В этой статье Вы узнаете всё о Вавилонской библиотеке, а самое главное — как воссоздать её, да и вообще любую библиотеку.

Борис Орехов @nevmenandr
Компьютерный лингвист
Python + OpenCV + Keras: делаем распознавалку текста за полчаса
12 min
Привет Хабр.
После экспериментов с многим известной базой из 60000 рукописных цифр MNIST возник логичный вопрос, есть ли что-то похожее, но с поддержкой не только цифр, но и букв. Как оказалось, есть, и называется такая база, как можно догадаться, Extended MNIST (EMNIST).
Если кому интересно, как с помощью этой базы можно сделать несложную распознавалку текста, добро пожаловать под кат.

После экспериментов с многим известной базой из 60000 рукописных цифр MNIST возник логичный вопрос, есть ли что-то похожее, но с поддержкой не только цифр, но и букв. Как оказалось, есть, и называется такая база, как можно догадаться, Extended MNIST (EMNIST).
Если кому интересно, как с помощью этой базы можно сделать несложную распознавалку текста, добро пожаловать под кат.
Алиса, Google Assistant, Siri, Alexa. Как писать приложения для голосовых ассистентов
12 min

Рынок голосовых ассистентов расширяется, особенно для русскоязычных пользователей. 2 недели назад Яндекс рассказала впервые про платформу Яндекс.Диалоги, 2 месяца назад Google представила возможность писать диалоги для Google Assistant на русском языке, 2 года назад со сцены Bill Graham Civic Auditorium Apple выпустила в открытое плавание SiriKit. Фактически, появляется новая отрасль разработки, где должны быть свои проектировщики, архитекторы и разработчики. Идеальный момент, чтобы поговорить про голосовые помощники и api для них.
В этой статье не будет подробных туториалов. Это статья об идеях и интересных технических деталях, на которых построены инструменты для сторонних разработчиков основных игроков рынка: Apple Siri, Google Assistant и Алисы от Яндекса.
Datalore: открываем бета-версию приложения для анализа данных на Python
3 min
Привет, Хабр!
В рядах инструментов JetBrains пополнение. Мы запускаем открытую бета-версию Datalore — умной веб-среды для анализа и визуализации данных на языке Python.
Машинное обучение уверенно захватывает мир: алгоритмы интеллектуального анализа данных стоят за современными коммерческими разработками и исследованиями. Мы разработали приложение, с которым решать задачи машинного обучения легко и приятно: все необходимые инструменты data science доступны из коробки, а умный редактор кода на Python облегчает процесс анализа данных.

В рядах инструментов JetBrains пополнение. Мы запускаем открытую бета-версию Datalore — умной веб-среды для анализа и визуализации данных на языке Python.
Машинное обучение уверенно захватывает мир: алгоритмы интеллектуального анализа данных стоят за современными коммерческими разработками и исследованиями. Мы разработали приложение, с которым решать задачи машинного обучения легко и приятно: все необходимые инструменты data science доступны из коробки, а умный редактор кода на Python облегчает процесс анализа данных.
Как писать на ассемблере в 2018 году
13 min
Статья посвящена языку ассемблер с учетом актуальных реалий. Представлены преимущества и отличия от ЯВУ, произведено небольшое сравнение компиляторов, скрупулёзно собрано значительное количество лучшей тематической литературы.
Python, под пиратским флагом
8 min
Tutorial
 Йо-хо-хо, хабровчане!
Йо-хо-хо, хабровчане!Пока IT сообщество увлеченно наблюдает за криптовалютами и их добычей, я решил помайнить то, что майнилось задолго до того, как крипта и все связанное с ней стало мэйнстримом. Речь конечно же об игровом золоте в ММО играх.
Реализовать задумку мне помог python 3.6 и советы коллег программистов. Хотя статья и будет опираться на пример в конкретной игре, цель ее больше не рассказать историю хака, а расхвалить питон и показать еще не освоившим, что с ним может делать человек-не-программист и почему это так круто.
Git снизу вверх
27 min
Translation
У этого перевода не совсем обычная история. Системы контроля версий далеки от моих профессиональных интересов. Для рабочих проектов они мне требовались нечасто, причем, разные, так что, каждый раз, когда возникала такая необходимость, я заново вспоминала, как в них делается та или иная операция. А для личных проектов мне хватало возможностей Dropbox, хранящей историю версий файлов.

Изображение из твиттера @girlie_mac
Но вот однажды я на три незабываемых дня попала в роддом — это иногда случается с женщинами. Из развлечений у меня были новорожденная дочь и телефон с большим экраном. Дочь поначалу развлекала плохо (дома она быстро исправилась), а на телефоне помимо книг и фильмов обнаружился текст «Git from the bottom up», который оказался более чем годным… С тех пор прошло почти 3 года, подросшей дочке уже пора самой начинать использовать Git Git стал мейнстримом, если не сказать стандартом в современной разработке, а я с удивлением обнаружила, что перевода на русский этого чуда, полезного не только начинающим, но и продвинутым пользователям Git, до сих пор нет. Исправляю эту ситуацию.
Изображение из твиттера @girlie_mac
Но вот однажды я на три незабываемых дня попала в роддом — это иногда случается с женщинами. Из развлечений у меня были новорожденная дочь и телефон с большим экраном. Дочь поначалу развлекала плохо (дома она быстро исправилась), а на телефоне помимо книг и фильмов обнаружился текст «Git from the bottom up», который оказался более чем годным… С тех пор прошло почти 3 года,
Учим компьютер писать как Толстой, том I
5 min
Tutorial
— Eh bien, mon prince. Gênes et Lucques ne sont plus que des apanages, des поместья, de la famille Buonaparte. Non, je vous préviens que si vous ne me dites pas que nous avons la guerre, si vous vous permettez encore de pallier toutes les infamies, toutes les atrocités de cet Antichrist (ma parole, j'y crois) — je ne vous connais plus, vous n'êtes plus mon ami, vous n'êtes plus мой верный раб, comme vous dites 1. Ну, здравствуйте, здравствуйте. Je vois que je vous fais peur 2, садитесь и рассказывайте.
ТОМ ПЕРВЫЙ
ЧАСТЬ ПЕРВАЯ. Анна Каренина
Недавно на хабре наткнулся на эту статью https://habrahabr.ru/post/342738/. И захотелось написать про word embeddings, python, gensim и word2vec. В этой части я постараюсь рассказать о обучении базовой модели w2v.
Итак, приступаем.
- Качаем anaconda. Устанавливаем.
- Еще нам пригодится C/C++ tools от visual studio.
- Теперь устанавливаем gensim. Именно для него нам и нужен c++.
- Устанавливаем nltk.
- При установке не забудьте качать библиотеки для Anaconda, а не для стандартного интерпретатора. Иначе все кончится крахом.
- Качаем Анну Каренину в TXT.
- Советую открыть файл и вырезать оттуда рекламу и заголовки. Потом сохранить в формате
utf-8. - Можно приступать к работе.
RNN: может ли нейронная сеть писать как Лев Толстой? (Спойлер: нет)
16 min
Tutorial
При изучении технологий Deep Learning я столкнулся с нехваткой относительно простых примеров, на которых можно относительно легко потренироваться и двигаться дальше.
В данном примере мы построим рекуррентную нейронную сеть, которая получив на вход текст романа Толстого «Анна Каренина», будет генерировать свой текст, чем-то напоминающий оригинал, предсказывая, какой должен быть следующий символ.
Структуру изложения я старался делать такой, чтобы можно было повторить все шаги новичку, даже не понимая в деталях, что именно происходит внутри этой сети. Профессионалы Deep Learning скорее всего не найдут тут ничего интересного, а тех, кто только изучает эти технологии, прошу под кат.
В данном примере мы построим рекуррентную нейронную сеть, которая получив на вход текст романа Толстого «Анна Каренина», будет генерировать свой текст, чем-то напоминающий оригинал, предсказывая, какой должен быть следующий символ.
Структуру изложения я старался делать такой, чтобы можно было повторить все шаги новичку, даже не понимая в деталях, что именно происходит внутри этой сети. Профессионалы Deep Learning скорее всего не найдут тут ничего интересного, а тех, кто только изучает эти технологии, прошу под кат.
Как правильно оформить Open Source проект
7 min
Tutorial
В свободное и не свободное время[1] я развиваю несколько своих проектов на github, а также, по мере сил, участвую в жизни интересных для меня, как программиста, проектах.
Недавно один из коллег попросил консультацию: как выложить разработанную им библиотеку на github. Библиотека никак не связана с бизнес-логикой приложения компании, по сути это адаптер к некоему API, реализующему определённый стандарт. Помогая ему, я понял что вещи, интуитивно понятные и давно очевидные для меня, в этой области, совершенно неизвестны человеку делающему это впервые и далёкому от Open Source.
Я провел небольшое исследование и обнаружил что большинство публикаций по этой теме на habrahabr освещают тему участия (contributing), либо просто мотивируют каким-нибудь образом примкнуть к Open Source, но не дают исчерпывающей инструкции как правильно оформить свой проект. В целом в рунете, если верить Яндекс, тема освещена со стороны мотивации, этикета контрибуции и основ пользования github. Но не с точки зрения конкретных шагов, которые следует предпринять.
Так что из себя представляет стильный, модный, молодёжный Open Source проект в 201* году?
Типичные распределения вероятности: шпаргалка data scientist-а
11 min
Translation
У data scientist-ов сотни распределений вероятности на любой вкус. С чего начать?
Data science, чем бы она там не была – та ещё штука. От какого-нибудь гуру на ваших сходках или хакатонах можно услышать:«Data scientist разбирается в статистике лучше, чем любой программист». Прикладные математики так мстят за то, что статистика уже не так на слуху, как в золотые 20е. У них даже по этому поводу есть своя несмешная диаграмма Венна. И вот, значит, внезапно вы, программист, оказываетесь совершенно не у дел в беседе о доверительных интервалах, вместо того, чтобы привычно ворчать на аналитиков, которые никогда не слышали о проекте Apache Bikeshed, чтобы распределённо форматировать комментарии. Для такой ситуации, чтобы быть в струе и снова стать душой компании – вам нужен экспресс-курс по статистике. Может, не достаточно глубокий, чтобы вы всё понимали, но вполне достаточный, чтобы так могло показаться на первый взгляд.
{kind=link}
Открытый курс машинного обучения. Тема 9. Анализ временных рядов с помощью Python
27 min
Доброго дня! Мы продолжаем наш цикл статей открытого курса по машинному обучению и сегодня поговорим о временных рядах.
 Посмотрим на то, как с ними работать в Python, какие возможные методы и модели можно использовать для прогнозирования; что такое двойное и тройное экспоненциальное взвешивание; что делать, если стационарность — это не про вас; как построить SARIMA и не умереть; и как прогнозировать xgboost-ом. И всё это будем применять к примеру из суровой реальности.
Посмотрим на то, как с ними работать в Python, какие возможные методы и модели можно использовать для прогнозирования; что такое двойное и тройное экспоненциальное взвешивание; что делать, если стационарность — это не про вас; как построить SARIMA и не умереть; и как прогнозировать xgboost-ом. И всё это будем применять к примеру из суровой реальности.
UPD 01.2022: С февраля 2022 г. ML-курс ODS на русском возрождается под руководством Петра Ермакова couatl. Для русскоязычной аудитории это предпочтительный вариант (c этими статьями на Хабре – в подкрепление), англоговорящим рекомендуется mlcourse.ai в режиме самостоятельного прохождения.
Видеозапись лекции по мотивам этой статьи в рамках второго запуска открытого курса (сентябрь-ноябрь 2017).
Лекции Техносферы: Программирование на Go
2 min

Продолжаем публикацию наших образовательных материалов. Этот курс посвящен изучению основ языка Go. На примере простой текстовой игры будут рассмотрены все основные задачи, с которыми сталкивается разработчик современных веб-приложений в крупных проектах, с реализацией их на Go. Курс не ставит задачи научить программированию с нуля, для обучения будут необходимы базовые навыки программирования.
Список лекций:
R, GIS и fuzzyjoin: восстанавливаем статистические данные для регионов NUTS
12 min
В этом посте речь пойдет о том, как я восстанавливал демографические данные для регионов Дании, где после реформы территориального устройства 2007 года официальной гармонизации данных не проводилось. Это лишь небольшая часть гармонизации евростатовских данных, которую я выполнил в рамках своего phd проекта. Пост сперва опубликован в моем англоязычном блоге и в блоге Demotrends. Думаю, что он может быть интересен далеко не только демографам.
Что такое NUTS?
NUTS расшифровывается как Nomenclature of Territorial Units For Statistics. Это стандартизированная система административно-территориального деления, принятая странами Евросоюза. История вопроса уходит в 1970-е, когда родилась идея сделать регионы различных стран Европы сопоставимыми. В более или менее законченном и широко употребимом виде система появилась лишь на рубеже веков. Существуют три основных уровня NUTS (см. рис. 1), и наиболее распространенным в региональном анализе оказывается NUTS-2.
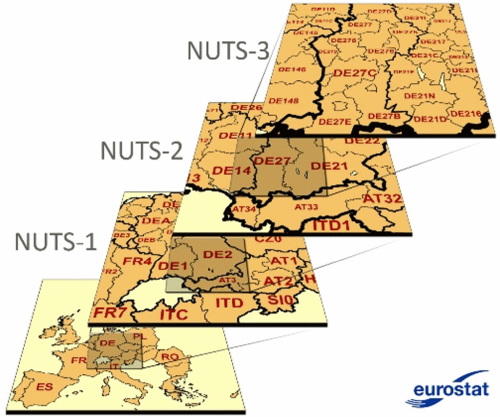
Рисунок 1. Иллюстрация принципа выделения регионов NUTS различного иерархического уровня
Предсказываем будущее с помощью библиотеки Facebook Prophet
10 min
 Прогнозирование временных рядов — это достаточно популярная аналитическая задача. Прогнозы используются, например, для понимания, сколько серверов понадобится online-сервису через год, каков будет спрос на каждый товар в гипермаркете, или для постановки целей и оценки работы команды (для этого можно построить baseline прогноз и сравнить фактическое значение с прогнозируемым).
Прогнозирование временных рядов — это достаточно популярная аналитическая задача. Прогнозы используются, например, для понимания, сколько серверов понадобится online-сервису через год, каков будет спрос на каждый товар в гипермаркете, или для постановки целей и оценки работы команды (для этого можно построить baseline прогноз и сравнить фактическое значение с прогнозируемым).
Существует большое количество различных подходов для прогнозирования временных рядов, такие как ARIMA, ARCH, регрессионные модели, нейронные сети и т.д.
Сегодня же мы познакомимся с библиотекой для прогнозирования временных рядов Facebook Prophet (в переводе с английского, "пророк", выпущена в open-source 23-го февраля 2017 года), а также попробуем в жизненной задаче – прогнозировании числа постов на Хабрехабре.
Квантовые шахматы
12 min
Intro
Этот пост написан под впечатлением от вот этого отличного поста с Хабра, в котором автор наглядно, при помощи двумерных моделек, которые рисует его программа, объясняет как работает Специальная Теория Относительности.
Я работаю в IT, а по образованию – физик-теоретик. Уже долгое время увлекаюсь популяризацией науки, и теоретической физики в частности. Постараюсь аналогично вышеупомянутому посту о специальной теории относительности объяснить на специально подготовленном примере как работает квантовая механика.
Модель, которую я рассматриваю – отнюдь не нова. Более полугода назад Chris Cantwell разместил на YouTube анонс новой настольной игры: квантовых шахмат (многим, возможно, известно об этом из вот этого вирусного ролика).
Недавно игра вышла в Steam, она стоит 249 руб. Есть ещё другая реализация – бесплатное приложение для iOS (не знаю, есть ли оно в Google Play). Однако в процессе игр с друзьями я экспериментально выяснил, что она неправильная с точки зрения квантовой механики. Такую реализацию скорее можно назвать статистическими шахматами, а не квантовыми.
Поэтому я решил написать свою реализацию, с запутанностью и суперпозициями. В своей реализации я постарался исправить те недостатки, которые на мой взгляд присутствуют в версии на Steam (например, у меня пешки тоже могут ходить квантовыми ходами, как и все остальные фигуры). Про приложение для iOS и так всё понятно: любая реализация квантовых шахмат должна быть по-настоящему квантовой, т.е. не только быть вероятностной, но поддерживать такие эффекты квантовой механики как интерференция, запутанность, etc.
Открытый курс машинного обучения. Тема 2: Визуализация данных c Python
15 min

Второе занятие посвящено визуализации данных в Python. Сначала мы посмотрим на основные методы библиотек Seaborn и Plotly, затем поанализируем знакомый нам по первой статье набор данных по оттоку клиентов телеком-оператора и подглядим в n-мерное пространство с помощью алгоритма t-SNE. Есть и видеозапись лекции по мотивам этой статьи в рамках второго запуска открытого курса (сентябрь-ноябрь 2017).
UPD 01.2022: С февраля 2022 г. ML-курс ODS на русском возрождается под руководством Петра Ермакова couatl. Для русскоязычной аудитории это предпочтительный вариант (c этими статьями на Хабре – в подкрепление), англоговорящим рекомендуется mlcourse.ai в режиме самостоятельного прохождения.
Сейчас статья уже будет существенно длиннее. Готовы? Поехали!
Самые полезные приёмы работы в командной строке Linux
5 min
Translation
Каждый, кто пользуется командной строкой Linux, встречался со списками полезных советов. Каждый знает, что повседневные дела вполне можно выполнять эффективнее, да только вот одно лишь это знание, не подкреплённое практикой, никому не приносит пользы.
Как выглядят типичные трудовые будни системного администратора, который сидит на Linux? Если абстрагироваться от всего, кроме набираемых на клавиатуре команд, то окажется, что команды эти постоянно повторяются. Всё выходит на уровень автоматизма. И, если даже в работе есть что улучшать, привычка противится новому. Как результат, немало времени уходит на то, чтобы делать так, как привычнее, а не так, как быстрее, и, после небольшого периода привыкания – удобнее. Помнить об этом, сознательно вводить в собственную практику новые полезные мелочи – значит профессионально расти и развиваться, значит – экономить время, которое можно много на что потратить.

Перед вами – небольшой список полезных приёмов работы с командной строкой Linux. С некоторыми из них вы, возможно, уже знакомы, но успели их позабыть. А кое-что вполне может оказаться приятной находкой даже для знатоков. Хочется надеяться, что некоторые из них будут вам полезны и превратятся из «списка» в живые команды, которыми вы будете пользоваться каждый день.
Как выглядят типичные трудовые будни системного администратора, который сидит на Linux? Если абстрагироваться от всего, кроме набираемых на клавиатуре команд, то окажется, что команды эти постоянно повторяются. Всё выходит на уровень автоматизма. И, если даже в работе есть что улучшать, привычка противится новому. Как результат, немало времени уходит на то, чтобы делать так, как привычнее, а не так, как быстрее, и, после небольшого периода привыкания – удобнее. Помнить об этом, сознательно вводить в собственную практику новые полезные мелочи – значит профессионально расти и развиваться, значит – экономить время, которое можно много на что потратить.
Перед вами – небольшой список полезных приёмов работы с командной строкой Linux. С некоторыми из них вы, возможно, уже знакомы, но успели их позабыть. А кое-что вполне может оказаться приятной находкой даже для знатоков. Хочется надеяться, что некоторые из них будут вам полезны и превратятся из «списка» в живые команды, которыми вы будете пользоваться каждый день.
Telegram-бот, webhook и 50 строк кода
5 min
Tutorial
Recovery Mode
Как, опять? Ещё один туториал, пережёвывающий официальную документацию от Telegram, подумали вы? Да, но нет! Это скорее рассуждения на тему того, как построить функциональный бот-сервис используя Python3.5+, asyncio и aiohttp. Тем интереснее, что заголовок на самом деле лукавит…
Как я покупал квартиру
11 min
Я хотел написать статью про линейную регрессию, но потом подумал, да ну её, лучше куплю квартиру. И пошёл искать, что предлагают. А предлагают, как оказалось, много чего. В подходящий мне ценовой диапозон попало больше 500 квартир. И что, мне теперь все это просматривать? Ну нееет, программист я в конце концов или не программист. Надо это дело как-то автоматизировать.