по этой теме — Unsupervised Feature Learning and Deep Learning (спонтанное выделение признаков и глубокое обучение). Предлагаю краткий конспект этого курса, без строгого изложения и обилия формул. В оригинале все это есть.
Как видно по дискуссиям на хабре, несколько десятков хабровчан прослушали курс ml-class.org Стэнфордского университета, который провел обаятельнейший профессор Andrew Ng. Я тоже с удовольствием прослушал этот курс. К сожалению, из лекций выпала очень интересная тема, заявленная в плане: комбинирование обучения с учителем и обучения без учителя. Как оказалось, профессор Ng опубликовал отличный курс по этой теме — Unsupervised Feature Learning and Deep Learning (спонтанное выделение признаков и глубокое обучение). Предлагаю краткий конспект этого курса, без строгого изложения и обилия формул. В оригинале все это есть.Полупроводниковая электроника
30 min
Tutorial

Полупроводниковая электроника существенно изменила мир. Многие вещи, которые долгое время не сходили со страниц произведений фантастов стали возможны. Чтобы знать, как работают и чем уникальны полупроводниковые приборы, необходимо понимание различных физических процессов, протекающих внутри.
В статье разобраны принципы работы основных полупроводниковых устройств. Описание функционирования изложено с позиции физики. Статья содержит вводное описание терминов, необходимых для понимания материала широкому кругу читателей.

Иллюстраций: 34, символов: 51 609.
One Definition Rule, inline и неожиданные последствия их сочетания
4 min
C++ требует, чтобы любая функция была определена не более одного раза – One Definition Rule, ODR. Как только вы определяете функцию с одним и тем же именем и сигнатурой в разных единицах трансляции (файлах .cpp), вы получаете индикацию ошибки на этапе линковки.
inline функции обычно определяются в заголовочных файлах (.h), чтобы все единицы трансляции могли видеть реализацию функции и подставить ее по месту вызова. Соответственно, как только вы включите заголовочный файл с такой функцией в более чем одну единицу трансляции, ODR будет формально нарушено, но… никакой индикации ошибки вы не получите.
Почему и какие неожиданные последствия это может иметь?
inline функции обычно определяются в заголовочных файлах (.h), чтобы все единицы трансляции могли видеть реализацию функции и подставить ее по месту вызова. Соответственно, как только вы включите заголовочный файл с такой функцией в более чем одну единицу трансляции, ODR будет формально нарушено, но… никакой индикации ошибки вы не получите.
Почему и какие неожиданные последствия это может иметь?
C++ MythBusters. Миф о подставляемых функциях
5 min
Здравствуйте.
Благодаря вот этому голосованию выяснилось, что на Хабре не хватает статей по такому мощному, но всё менее используемому языку C++. Профессионалам высокого уровня, гуру, магам и волшебникам языка C++, а также тем, кто уже успел оставить этот язык «позади» можно дальше не читать. Сегодня я хочу начать цикл статей, призванных помочь именно новичкам, относительно недавно начавшим изучать этот язык, либо же тем, кто (упаси Боже) читает мало книг, а пытается познавать всё исключительно на практике.
Также я надеюсь привлечь как можно больше авторов к написанию подобных статей, потому как моего опыта здесь будет явно недостаточно.
Благодаря вот этому голосованию выяснилось, что на Хабре не хватает статей по такому мощному, но всё менее используемому языку C++. Профессионалам высокого уровня, гуру, магам и волшебникам языка C++, а также тем, кто уже успел оставить этот язык «позади» можно дальше не читать. Сегодня я хочу начать цикл статей, призванных помочь именно новичкам, относительно недавно начавшим изучать этот язык, либо же тем, кто (упаси Боже) читает мало книг, а пытается познавать всё исключительно на практике.
Также я надеюсь привлечь как можно больше авторов к написанию подобных статей, потому как моего опыта здесь будет явно недостаточно.
Пишем примитивный и никому не нужный компилятор
9 min
Я считаю, что каждый программист должен написать свой компилятор.
Я сам долгое время считал, что создание компиляторов — это удел элиты, а простому смертному программисту не постичь этой науки. Попробую доказать, что это не так.
В посте мы рассмотрим, как можно написать свой компилятор C-подобного языка меньше чем за час, исписав всего 300 строчек кода. В качестве бонуса, сюда входит и код виртуальной машины, в байткод которой будет компилироваться исходник.
Я сам долгое время считал, что создание компиляторов — это удел элиты, а простому смертному программисту не постичь этой науки. Попробую доказать, что это не так.
В посте мы рассмотрим, как можно написать свой компилятор C-подобного языка меньше чем за час, исписав всего 300 строчек кода. В качестве бонуса, сюда входит и код виртуальной машины, в байткод которой будет компилироваться исходник.
Десяток ресурсов, которые помогают быть дизайнером
2 min
Работать дизайнером очень интересно. Это творческая работа. И как любому творческому человеку, дизайнеру нужна муза или вдохновение.
Я уверен, что у каждого дизайнера есть набор сайтов, на которые они периодически заходят для того что бы черпать это самое вдохновение. У меня так же есть такой список. И я хочу им с вами поделиться.
Естественно, если вы расскажите о своих ресурсах, я буду благодарен.
Хочу сразу предупредить, что практически все ресурсы, собранные мной — англоязычные. Только лишь один на русском. Так же я не очень приветствую узкопрофильные ресурсы (речь о ресурсах, на которых можно скачать только кисти для photoshop и прочее).
Я уверен, что у каждого дизайнера есть набор сайтов, на которые они периодически заходят для того что бы черпать это самое вдохновение. У меня так же есть такой список. И я хочу им с вами поделиться.
Естественно, если вы расскажите о своих ресурсах, я буду благодарен.
Хочу сразу предупредить, что практически все ресурсы, собранные мной — англоязычные. Только лишь один на русском. Так же я не очень приветствую узкопрофильные ресурсы (речь о ресурсах, на которых можно скачать только кисти для photoshop и прочее).
Уникальные возможности Tarantool
4 min

Tarantool — это крайне интересная база данных.
Представление о ней можно получить из доклада Константина Осипова Tarantool: как обрабатывать 1,5 млрд запросов в сутки?
Этой заметкой я хочу обратить внимание на уникальные возможности, которые отличают Tarantool от других подобных решений и делают его полезным инструментом.
Кроме того, я расскажу, чем можно помочь этому открытому проекту и почему это круто :)
Все что вы хотели знать о мастерах операций, но боялись спросить
27 min

Большинство системных администраторов в своей корпоративной среде для обеспечения системы идентификации и доступа своих пользователей к ресурсам предприятия используют доменные службы Active Directory, которые смело можно назвать сердцем всей инфраструктуры предприятия. Как многие из вас знают, структура доменных служб в организациях может включать в себя как один, так и несколько лесов (набор доменов, включающих описание сетевой конфигурации и единственный экземпляр каталога), в зависимости от таких факторов как ограничение области доверительных отношений, полное разделение сетевых данных, получение административной изоляции. В свою очередь, каждый большой лес для упрощения администрирования и репликации данных должен разделяться на домены. В каждом домене для управления доменными службами и выполнения таких задач как проверка подлинности, запуск службы «Центр распределения ключей Kerberos» и управления доступом используются контроллеры домена. А для управления сетевым трафиком между офисами разрабатываются сайты.
Категория Hask
7 min
Вступление
В этой небольшой статье я расскажу о теории категорий в контексте системы типов языка Haskell. Никакой зауми, никаких уловок – постараюсь объяснять всё наглядно. Я хочу показать тесную связь языка программирования с математикой, чтобы спровоцировать у читателя осознание одного, через другое и наоборот.
Не хотелось бы повторять перевод на эту тему, который уже был на хабре: Монады с точки зрения теории категорий, но для целостности статьи, я всё же буду давать основные определения. При этом, в отличие от той статьи, я не хочу делать основной упор на математику.
Эта статья во многом повторяет (в том числе заимствует иллюстрации) раздел из английской Haskell Wikibook, но тем не менее не является непосредственным переводом.
Что такое категория?
Примеры
Для наглядности рассмотрим сначала пару картинок изображающих простые категории. На них есть красные кружочки и стрелки:
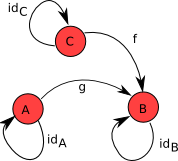

Красные кружочки изображают «объекты», а стрелки – «морфизмы».
Я хочу привести один наглядный пример из реальной жизни, который даст какое-то интуитивное представление о природе объектов и морфизмов:
Можно считать города «объектами», а перемещения между городами – «морфизмами». Например, можно представить себе карту авиарейсов (как-то не нашёл я удачную картинку) или карту железных дорог – они будут похожи на картинки выше, только сложнее. Следует обратить внимание на два момента, которые кажутся в реальности само собой разумеющимися, но для дальнейшего имеют важное значение:
- Бывает, что из одного города в другой никак не попасть поездом или самолётом – между этими городами нет морфизмов.
- Если мы перемещаемся в пределах одного и того же города, то это тоже морфизм – мы как бы путешествуем из города в него же.
- Если из Санкт-Петербурга есть поезд до Москвы, а из Москвы есть авиарейс в Амстердам, то мы можем купить билет на поезд и билет на самолёт, “скомбинировать” их и таким образом попасть из Санкт-Петербурга в Амстердам – то есть можно на нашей карте нарисовать стрелку от Санкт-Петербурга до Амстердама изображающую этот скомбинированный морфизм.
Паттерн Visitor. Продвинутое использование
7 min
Здравствуйте, дорогие хабравчане!
Я хочу поделиться с вами своим опытом использования паттерна проектирования visitor и его интересной модификацией, которую я назвал upcast visitor. К сожалению, непросто придумать простой короткий пример и описать как все работает, также эта статья может показаться сложной для начинающих, тем не менее я постараюсь максимально упростить задачу. Примеры кода приведены на языке С++ и обязательны к прочтению. Без понимания кода вникнуть в суть статьи будет затруднительно.
Представьте, что мы проектируем 2D игру, в которой фрукты падают с дерева, по пути ударяясь о ветки. Цель игры — поймать все фрукты, двигая корзину под деревом.
Строим следующую диаграмму классов:
Я хочу поделиться с вами своим опытом использования паттерна проектирования visitor и его интересной модификацией, которую я назвал upcast visitor. К сожалению, непросто придумать простой короткий пример и описать как все работает, также эта статья может показаться сложной для начинающих, тем не менее я постараюсь максимально упростить задачу. Примеры кода приведены на языке С++ и обязательны к прочтению. Без понимания кода вникнуть в суть статьи будет затруднительно.
Предыстория
Представьте, что мы проектируем 2D игру, в которой фрукты падают с дерева, по пути ударяясь о ветки. Цель игры — поймать все фрукты, двигая корзину под деревом.
Строим следующую диаграмму классов:
Нечёткий поиск в тексте и словаре
13 min
Введение
Алгоритмы нечеткого поиска (также известного как поиск по сходству или fuzzy string search) являются основой систем проверки орфографии и полноценных поисковых систем вроде Google или Yandex. Например, такие алгоритмы используются для функций наподобие «Возможно вы имели в виду …» в тех же поисковых системах.
В этой обзорной статье я рассмотрю следующие понятия, методы и алгоритмы:
- Расстояние Левенштейна
- Расстояние Дамерау-Левенштейна
- Алгоритм Bitap с модификациями от Wu и Manber
- Алгоритм расширения выборки
- Метод N-грамм
- Хеширование по сигнатуре
- BK-деревья
Что нужно знать про арифметику с плавающей запятой
14 min

В далекие времена, для IT-индустрии это 70-е годы прошлого века, ученые-математики (так раньше назывались программисты) сражались как Дон-Кихоты в неравном бою с компьютерами, которые тогда были размером с маленькие ветряные мельницы. Задачи ставились серьезные: поиск вражеских подлодок в океане по снимкам с орбиты, расчет баллистики ракет дальнего действия, и прочее. Для их решения компьютер должен оперировать действительными числами, которых, как известно, континуум, тогда как память конечна. Поэтому приходится отображать этот континуум на конечное множество нулей и единиц. В поисках компромисса между скоростью, размером и точностью представления ученые предложили числа с плавающей запятой (или плавающей точкой, если по-буржуйски).
Арифметика с плавающей запятой почему-то считается экзотической областью компьютерных наук, учитывая, что соответствующие типы данных присутствуют в каждом языке программирования. Я сам, если честно, никогда не придавал особого значения компьютерной арифметике, пока решая одну и ту же задачу на CPU и GPU получил разный результат. Оказалось, что в потайных углах этой области скрываются очень любопытные и странные явления: некоммутативность и неассоциативность арифметических операций, ноль со знаком, разность неравных чисел дает ноль, и прочее. Корни этого айсберга уходят глубоко в математику, а я под катом постараюсь обрисовать лишь то, что лежит на поверхности.
Вычисления с фиксированной точкой. Основные принципы (ч.1)
11 min
Введение или зачем этот топик
Читая Хабрахабр, я натолкнулся на два топика, «выводящие на чистую воду» вычисления с плавающей запятой.
В одном из них достаточно подробно и качественно дана выжимка из стандарта IEEE754 и основные проблемы при вычислениях с плавающей запятой, другой — короткий топик-заметка про то, что не все так хорошо при вычислениях на ПК. При этом даются рекомендации в случае, когда важна математическая точность результата, использовать целочисленные вычисления, «фиксировать запятую» или как минимум проверять результаты, выдаваемые платформой (компилятор + процессор).
Несмотря на то, что советы дельные, понять, как использовать целочисленные вычисления там, где до этого была плавающая запятая, не так просто, особенно без математической подготовки. Достаточно занимательна в этом смысле попытка одного из «хабровчан» разобраться с фиксированной точкой методом экспериментов.
Данный топик — краткое введение, которое должно дать представление о вычислениях с фиксированной точкой. Математика в данной статье не должна никого напугать — все очень примитивно. Сразу прошу простить: среди моих знакомых устоявшимся выражением является именно «фиксированная точка» (от англ., fixed-point), а не «запятая», поэтому я буду придерживаться именно этого термина.
Описание работы алгоритма Shift-OR для поиска подстроки в строке
3 min
1. Вместо вступления.
Недавно пришлось разбираться в работе алгоритма Shift-Or, который позволяет найти подстроку в строке. По результатам этого разбора я и решил написать этот пост в надежде, что кому-то он поможет понять, как работает этот алгоритм, быстрее чем мне.
Собственно, главное отличие алгоритма от, например, «наивного сравнения», заключается в том, что в его основе лежит логические операции, а именно логическое умножение (оно же AND, оно же конъюнкция).
Еще немного про P и NP
7 min
Существует большая разница между задачами непростыми и задачами сложными. Задача может не иметь эффективных решений в самых худших случаях, но может оставаться легко решаемой для большинства случаев, или для случаев, возникающих на практике. Поэтому общепринятые определения сложности задач могут оказаться относительно бессмысленными в терминах реальной сложности, так как две задачи могут быть NP-полными, но одна при этом в большинстве случаев может решаться быстро, а другая нет. Как следствие, важную роль в теории сложности играет понятие «сложности в среднем» (здесь под «средним» понимается математическое ожидание времени решения).
Чтобы проиллюстрировать центральную роль этого понятия, можно вообразить пять различных возможных миров (возможных — потому что еще не доказано, что они нереальны, и наш может оказаться любым из них) и посмотреть как условия в них будут влиять на информатику и жизнь вообще.
Библия проектирования. Часть первая. Создание мира
3 min

Ну вот ты и стал главным. Теперь все тебя будут слушаться, а твои спецификации будут цитировать в джире зарвавшимся еретикам. Твое творение будет вечным, и пока ты здесь, никто не сможет его уничтожить. На радостях ты выпиваешь лишние пол-литра амброзии, а в понедельник приходишь с больной головой, готовый творить.
Свой инструмент нужно знать в лицо: обзор наиболее часто используемых структур данных
8 min
Некоторое время назад я сходил на собеседование в одну довольно большую и уважаемую компанию. Собеседование прошло хорошо и понравилось как мне, так и, надеюсь, людям его проводившим. Но на следующий день, в процессе разбора полетов, я обнаружил, что в ходе собеседования ответ на как минимум один вопрос был неверен.
Вопрос: Почему поиск в python dict на больших объемах данных быстрее чем итерация по индексированному массиву?
Ответ: В dict хранятся хэши от ключей. Каждый раз, когда мы ищем в dict значение по ключу, мы сначала вычисляем его хэш, а потом (внезапно), выполняем бинарный поиск. Таким образом, сложность составляет O(lg(N))!
На самом деле никакого бинарного поиска тут нет. И сложность алгоритма не O(lg(N)), а Amort. O(1) — так как в основе dict питона лежит структура под названием Hash Table.
Причиной неверного ответа было то, что я не удосужился досконально изучить те структуры, которые лежат в основе работы с коллекциями моего любимого языка. Правда, по результатам опроса нескольких знакомых разработчиков, оказалось что это не только моя проблема, очень многие вообще не задумываются, как работают коллекции в их любимых ЯП. А ведь используем мы их каждый день и не по разу. Так родилась идея этой статьи.
Пьеса «Разработка многопользовательской сетевой игры.» Часть 3: Клиент-серверное взаимодействие
7 min
Recovery Mode
Часть 1: Архитектура
Часть 2: Протокол
Часть 4: Переходим в 3D
С третьей частью я немного задержался. Но как говорится лучше поздно чем никогда…
Итак, продолжаем разговор.
В третьей части нашей постановки мы реализуем протокол, напишем сервер и клиент которые будут взаимодействрвать по сети. И (ОМГ!) танки будут ездить!
Под катом то, что вы давно хотели, но боялись спросить…