Отличный вопрос.
Надо начать с того, что zencad оперирует с граничным представлением. То есть до момента конвертации в STL меш сети нет, а есть аналитическая сферическая поверхность.
При конвертации в STL (Через графический интерфейс, или же при использовании api) система предлагает выбрать параметр delta, который влияет на разрешение конечной модели (Вообще у opencascade больше параметров. Со временем они будут добавлены). Как конкретно этот параметр влияет, надо смотреть в документации на opencascade, но точно можно сказать, что чем он меньше тем больше точность.
Я протестировал openscad и zencad на обыкновенной сфере. Длина stl файла для zencad при delta==0.001 превышает длину файла stl для openscad при fn=300. Следовательно точность можно сделать выше. С другой стороны, время генерации файлов практически одинаковое.
Преимущество zencad здесь как раз в том, что zencad строит меш сеть только в момент конвертации, в то время как openscad проводит булевы операции прямо над полигональной сетью. Поэтому чем больше разрешение, тем больше требуется вычислительных ресурсов. В zencad операции вычисления модели и построения сети развязаны. Можно даже построить модель в zencad, экспортировать ее во freecad, после чего сгенирировать там мешсеть так, как это необходимо.
Ограничений связей как таковых нет. Для того, чтобы сделать сборку надо взять несколько тел и транслировать их в нужные места. Анализа перекрытия тел так же не производится.
Вообще, сборки в zencad — это просто визуализация нескольких невзаимодействующих тел на одной сцене.
Связи как таковые тут не нужны, потому что вы все равно не сможете переместить тело мышкой по сцене. Локация жестко определена скриптом. Концепт не тот…
Но думаю, это всё же не наш метод. Строго говоря, для zencad графический интерфейс — это что-то прикрученное сверху. Чем меньше обратных связей от gui к скрипту, тем прозрачнее работа системы.
Мне кажется, если человеку нужна нодовая система, он возьмёт Rhino или того же Houdini… И будет прав. Не зачем лезть в чужой огород.
zencad — это для программистов, которым понадобилось 3д.
В мануале даже девиз написан: CAD system for righteous zen programmers
Мне это представление всегда казалось новомодным ненужным наворотом. Это как функциональные диаграммы и Verilog. Verilog явно более могучий.
Такое представление, конечно, можно сделать, хотя оно будет работать только до тех пор, пока мы не подтягиваем дополнительных библиотек. А фишка ZenCad как раз в интеграции с экосистемой python. Сделать можно… Только зачем? Нодовое представление — это такой костыль, который применяется интерактивным графическим кадом, чтобы добавить параметризуемость, не добавляя скрипты, потому-что скрипты нарушают красивое дерево модели. А zencad — это как бы сразу о скриптах…
В общем, имхо, лишнее это…
Кстати… Если уж на то пошло, evalcache, который занимается контролем ленивых вычислений в zencad умеет визуализировать дерево вычисления в консоли (Для отладочных целей). Так что задача нодового построения фактически решена. Хотя и не нужна на мой взгляд.
Правильный или неправильный, полноценный или неполноценный САПР, это уж как кому нравится. ZenCad в комплект конструкторской документации уметь не собирается. Это не его задача. Зубчатые передачи и резьбы планируются, но не как готовые элементы, а скорее как набор библиотечных функций.
Я прорабатывал вопрос интеграции с FreeCad… Пока вызвать силами FreeCad скрипт zencad без некоторой головной боли не получается, но можно использовать brep файлы для передачи геометрии.
Blender и FreeCad используют python как расширяющую часть своего движка. И хотя тот же FreeCad можно использовать без графического интерфейса, полноценно писать модели на нем скриптами врядли получится.
В целом, думаю, ответ нет. Та ниша, на которую нацелен zencad не пересекает ареал обитания не Blender, ни FreeCad. Задача ZenCad в том, чтобы писать параметризуемые модели без лишней головной боли. Да, ZenCad напрямую конкурирует с OpenScad. Это естественно, так как он является попыткой преодолеть недостатки OpenScad. Очень условно конфликтует с pythonOCC — тут явно разные цели. Крайне условно с solidpython… (В силу убогости концепта последнего, да простят меня его разработчики...).
Вообще, вопрос хаоса всегда решается проработанными интерфейсами. Тогда получается не хаос, а живая экосистема, где каждая библиотека занимается своей частью работы. Тот же pythonOCC имеет интерфейс к FreeCad. Если так получится, что zencad получит сколь-нибудь значительную популярность, можно будет попробовать заполучить во FreeCad интерфейс и для ZenCad. (Мне сейчас в голову пришла мысль, что возможно удасться подсунуть геометрию из ZenCad в интерфейс для pythonOCC. Было бы удобно.)…
Вообще, сопряжения как таковые тут не прописываются.
Всё делается за счет правильно расчитанных цепочек размеров. Этим же обеспечивается параметризуемость и перестраиваемость.
Думаю, разработка windows версии на текущий момент в приоритете. Проект достаточно неплох, чтобы предложить его широкому кругу пользователей. Понятно, что без windows версии широкого распространения пока ждать не приходится. Так что над windows версией буду работать.
Вообще, изначально я собирался писать статью уже после проработки windows версии. Но там еще непочатый край работы, а лайки хочется собрать уже сейчас…
Вроде бы мнение о разных мозгах сформировалось под влиянием того факта, что мозг мужчины в среднем на сто грамм тяжелее мозга женщины. Во всяком такую версию я слышал. Дальнейшие исследования, впрочем, как утверждал тот же источник, показали, что вся эта масса приходится на соединительное вещество. По видимому мужчин чаще бьют по голове.
В очередной раз хочу упомянуть, что классификация есть проявление работы интеллекта.
В объективной реальности нет живой и неживой материи. Нет мягкого и жесткого времени, операционных систем реального времени и встраиваемых ОС. Это общие принципы, черты системы, которые выделяются нами, людьми, чтобы нам удобно было говорить о созданных нами системах.
Понимание того, что есть система реального времени может различаться у исследователя и практика. Потому что им в их работе удобно другое чуть-чуть другое понимание этого термина. Хотя говорят они об одном и тоже объективном явлении.
В зависимости от решаемой мной задачи, вирус может быть формой жизни, а может не быть ей. Это конечно не то знание, которым стоит ломать стройную картину миру студентам вузов и прочим лицам, пытающимся сформировать непротиворечивую картину мира, но с какого-то уровня понимания, все же стоит держать в голове, что это все это просто слова.
Фактически здесь на уровень логирования переноситься идея сборок Debug/Release. Строго говоря, он, вероятно, прав когда ставит под сомнения схему trace/debug/info/warn/error/fatal, как единственно возможную, но схема info/debug буквально требует второй уровень приоритетов.
Например, я часто в warning пишу информацию, которой уместнее было бы жить на уровне debug, но которая имеет определенную степень важности. На уровне debug она просто потеряется вследствии его загаженности. В этом смысле вызывает вопрос, что warning приоритетней info.
Вероятно, стоит задуматься над более гибкой схемой настройки уровней логирования.
Как лучше выбрать модель телефона под эксперимент с использованием с LinageOS?
Есть ли какая-то сводная таблица, или надо каждую модель искать на 4pda (сайте производителя) отдельно?

Надо начать с того, что zencad оперирует с граничным представлением. То есть до момента конвертации в STL меш сети нет, а есть аналитическая сферическая поверхность.
При конвертации в STL (Через графический интерфейс, или же при использовании api) система предлагает выбрать параметр delta, который влияет на разрешение конечной модели (Вообще у opencascade больше параметров. Со временем они будут добавлены). Как конкретно этот параметр влияет, надо смотреть в документации на opencascade, но точно можно сказать, что чем он меньше тем больше точность.
Я протестировал openscad и zencad на обыкновенной сфере. Длина stl файла для zencad при delta==0.001 превышает длину файла stl для openscad при fn=300. Следовательно точность можно сделать выше. С другой стороны, время генерации файлов практически одинаковое.
Преимущество zencad здесь как раз в том, что zencad строит меш сеть только в момент конвертации, в то время как openscad проводит булевы операции прямо над полигональной сетью. Поэтому чем больше разрешение, тем больше требуется вычислительных ресурсов. В zencad операции вычисления модели и построения сети развязаны. Можно даже построить модель в zencad, экспортировать ее во freecad, после чего сгенирировать там мешсеть так, как это необходимо.
Вон вчера краники на смесители напечатал :).
Вообще, сборки в zencad — это просто визуализация нескольких невзаимодействующих тел на одной сцене.
Связи как таковые тут не нужны, потому что вы все равно не сможете переместить тело мышкой по сцене. Локация жестко определена скриптом. Концепт не тот…
Но думаю, это всё же не наш метод. Строго говоря, для zencad графический интерфейс — это что-то прикрученное сверху. Чем меньше обратных связей от gui к скрипту, тем прозрачнее работа системы.
Мне кажется, если человеку нужна нодовая система, он возьмёт Rhino или того же Houdini… И будет прав. Не зачем лезть в чужой огород.
zencad — это для программистов, которым понадобилось 3д.
В мануале даже девиз написан: CAD system for righteous zen programmers
Такое представление, конечно, можно сделать, хотя оно будет работать только до тех пор, пока мы не подтягиваем дополнительных библиотек. А фишка ZenCad как раз в интеграции с экосистемой python. Сделать можно… Только зачем? Нодовое представление — это такой костыль, который применяется интерактивным графическим кадом, чтобы добавить параметризуемость, не добавляя скрипты, потому-что скрипты нарушают красивое дерево модели. А zencad — это как бы сразу о скриптах…
В общем, имхо, лишнее это…
Кстати… Если уж на то пошло, evalcache, который занимается контролем ленивых вычислений в zencad умеет визуализировать дерево вычисления в консоли (Для отладочных целей). Так что задача нодового построения фактически решена. Хотя и не нужна на мой взгляд.
Я прорабатывал вопрос интеграции с FreeCad… Пока вызвать силами FreeCad скрипт zencad без некоторой головной боли не получается, но можно использовать brep файлы для передачи геометрии.
Blender и FreeCad используют python как расширяющую часть своего движка. И хотя тот же FreeCad можно использовать без графического интерфейса, полноценно писать модели на нем скриптами врядли получится.
В целом, думаю, ответ нет. Та ниша, на которую нацелен zencad не пересекает ареал обитания не Blender, ни FreeCad. Задача ZenCad в том, чтобы писать параметризуемые модели без лишней головной боли. Да, ZenCad напрямую конкурирует с OpenScad. Это естественно, так как он является попыткой преодолеть недостатки OpenScad. Очень условно конфликтует с pythonOCC — тут явно разные цели. Крайне условно с solidpython… (В силу убогости концепта последнего, да простят меня его разработчики...).
Вообще, вопрос хаоса всегда решается проработанными интерфейсами. Тогда получается не хаос, а живая экосистема, где каждая библиотека занимается своей частью работы. Тот же pythonOCC имеет интерфейс к FreeCad. Если так получится, что zencad получит сколь-нибудь значительную популярность, можно будет попробовать заполучить во FreeCad интерфейс и для ZenCad. (Мне сейчас в голову пришла мысль, что возможно удасться подсунуть геометрию из ZenCad в интерфейс для pythonOCC. Было бы удобно.)…
Всё делается за счет правильно расчитанных цепочек размеров. Этим же обеспечивается параметризуемость и перестраиваемость.
Не совсем понял про сопряжения…
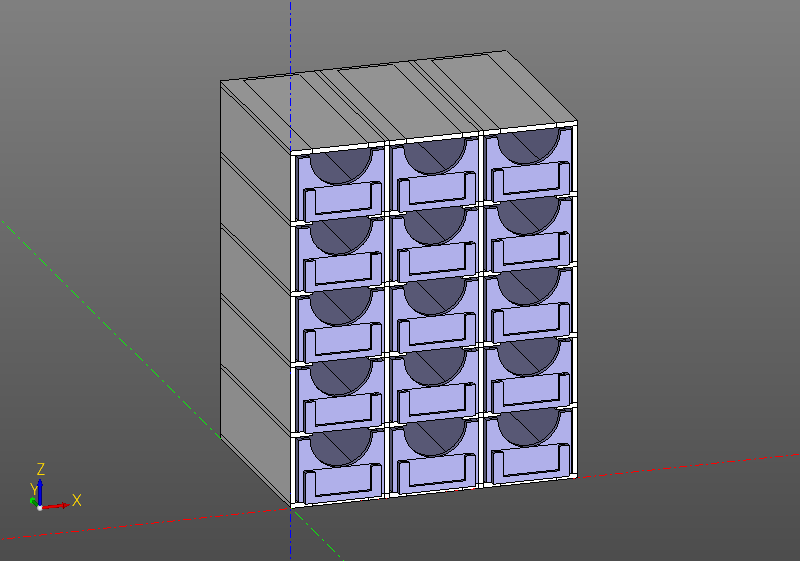
В примерах, которые идут с библиотекой есть такой пример:
Organizer
Вот результат работы этого примера:
Также можно посмотреть сюда:
Zippo
Это модель моего 4-х колёсного робота, представленного на первом скриншоте.
Вообще, изначально я собирался писать статью уже после проработки windows версии. Но там еще непочатый край работы, а лайки хочется собрать уже сейчас…
В объективной реальности нет живой и неживой материи. Нет мягкого и жесткого времени, операционных систем реального времени и встраиваемых ОС. Это общие принципы, черты системы, которые выделяются нами, людьми, чтобы нам удобно было говорить о созданных нами системах.
Понимание того, что есть система реального времени может различаться у исследователя и практика. Потому что им в их работе удобно другое чуть-чуть другое понимание этого термина. Хотя говорят они об одном и тоже объективном явлении.
В зависимости от решаемой мной задачи, вирус может быть формой жизни, а может не быть ей. Это конечно не то знание, которым стоит ломать стройную картину миру студентам вузов и прочим лицам, пытающимся сформировать непротиворечивую картину мира, но с какого-то уровня понимания, все же стоит держать в голове, что это все это просто слова.
Например, я часто в warning пишу информацию, которой уместнее было бы жить на уровне debug, но которая имеет определенную степень важности. На уровне debug она просто потеряется вследствии его загаженности. В этом смысле вызывает вопрос, что warning приоритетней info.
Вероятно, стоит задуматься над более гибкой схемой настройки уровней логирования.
Есть ли какая-то сводная таблица, или надо каждую модель искать на 4pda (сайте производителя) отдельно?