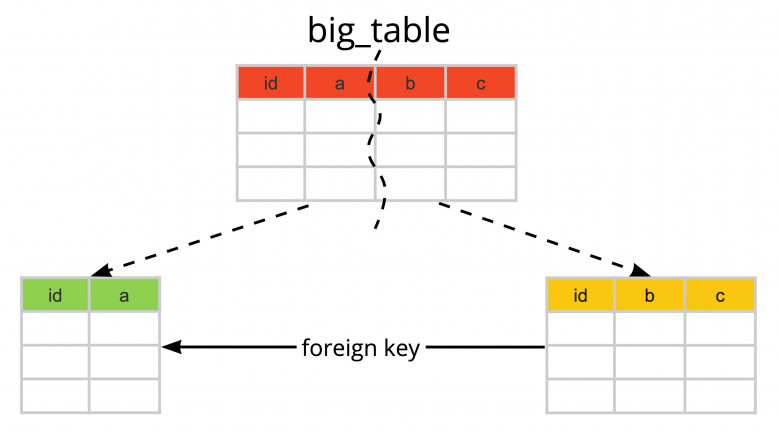
Наконец-то пришло время взяться за то, что я давно планировал — подробный гайд по асинхронной версии SQLAlchemy 2.0 в стиле ORM. В этой серии статей я подробно расскажу обо всех аспектах: от создания моделей и установления связей между ними до миграций с Alembic и взаимодействия с данными в базе. Мы будем шаг за шагом разбирать ключевые моменты работы с асинхронной базой данных, что позволит вам глубже понять SQLAlchemy и применить эти знания на практике.
Для начала, давайте разберёмся, что такое SQLAlchemy и почему каждый разработчик, работающий с реляционными базами данных (такими как SQLite, PostgreSQL, MySQL и т. д.), должен знать о ней. После этого — настройка. Мы будем работать с PostgreSQL, но не переживайте: код, который мы напишем, универсален для всех реляционных баз данных. Мы начнем с базовой настройки SQLAlchemy для асинхронного взаимодействия, а затем перейдём к созданию таблиц в современном декларативном стиле.