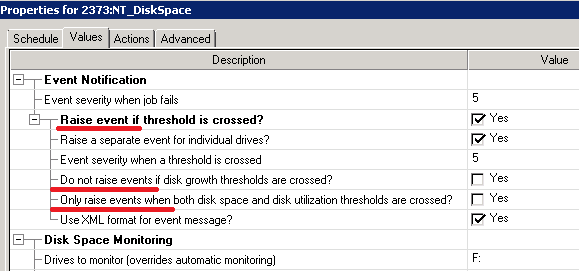
Извлечение текста — одна из популярных задач обработки PDF документов. Вам потребуется извлечь текст из PDF, чтобы:
- проиндексировать документ для полнотекстового поиска
- распарсить некоторые данные (например, названия и цены товаров в прайс-листе)
- выделить, удалить или заменить некоторое слово или фразу
Извлечь текст вручную можно так: откройте документ в любом PDF просмотрщике, выделите и скопируйте текст. В большинстве документов это сработает. Такие документы называются "доступные для поиска PDF" или "searchable PDF". Текст в них выводится с помощью специальных PDF операторов, а связанные объекты шрифтов содержат правильную информация о соответствии глифов значениям Unicode.
Многие PDF библиотеки умеют извлекать текст из доступных для поиска PDF.
Однако, часто встречаются и недоступные для поиска PDF ("non-searchable PDF") документы. В них текст обычно выводится как растровое изображение. Типичный пример — сканированный PDF документ. Также текст в недоступных для поиска PDF может выводиться векторными путями без использования шрифтов и специальных PDF операторов.
Для извлечения текста из недоступных для поиска PDF выполняйте оптическое распознавание текста (OCR). Оптическое распознавание не гарантирует правильного извлечения текста в 100% случаев. Результат зависит от качества документа и алгоритма распознавания. Также OCR существенно медленней, чем извлечение текста из доступных для поиска PDF.
Посмотрим, как выполнить оптическое распознавание и извлечь текст из PDF документов в программе для платформы .NET.